




Roger Creus Castanyer
@roger-creus.bsky.social
Maximizing the unexpected return.
PhD student @mila-quebec.bsky.social
PhD student @mila-quebec.bsky.social
We also combine our methods with recent scaling strategies like Simba , and still see additional improvements in performance and stability 📊

June 23, 2025 at 12:58 PM
We also combine our methods with recent scaling strategies like Simba , and still see additional improvements in performance and stability 📊
🔁 Back to our artificial non-stationary supervised setting:
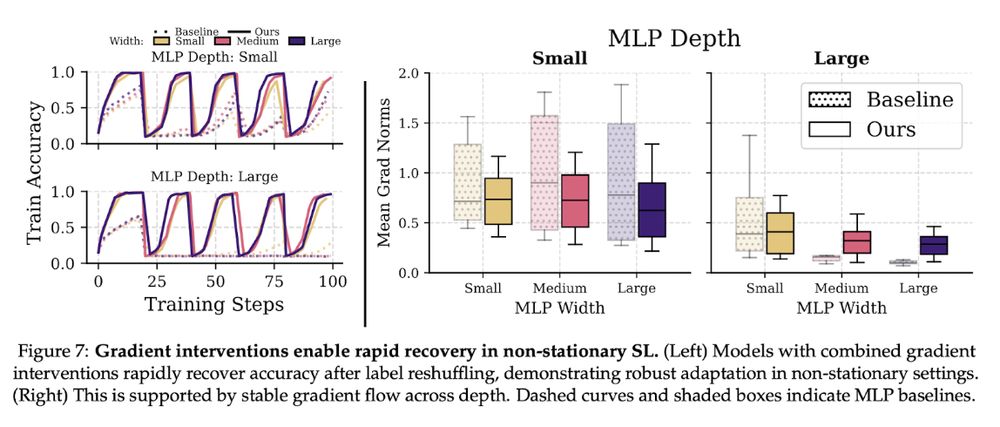
With both interventions, networks now show near-perfect plasticity. They can continually fit changing data across network scales. No collapse 💪
With both interventions, networks now show near-perfect plasticity. They can continually fit changing data across network scales. No collapse 💪
June 23, 2025 at 12:58 PM
🔁 Back to our artificial non-stationary supervised setting:
With both interventions, networks now show near-perfect plasticity. They can continually fit changing data across network scales. No collapse 💪
With both interventions, networks now show near-perfect plasticity. They can continually fit changing data across network scales. No collapse 💪
Combining both ideas, we see massive gains on the ALE (Atari)! 🎮🔥
We benchmark against PQN and PPO, and the improvements are remarkable, both in terms of performance and scalability.
We benchmark against PQN and PPO, and the improvements are remarkable, both in terms of performance and scalability.


June 23, 2025 at 12:58 PM
Combining both ideas, we see massive gains on the ALE (Atari)! 🎮🔥
We benchmark against PQN and PPO, and the improvements are remarkable, both in terms of performance and scalability.
We benchmark against PQN and PPO, and the improvements are remarkable, both in terms of performance and scalability.
💡 Our second intervention: better optimizers
Second-order estimators capture curvature, providing more stable updates than first-order methods
Our ablations show the Kron optimizer shines in deep RL, helping agents adapt as learning evolves ✨
Second-order estimators capture curvature, providing more stable updates than first-order methods
Our ablations show the Kron optimizer shines in deep RL, helping agents adapt as learning evolves ✨

June 23, 2025 at 12:58 PM
💡 Our second intervention: better optimizers
Second-order estimators capture curvature, providing more stable updates than first-order methods
Our ablations show the Kron optimizer shines in deep RL, helping agents adapt as learning evolves ✨
Second-order estimators capture curvature, providing more stable updates than first-order methods
Our ablations show the Kron optimizer shines in deep RL, helping agents adapt as learning evolves ✨
💡 Our first intervention: better architectures for stable gradients.
Residual connections create shortcuts that preserve gradients and avoid vanishing ⚡️
We extend this with MultiSkip: broadcasting features to all fully connected layers, ensuring direct gradient flow at scale
Residual connections create shortcuts that preserve gradients and avoid vanishing ⚡️
We extend this with MultiSkip: broadcasting features to all fully connected layers, ensuring direct gradient flow at scale

