


Tom McCoy
@rtommccoy.bsky.social
Assistant professor at Yale Linguistics. Studying computational linguistics, cognitive science, and AI. He/him.
🤖 🧠 NEW BLOG POST 🧠 🤖
What skills do you need to be a successful researcher?
The list seems long: collaborating, writing, presenting, reviewing, etc
But I argue that many of these skills can be unified under a single overarching ability: theory of mind
rtmccoy.com/posts/theory...
What skills do you need to be a successful researcher?
The list seems long: collaborating, writing, presenting, reviewing, etc
But I argue that many of these skills can be unified under a single overarching ability: theory of mind
rtmccoy.com/posts/theory...

September 30, 2025 at 3:14 PM
🤖 🧠 NEW BLOG POST 🧠 🤖
What skills do you need to be a successful researcher?
The list seems long: collaborating, writing, presenting, reviewing, etc
But I argue that many of these skills can be unified under a single overarching ability: theory of mind
rtmccoy.com/posts/theory...
What skills do you need to be a successful researcher?
The list seems long: collaborating, writing, presenting, reviewing, etc
But I argue that many of these skills can be unified under a single overarching ability: theory of mind
rtmccoy.com/posts/theory...
A linguistic note about David Copperfield and Demon Copperhead 🧵
[very minor spoilers for both]
1/n
[very minor spoilers for both]
1/n

August 24, 2025 at 4:57 PM
A linguistic note about David Copperfield and Demon Copperhead 🧵
[very minor spoilers for both]
1/n
[very minor spoilers for both]
1/n
🤖 🧠 NEW PAPER ON COGSCI & AI 🧠 🤖
Recent neural networks capture properties long thought to require symbols: compositionality, productivity, rapid learning
So what role should symbols play in theories of the mind? For our answer...read on!
Paper: arxiv.org/abs/2508.05776
1/n
Recent neural networks capture properties long thought to require symbols: compositionality, productivity, rapid learning
So what role should symbols play in theories of the mind? For our answer...read on!
Paper: arxiv.org/abs/2508.05776
1/n

August 15, 2025 at 4:27 PM
🤖 🧠 NEW PAPER ON COGSCI & AI 🧠 🤖
Recent neural networks capture properties long thought to require symbols: compositionality, productivity, rapid learning
So what role should symbols play in theories of the mind? For our answer...read on!
Paper: arxiv.org/abs/2508.05776
1/n
Recent neural networks capture properties long thought to require symbols: compositionality, productivity, rapid learning
So what role should symbols play in theories of the mind? For our answer...read on!
Paper: arxiv.org/abs/2508.05776
1/n
According to Jane Austen, linguists are extraordinarily cold-hearted.
(Though at least we're not as bad as mathematicians!)
(Though at least we're not as bad as mathematicians!)

