



@robertmgower.bsky.social
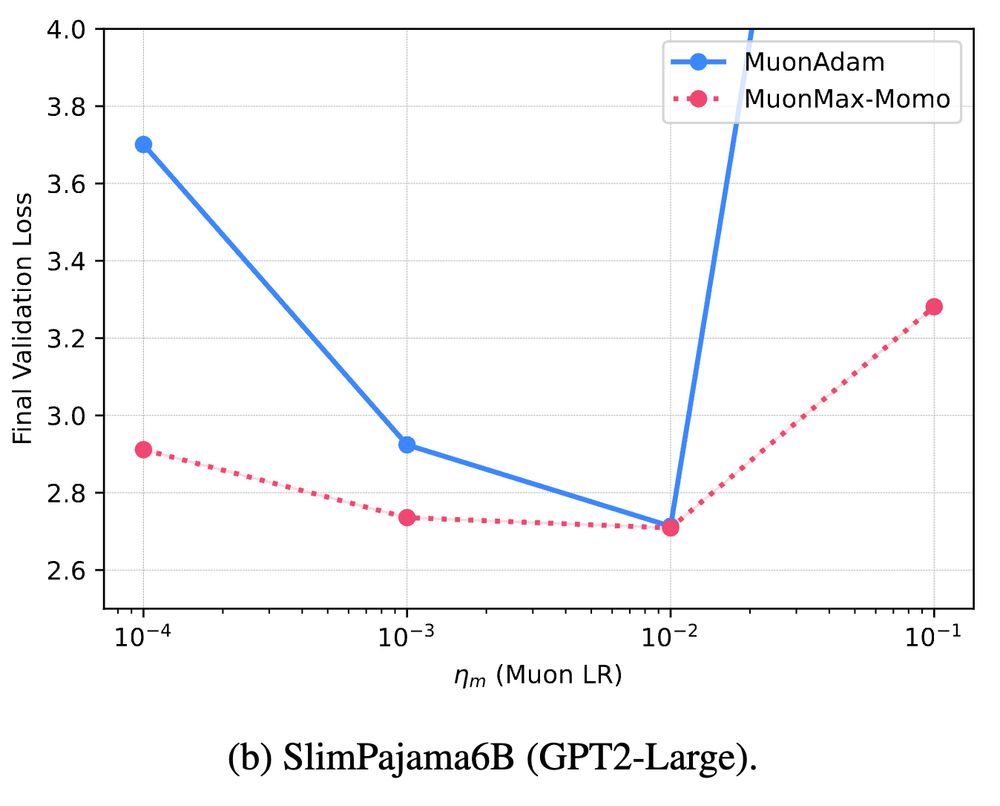
When you also throw truncation in the mix, that gives a lot of possible variants of Muon. We tried out many, here are some of the winners (including Scion)

October 28, 2025 at 2:00 PM
When you also throw truncation in the mix, that gives a lot of possible variants of Muon. We tried out many, here are some of the winners (including Scion)
Replacing the linear model used in steepest descent with a truncated linear model, gives us a more robust version of both gradient descent (regularized) and LMO (constrained). We derive these truncated updates for any non-Euclidean norm. The combination of truncation+momentum is called momo.

October 28, 2025 at 2:00 PM
Replacing the linear model used in steepest descent with a truncated linear model, gives us a more robust version of both gradient descent (regularized) and LMO (constrained). We derive these truncated updates for any non-Euclidean norm. The combination of truncation+momentum is called momo.
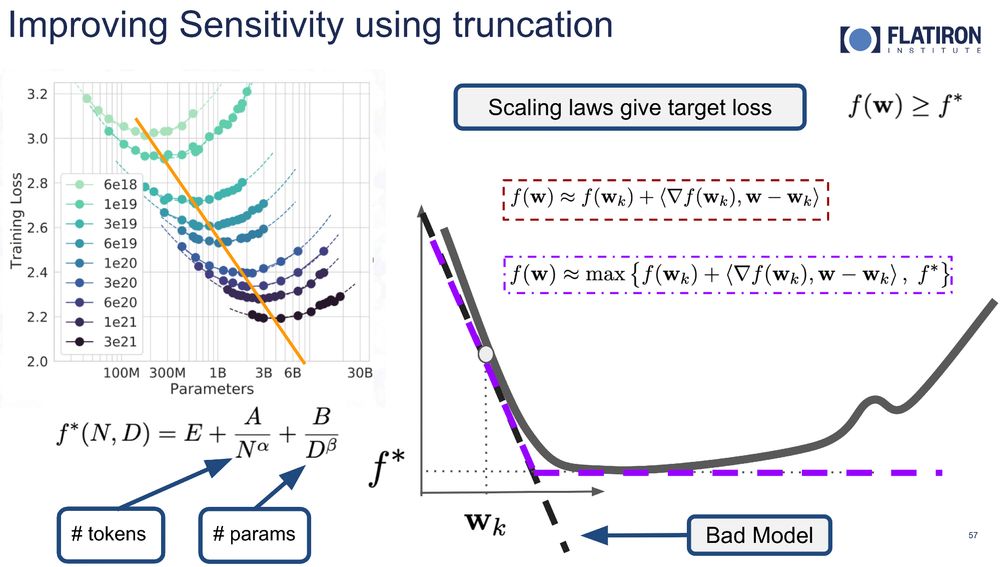
How did we improve the sensitivity to learning rates? Since we formalized MuonAdam/MuonMax as steepest descent methods, we can import tricks such as truncation. Truncation changes the steepest descent model, by making use of a known lower bound on the loss. Scaling laws give a lower bound on LLMs
October 28, 2025 at 2:00 PM
How did we improve the sensitivity to learning rates? Since we formalized MuonAdam/MuonMax as steepest descent methods, we can import tricks such as truncation. Truncation changes the steepest descent model, by making use of a known lower bound on the loss. Scaling laws give a lower bound on LLMs
Another method called MuonMax we came up with that also worked consistently well, is the regularized version of MuonAdam. This is different than what is used in NanoGPT, and requires some tricks for a good implementation (see arxiv.org/pdf/2510.09827).

