



Romane Cecchi
@romanececchi.bsky.social
Postdoc in the Human Reinforcement Learning team led by @stepalminteri.bsky.social at École Normale Supérieure (ENS) in Paris ✨
7/9 ⏱️ When does attention matter?
🏆 Best fit? The stimulus-only model – consistent across experiments.
➕ Complemented by fine-grained gaze analysis:
👉 Value computation relies mainly on fixations during stimulus presentation, with minimal contribution from outcome-related fixations.
🏆 Best fit? The stimulus-only model – consistent across experiments.
➕ Complemented by fine-grained gaze analysis:
👉 Value computation relies mainly on fixations during stimulus presentation, with minimal contribution from outcome-related fixations.

April 22, 2025 at 4:57 PM
7/9 ⏱️ When does attention matter?
🏆 Best fit? The stimulus-only model – consistent across experiments.
➕ Complemented by fine-grained gaze analysis:
👉 Value computation relies mainly on fixations during stimulus presentation, with minimal contribution from outcome-related fixations.
🏆 Best fit? The stimulus-only model – consistent across experiments.
➕ Complemented by fine-grained gaze analysis:
👉 Value computation relies mainly on fixations during stimulus presentation, with minimal contribution from outcome-related fixations.
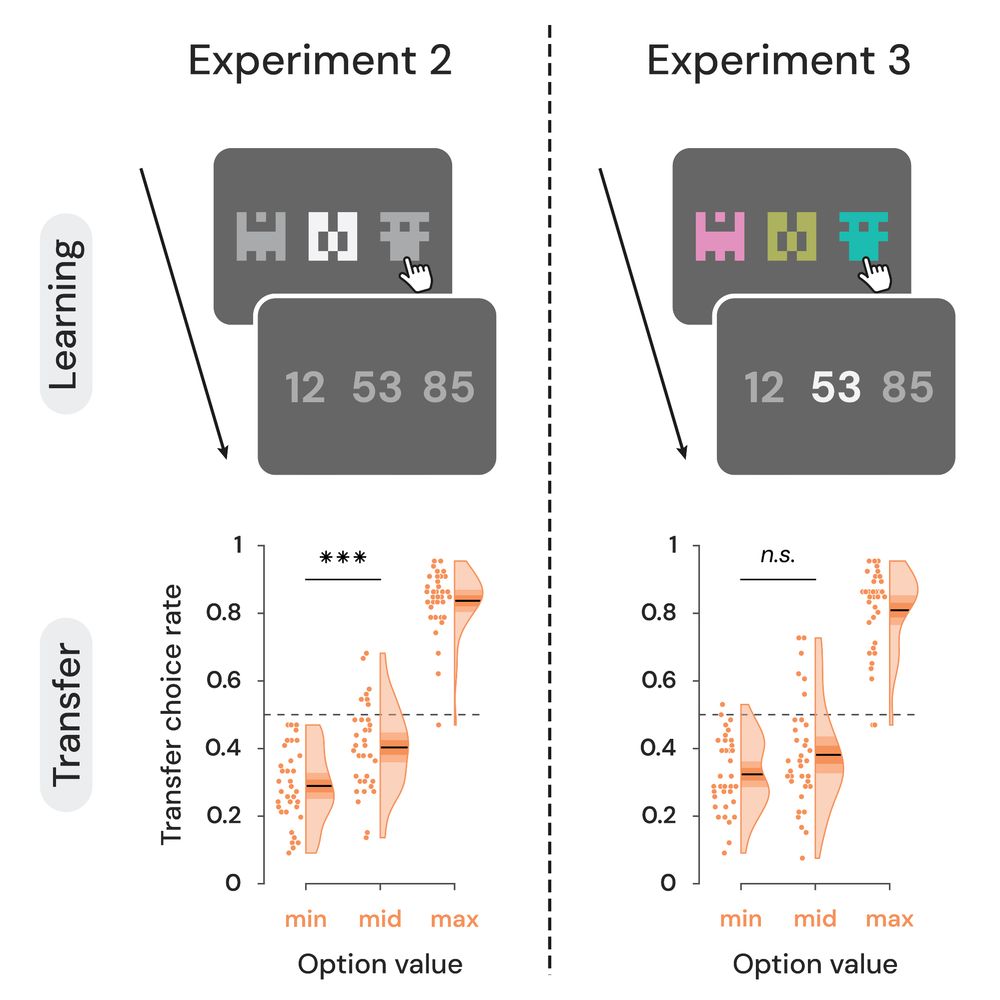
5/9 ⬆️ Exp 2 & 3: Bottom-up manipulation
We used saliency to guide gaze to the mid-value option:
• Exp 2: Salient stimulus → higher valuation in transfer
• Exp 3: Salient outcome → no significant effect
👉 Only attention to stimuli during learning influenced value formation
We used saliency to guide gaze to the mid-value option:
• Exp 2: Salient stimulus → higher valuation in transfer
• Exp 3: Salient outcome → no significant effect
👉 Only attention to stimuli during learning influenced value formation
April 22, 2025 at 4:57 PM
5/9 ⬆️ Exp 2 & 3: Bottom-up manipulation
We used saliency to guide gaze to the mid-value option:
• Exp 2: Salient stimulus → higher valuation in transfer
• Exp 3: Salient outcome → no significant effect
👉 Only attention to stimuli during learning influenced value formation
We used saliency to guide gaze to the mid-value option:
• Exp 2: Salient stimulus → higher valuation in transfer
• Exp 3: Salient outcome → no significant effect
👉 Only attention to stimuli during learning influenced value formation
4/9 ⬇️ Exp 1: Top-down manipulation
We made the high-value option unavailable on some trials – forcing attention to the mid-value one.
Result: participants looked more at the mid-value option – and later valued it more.
👉 Attention during learning altered subjective valuation.
We made the high-value option unavailable on some trials – forcing attention to the mid-value one.
Result: participants looked more at the mid-value option – and later valued it more.
👉 Attention during learning altered subjective valuation.