August 3, 2025 at 4:10 PM
According to Jane Austen, linguists are extraordinarily cold-hearted.
(Though at least we're not as bad as mathematicians!)
(Though at least we're not as bad as mathematicians!)
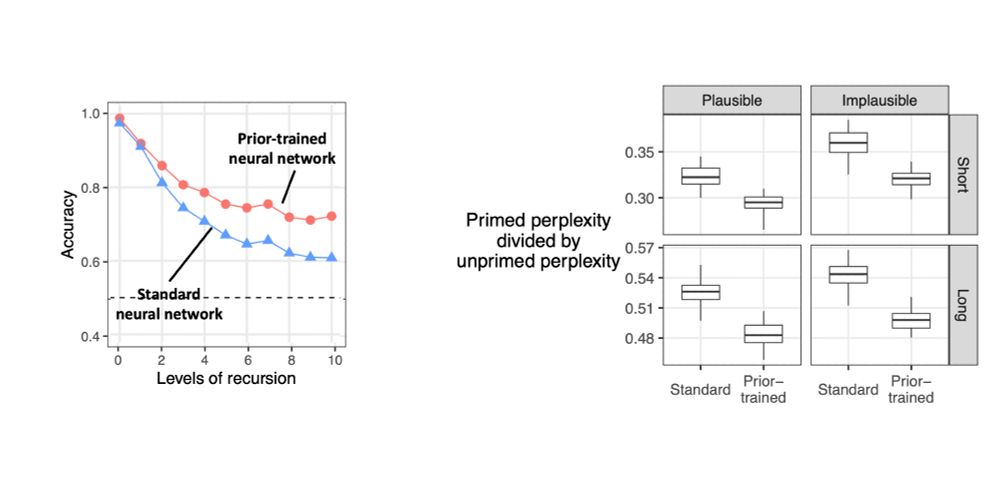
More dramatically, it substantially outperforms the standard neural network at learning recursion (left) and priming (right; a lower value on the y-axis shows a greater degree of priming).
13/n
13/n
May 20, 2025 at 7:16 PM
More dramatically, it substantially outperforms the standard neural network at learning recursion (left) and priming (right; a lower value on the y-axis shows a greater degree of priming).
13/n
13/n
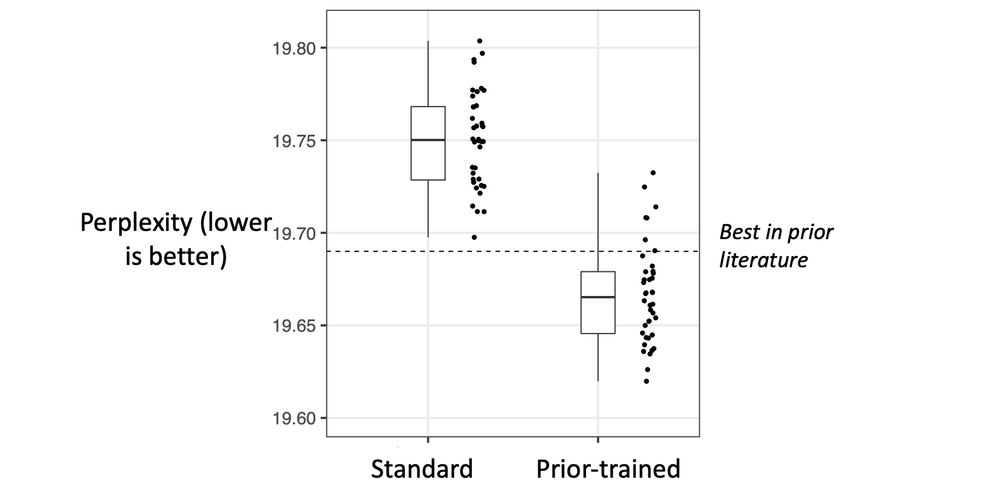
Here, its perplexity is slightly better (i.e., lower) than that of a standard neural network.
12/n
12/n
May 20, 2025 at 7:15 PM
Here, its perplexity is slightly better (i.e., lower) than that of a standard neural network.
12/n
12/n
Even though it is a neural network, the prior-trained model can learn formal languages from small numbers of examples - far outperforming a standard neural network, and matching a Bayesian model at a fraction of the computational cost.
10/n
10/n

May 20, 2025 at 7:14 PM
Even though it is a neural network, the prior-trained model can learn formal languages from small numbers of examples - far outperforming a standard neural network, and matching a Bayesian model at a fraction of the computational cost.
10/n
10/n
Inspired by a model from Yang & @spiantado.bsky.social , the prior that we use is a distribution over formal languages (a formal language = a set of strings defined by an abstract rule). We have a neural network meta-learn by observing many formal languages sampled from this prior
8/n
8/n