October 28, 2025 at 2:00 PM
Another method called MuonMax we came up with that also worked consistently well, is the regularized version of MuonAdam. This is different than what is used in NanoGPT, and requires some tricks for a good implementation (see arxiv.org/pdf/2510.09827).
One method that consistently worked well was the NanoGPT variant of Muon, which we call MuonAdam (it uses Adam as well). You can formalize this method as a LMO (constrained steepest descent) over the whole network:

October 28, 2025 at 2:00 PM
One method that consistently worked well was the NanoGPT variant of Muon, which we call MuonAdam (it uses Adam as well). You can formalize this method as a LMO (constrained steepest descent) over the whole network:
We tried 18 variations of Muon by choosing different norms over the neural network, to use the Gradient descent (regularized) or LMO (constrained), and to use Adam or SignGD. Too many variants to talk about here! But let me tell you 2 versions that worked really well arxiv.org/pdf/2510.09827

October 28, 2025 at 2:00 PM
We tried 18 variations of Muon by choosing different norms over the neural network, to use the Gradient descent (regularized) or LMO (constrained), and to use Adam or SignGD. Too many variants to talk about here! But let me tell you 2 versions that worked really well arxiv.org/pdf/2510.09827
Neural networks have many layers, some with matrix parameters (good for Muon), and some with vector parameters (need Adam or signGD). To define a method on the whole Neural network, we need a norm over the whole neural network. Now here is where many design choices for Muon have not been explored..

October 28, 2025 at 2:00 PM
Neural networks have many layers, some with matrix parameters (good for Muon), and some with vector parameters (need Adam or signGD). To define a method on the whole Neural network, we need a norm over the whole neural network. Now here is where many design choices for Muon have not been explored..
First, what is Muon? Muon is spectral descent with momentum, and a GPU efficient method for computing the polar factor. See Jordan blog post for an intro kellerjordan.github.io/posts/muon/. But in essence, Muon is a method specialized to the linear layers. What about all the other layers?

October 28, 2025 at 2:00 PM
First, what is Muon? Muon is spectral descent with momentum, and a GPU efficient method for computing the polar factor. See Jordan blog post for an intro kellerjordan.github.io/posts/muon/. But in essence, Muon is a method specialized to the linear layers. What about all the other layers?
We've just finished some work on improving the sensitivity of Muon to the learning rate, and exploring a lot of design choices. If you want to see how we did this, follow me ....1/x
arxiv.org/pdf/2510.09827
arxiv.org/pdf/2510.09827
October 28, 2025 at 2:00 PM
We've just finished some work on improving the sensitivity of Muon to the learning rate, and exploring a lot of design choices. If you want to see how we did this, follow me ....1/x
arxiv.org/pdf/2510.09827
arxiv.org/pdf/2510.09827
Switching out the standard L2 regularization, we can put in a divergence. If we choose the generalized KL divergence, we get exponentiated gradient descent, which is the blue trajectory in gif. This is a much faster method, that bounces less.


April 24, 2025 at 5:46 PM
Switching out the standard L2 regularization, we can put in a divergence. If we choose the generalized KL divergence, we get exponentiated gradient descent, which is the blue trajectory in gif. This is a much faster method, that bounces less.
Projected gradient descent is the solution to this constrained problem. The issue with this approach is that no one told the regularization term that we only care about positive parameters! A better way would be to use a regularization term designed for this constraint...

April 24, 2025 at 5:46 PM
Projected gradient descent is the solution to this constrained problem. The issue with this approach is that no one told the regularization term that we only care about positive parameters! A better way would be to use a regularization term designed for this constraint...
Question on online learning theory. I needed a regret bound for online proximal point, where the loss is smooth. I've proven the below. I'm sure something like (1) (and maybe (2)) exist in the literature. But where? Who can I cite for these results? @neu-rips.bsky.social

April 16, 2025 at 2:38 PM
Question on online learning theory. I needed a regret bound for online proximal point, where the loss is smooth. I've proven the below. I'm sure something like (1) (and maybe (2)) exist in the literature. But where? Who can I cite for these results? @neu-rips.bsky.social