June 23, 2025 at 12:58 PM
💡 Our first intervention: better architectures for stable gradients.
Residual connections create shortcuts that preserve gradients and avoid vanishing ⚡️
We extend this with MultiSkip: broadcasting features to all fully connected layers, ensuring direct gradient flow at scale
Residual connections create shortcuts that preserve gradients and avoid vanishing ⚡️
We extend this with MultiSkip: broadcasting features to all fully connected layers, ensuring direct gradient flow at scale
So what's going on?
Gradients are at the heart of this instability.
We relate vanishing gradients to classic RL diagnostics:
⚫ Dead neurons
⚫ Representation collapse
⚫ Loss landscape instability (from bootstrapping)
Gradients are at the heart of this instability.
We relate vanishing gradients to classic RL diagnostics:
⚫ Dead neurons
⚫ Representation collapse
⚫ Loss landscape instability (from bootstrapping)

June 23, 2025 at 12:58 PM
So what's going on?
Gradients are at the heart of this instability.
We relate vanishing gradients to classic RL diagnostics:
⚫ Dead neurons
⚫ Representation collapse
⚫ Loss landscape instability (from bootstrapping)
Gradients are at the heart of this instability.
We relate vanishing gradients to classic RL diagnostics:
⚫ Dead neurons
⚫ Representation collapse
⚫ Loss landscape instability (from bootstrapping)
We test the same architectures in supervised learning: gradients propagate well and performance scales ✅
But in RL, performance collapses due to non-stationarity!
We simulate this by shuffling labels periodically. The result? Gradients degrade, and bigger networks collapse! 🚫
But in RL, performance collapses due to non-stationarity!
We simulate this by shuffling labels periodically. The result? Gradients degrade, and bigger networks collapse! 🚫

June 23, 2025 at 12:58 PM
We test the same architectures in supervised learning: gradients propagate well and performance scales ✅
But in RL, performance collapses due to non-stationarity!
We simulate this by shuffling labels periodically. The result? Gradients degrade, and bigger networks collapse! 🚫
But in RL, performance collapses due to non-stationarity!
We simulate this by shuffling labels periodically. The result? Gradients degrade, and bigger networks collapse! 🚫
Scaling up networks in deep RL is tricky: do it naively, and performance collapses 😵💫
Why? Increasing depth and width leads to severe vanishing gradients, causing unstable learning ⚠️
We diagnose this issue across several algorithms: DQN, Rainbow, PQN, PPO, SAC, and DDPG.
Why? Increasing depth and width leads to severe vanishing gradients, causing unstable learning ⚠️
We diagnose this issue across several algorithms: DQN, Rainbow, PQN, PPO, SAC, and DDPG.

June 23, 2025 at 12:58 PM
Scaling up networks in deep RL is tricky: do it naively, and performance collapses 😵💫
Why? Increasing depth and width leads to severe vanishing gradients, causing unstable learning ⚠️
We diagnose this issue across several algorithms: DQN, Rainbow, PQN, PPO, SAC, and DDPG.
Why? Increasing depth and width leads to severe vanishing gradients, causing unstable learning ⚠️
We diagnose this issue across several algorithms: DQN, Rainbow, PQN, PPO, SAC, and DDPG.
🚨 Excited to share our new work: "Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning"! 📈
We propose gradient interventions that enable stable, scalable learning, unlocking significant performance gains across agents and environments!
Details below 👇
We propose gradient interventions that enable stable, scalable learning, unlocking significant performance gains across agents and environments!
Details below 👇

June 23, 2025 at 12:58 PM
🚨 Excited to share our new work: "Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning"! 📈
We propose gradient interventions that enable stable, scalable learning, unlocking significant performance gains across agents and environments!
Details below 👇
We propose gradient interventions that enable stable, scalable learning, unlocking significant performance gains across agents and environments!
Details below 👇