May 20, 2025 at 7:13 PM
Inspired by a model from Yang & @spiantado.bsky.social , the prior that we use is a distribution over formal languages (a formal language = a set of strings defined by an abstract rule). We have a neural network meta-learn by observing many formal languages sampled from this prior
8/n
8/n
In MAML, a model is exposed to many tasks. After each task, the model's weights are adjusted so that, if it were taught the same task again, it would perform better. As MAML proceeds, the model converges to a state from which it can learn any task in the distribution.
7/n
7/n
May 20, 2025 at 7:12 PM
In MAML, a model is exposed to many tasks. After each task, the model's weights are adjusted so that, if it were taught the same task again, it would perform better. As MAML proceeds, the model converges to a state from which it can learn any task in the distribution.
7/n
7/n
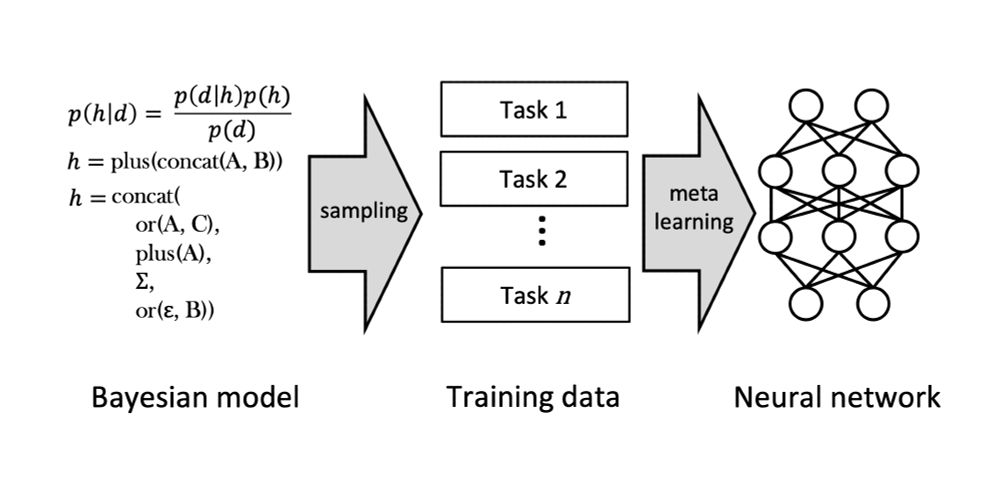
Our approach (inductive bias distillation) has 3 steps:
1. Use a Bayesian model to define an inductive bias (a prior)
2. Sample learning tasks from the Bayesian model
3. Have a neural network meta-learn from these sampled tasks, to give it the Bayesian model's prior
5/n
1. Use a Bayesian model to define an inductive bias (a prior)
2. Sample learning tasks from the Bayesian model
3. Have a neural network meta-learn from these sampled tasks, to give it the Bayesian model's prior
5/n
May 20, 2025 at 7:07 PM
Our approach (inductive bias distillation) has 3 steps:
1. Use a Bayesian model to define an inductive bias (a prior)
2. Sample learning tasks from the Bayesian model
3. Have a neural network meta-learn from these sampled tasks, to give it the Bayesian model's prior
5/n
1. Use a Bayesian model to define an inductive bias (a prior)
2. Sample learning tasks from the Bayesian model
3. Have a neural network meta-learn from these sampled tasks, to give it the Bayesian model's prior
5/n
Neural networks have flexible representations that allow them to handle noisy natural data - as evidenced by the success of large language models. However, they notoriously require huge numbers of examples.
3/n
3/n

May 20, 2025 at 7:06 PM
Neural networks have flexible representations that allow them to handle noisy natural data - as evidenced by the success of large language models. However, they notoriously require huge numbers of examples.
3/n
3/n
Bayesian models can learn from few examples because they have strong inductive biases - factors that guide generalization. But the costs of inference and the difficulty of specifying generative models can make naturalistic data a challenge.
2/n
2/n