April 22, 2025 at 4:57 PM
4/9 ⬇️ Exp 1: Top-down manipulation
We made the high-value option unavailable on some trials – forcing attention to the mid-value one.
Result: participants looked more at the mid-value option – and later valued it more.
👉 Attention during learning altered subjective valuation.
We made the high-value option unavailable on some trials – forcing attention to the mid-value one.
Result: participants looked more at the mid-value option – and later valued it more.
👉 Attention during learning altered subjective valuation.
3/9 Design
We ran 3️⃣ eye-tracking RL experiments, combining:
• A 3-option learning phase with full feedback
• A transfer test probing generalization & subjective valuation
Crucially, we manipulated attention via:
• Top-down control (Exp 1)
• Bottom-up saliency (Exp 2 & 3)
We ran 3️⃣ eye-tracking RL experiments, combining:
• A 3-option learning phase with full feedback
• A transfer test probing generalization & subjective valuation
Crucially, we manipulated attention via:
• Top-down control (Exp 1)
• Bottom-up saliency (Exp 2 & 3)

April 22, 2025 at 4:57 PM
3/9 Design
We ran 3️⃣ eye-tracking RL experiments, combining:
• A 3-option learning phase with full feedback
• A transfer test probing generalization & subjective valuation
Crucially, we manipulated attention via:
• Top-down control (Exp 1)
• Bottom-up saliency (Exp 2 & 3)
We ran 3️⃣ eye-tracking RL experiments, combining:
• A 3-option learning phase with full feedback
• A transfer test probing generalization & subjective valuation
Crucially, we manipulated attention via:
• Top-down control (Exp 1)
• Bottom-up saliency (Exp 2 & 3)
1/9 🎨 Background
When choosing, people don’t evaluate options in isolation – they normalize values to context.
This holds in RL... but in three-option settings, people undervalue the mid-value option – something prior models fail to explain (see @sophiebavard.bsky.social).
❓Why the distortion?
When choosing, people don’t evaluate options in isolation – they normalize values to context.
This holds in RL... but in three-option settings, people undervalue the mid-value option – something prior models fail to explain (see @sophiebavard.bsky.social).
❓Why the distortion?

April 22, 2025 at 4:57 PM
1/9 🎨 Background
When choosing, people don’t evaluate options in isolation – they normalize values to context.
This holds in RL... but in three-option settings, people undervalue the mid-value option – something prior models fail to explain (see @sophiebavard.bsky.social).
❓Why the distortion?
When choosing, people don’t evaluate options in isolation – they normalize values to context.
This holds in RL... but in three-option settings, people undervalue the mid-value option – something prior models fail to explain (see @sophiebavard.bsky.social).
❓Why the distortion?