May 20, 2025 at 7:05 PM
Bayesian models can learn from few examples because they have strong inductive biases - factors that guide generalization. But the costs of inference and the difficulty of specifying generative models can make naturalistic data a challenge.
2/n
2/n
🤖🧠 Paper out in Nature Communications! 🧠🤖
Bayesian models can learn rapidly. Neural networks can handle messy, naturalistic data. How can we combine these strengths?
Our answer: Use meta-learning to distill Bayesian priors into a neural network!
www.nature.com/articles/s41...
1/n
Bayesian models can learn rapidly. Neural networks can handle messy, naturalistic data. How can we combine these strengths?
Our answer: Use meta-learning to distill Bayesian priors into a neural network!
www.nature.com/articles/s41...
1/n

May 20, 2025 at 7:04 PM
🤖🧠 Paper out in Nature Communications! 🧠🤖
Bayesian models can learn rapidly. Neural networks can handle messy, naturalistic data. How can we combine these strengths?
Our answer: Use meta-learning to distill Bayesian priors into a neural network!
www.nature.com/articles/s41...
1/n
Bayesian models can learn rapidly. Neural networks can handle messy, naturalistic data. How can we combine these strengths?
Our answer: Use meta-learning to distill Bayesian priors into a neural network!
www.nature.com/articles/s41...
1/n
I constructed today's NYT crossword!
This one has some personal connections, described at the WordPlay article by @samcorbin.bsky.social (contains spoilers): www.nytimes.com/2025/05/06/c...
I hope you enjoy!
This one has some personal connections, described at the WordPlay article by @samcorbin.bsky.social (contains spoilers): www.nytimes.com/2025/05/06/c...
I hope you enjoy!

May 7, 2025 at 5:32 PM
I constructed today's NYT crossword!
This one has some personal connections, described at the WordPlay article by @samcorbin.bsky.social (contains spoilers): www.nytimes.com/2025/05/06/c...
I hope you enjoy!
This one has some personal connections, described at the WordPlay article by @samcorbin.bsky.social (contains spoilers): www.nytimes.com/2025/05/06/c...
I hope you enjoy!
Made a new assignment for a class on Computational Psycholinguistics:
- I trained a Transformer language model on sentences sampled from a PCFG
- The students' task: Given the Transformer, try to infer the PCFG (w/ a leaderboard for who got closest)
Would recommend!
1/n
- I trained a Transformer language model on sentences sampled from a PCFG
- The students' task: Given the Transformer, try to infer the PCFG (w/ a leaderboard for who got closest)
Would recommend!
1/n

May 2, 2025 at 3:30 PM
Made a new assignment for a class on Computational Psycholinguistics:
- I trained a Transformer language model on sentences sampled from a PCFG
- The students' task: Given the Transformer, try to infer the PCFG (w/ a leaderboard for who got closest)
Would recommend!
1/n
- I trained a Transformer language model on sentences sampled from a PCFG
- The students' task: Given the Transformer, try to infer the PCFG (w/ a leaderboard for who got closest)
Would recommend!
1/n
I added a new assignment to my Computational Linguistics class last semester:
- Choose a linguistic phenomenon in a language other than English
- Give a 3-minute presentation about that phenomenon & how it would pose a challenge for computational models
Would recommend!
1/n
- Choose a linguistic phenomenon in a language other than English
- Give a 3-minute presentation about that phenomenon & how it would pose a challenge for computational models
Would recommend!
1/n

January 28, 2025 at 8:28 PM
I added a new assignment to my Computational Linguistics class last semester:
- Choose a linguistic phenomenon in a language other than English
- Give a 3-minute presentation about that phenomenon & how it would pose a challenge for computational models
Would recommend!
1/n
- Choose a linguistic phenomenon in a language other than English
- Give a 3-minute presentation about that phenomenon & how it would pose a challenge for computational models
Would recommend!
1/n
Like previous models, o1-preview shows clear effects of output probability (performing better when the correct answer is a high-probability string).
Interestingly, the effects don’t just show up in accuracy (top) but also in how many tokens o1 consumes to perform the task (bottom)!
3/4
Interestingly, the effects don’t just show up in accuracy (top) but also in how many tokens o1 consumes to perform the task (bottom)!
3/4

January 20, 2025 at 7:31 PM
Like previous models, o1-preview shows clear effects of output probability (performing better when the correct answer is a high-probability string).
Interestingly, the effects don’t just show up in accuracy (top) but also in how many tokens o1 consumes to perform the task (bottom)!
3/4
Interestingly, the effects don’t just show up in accuracy (top) but also in how many tokens o1 consumes to perform the task (bottom)!
3/4
o1 shows especially big improvements over previous models when performing rare versions of tasks (left plot). But, when the tasks are hard enough, it still does better on common task variants than rare ones (right two plots)
2/4
2/4

January 20, 2025 at 7:29 PM
o1 shows especially big improvements over previous models when performing rare versions of tasks (left plot). But, when the tasks are hard enough, it still does better on common task variants than rare ones (right two plots)
2/4
2/4
🔥While LLM reasoning is on people's minds...
Here's a shameless plug for our work comparing o1 to previous LLMs (extending "Embers of Autoregression"): arxiv.org/abs/2410.01792
- o1 shows big improvements over GPT-4
- But qualitatively it is still sensitive to probability
1/4
Here's a shameless plug for our work comparing o1 to previous LLMs (extending "Embers of Autoregression"): arxiv.org/abs/2410.01792
- o1 shows big improvements over GPT-4
- But qualitatively it is still sensitive to probability
1/4

January 20, 2025 at 7:28 PM
🔥While LLM reasoning is on people's minds...
Here's a shameless plug for our work comparing o1 to previous LLMs (extending "Embers of Autoregression"): arxiv.org/abs/2410.01792
- o1 shows big improvements over GPT-4
- But qualitatively it is still sensitive to probability
1/4
Here's a shameless plug for our work comparing o1 to previous LLMs (extending "Embers of Autoregression"): arxiv.org/abs/2410.01792
- o1 shows big improvements over GPT-4
- But qualitatively it is still sensitive to probability
1/4

Excited to be visiting the Simons Institute tomorrow for a debate with Sébastien Bubeck - billed as the Sparks/Embers debate! 🔥🤖🧠
Topic: Will scaling current LLMs be sufficient to resolve major open math conjectures?
Topic: Will scaling current LLMs be sufficient to resolve major open math conjectures?

December 4, 2024 at 9:19 PM
Excited to be visiting the Simons Institute tomorrow for a debate with Sébastien Bubeck - billed as the Sparks/Embers debate! 🔥🤖🧠
Topic: Will scaling current LLMs be sufficient to resolve major open math conjectures?
Topic: Will scaling current LLMs be sufficient to resolve major open math conjectures?
🤖🧠 I'll be considering applications for postdocs & PhD students to start at Yale in Fall 2025!
If you are interested in the intersection of linguistics, cognitive science, and AI, I encourage you to apply!
Postdoc link: rtmccoy.com/prospective_...
PhD link: rtmccoy.com/prospective_...
If you are interested in the intersection of linguistics, cognitive science, and AI, I encourage you to apply!
Postdoc link: rtmccoy.com/prospective_...
PhD link: rtmccoy.com/prospective_...
November 14, 2024 at 9:39 PM
🤖🧠 I'll be considering applications for postdocs & PhD students to start at Yale in Fall 2025!
If you are interested in the intersection of linguistics, cognitive science, and AI, I encourage you to apply!
Postdoc link: rtmccoy.com/prospective_...
PhD link: rtmccoy.com/prospective_...
If you are interested in the intersection of linguistics, cognitive science, and AI, I encourage you to apply!
Postdoc link: rtmccoy.com/prospective_...
PhD link: rtmccoy.com/prospective_...
"Worldpay" - anagram of "Wordplay"!

November 10, 2024 at 1:51 AM
"Worldpay" - anagram of "Wordplay"!