




So they integrated Riza to enable custom code execution in 2 products:
🔹Evals - So users can build custom scoring functions
🔹Agents - So users can freely fetch and manipulate data, invoke callbacks, and more
🔹Evals - So users can build custom scoring functions
🔹Agents - So users can freely fetch and manipulate data, invoke callbacks, and more

March 28, 2025 at 6:08 PM
So they integrated Riza to enable custom code execution in 2 products:
🔹Evals - So users can build custom scoring functions
🔹Agents - So users can freely fetch and manipulate data, invoke callbacks, and more
🔹Evals - So users can build custom scoring functions
🔹Agents - So users can freely fetch and manipulate data, invoke callbacks, and more

We chatted with PromptLayer to learn how they've enabled users to customize AI workflows and evals—with Riza. riza.io/customers/pr...

March 28, 2025 at 6:08 PM
We chatted with PromptLayer to learn how they've enabled users to customize AI workflows and evals—with Riza. riza.io/customers/pr...

Instead, here's how we solved it:
1️⃣ We fed sample HTML from the site to an LLM
2️⃣ We had the LLM write targeted extraction code
3️⃣ Riza executed that code securely
4️⃣ We got back clean, structured CSV data
1️⃣ We fed sample HTML from the site to an LLM
2️⃣ We had the LLM write targeted extraction code
3️⃣ Riza executed that code securely
4️⃣ We got back clean, structured CSV data
March 7, 2025 at 9:10 PM
Instead, here's how we solved it:
1️⃣ We fed sample HTML from the site to an LLM
2️⃣ We had the LLM write targeted extraction code
3️⃣ Riza executed that code securely
4️⃣ We got back clean, structured CSV data
1️⃣ We fed sample HTML from the site to an LLM
2️⃣ We had the LLM write targeted extraction code
3️⃣ Riza executed that code securely
4️⃣ We got back clean, structured CSV data
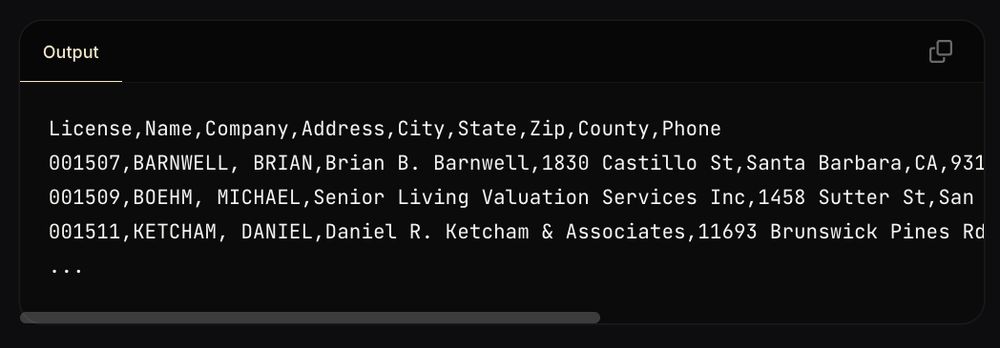
The California Bureau of Real Estate Appraisers provides a list of all current and recently-licensed appraisers (link below 👇).
13,000 appraisers are shown in batches of 300, with no bulk download option:
13,000 appraisers are shown in batches of 300, with no bulk download option:

March 7, 2025 at 9:10 PM
The California Bureau of Real Estate Appraisers provides a list of all current and recently-licensed appraisers (link below 👇).
13,000 appraisers are shown in batches of 300, with no bulk download option:
13,000 appraisers are shown in batches of 300, with no bulk download option:
A lot of commercially-useful data is stuck online: in government sites to enterprise portals.
LLMs can help you extract it, fast.
Let's see an example:
LLMs can help you extract it, fast.
Let's see an example:

March 7, 2025 at 9:10 PM
A lot of commercially-useful data is stuck online: in government sites to enterprise portals.
LLMs can help you extract it, fast.
Let's see an example:
LLMs can help you extract it, fast.
Let's see an example:

Have more data than data scientists? LLMs can help.
Here's a chart Anthropic's Claude generated using Riza that shows trends in San Francisco city employee salaries.
And you can repeat this infinitely over other data.
Here's how:
Here's a chart Anthropic's Claude generated using Riza that shows trends in San Francisco city employee salaries.
And you can repeat this infinitely over other data.
Here's how:

February 28, 2025 at 4:49 PM
Have more data than data scientists? LLMs can help.
Here's a chart Anthropic's Claude generated using Riza that shows trends in San Francisco city employee salaries.
And you can repeat this infinitely over other data.
Here's how:
Here's a chart Anthropic's Claude generated using Riza that shows trends in San Francisco city employee salaries.
And you can repeat this infinitely over other data.
Here's how:
6️⃣ Run the evaluation
Finally, you're ready to run the eval:
In our run, #Llama3 70b achieved a pass@1 of ~0.44. This means it solved 44% of HumanEval problems on the first try.
Finally, you're ready to run the eval:
In our run, #Llama3 70b achieved a pass@1 of ~0.44. This means it solved 44% of HumanEval problems on the first try.

February 13, 2025 at 7:27 PM
6️⃣ Run the evaluation
Finally, you're ready to run the eval:
In our run, #Llama3 70b achieved a pass@1 of ~0.44. This means it solved 44% of HumanEval problems on the first try.
Finally, you're ready to run the eval:
In our run, #Llama3 70b achieved a pass@1 of ~0.44. This means it solved 44% of HumanEval problems on the first try.
5️⃣ Increase execution timeout
To avoid false failures due to timeouts, bump up the timeouts in HumanEval's `evaluate_functional_correctness.py` file up to 35s:
To avoid false failures due to timeouts, bump up the timeouts in HumanEval's `evaluate_functional_correctness.py` file up to 35s:

February 13, 2025 at 7:27 PM
5️⃣ Increase execution timeout
To avoid false failures due to timeouts, bump up the timeouts in HumanEval's `evaluate_functional_correctness.py` file up to 35s:
To avoid false failures due to timeouts, bump up the timeouts in HumanEval's `evaluate_functional_correctness.py` file up to 35s:
4️⃣ Modify HumanEval to use Riza
Modify the execute.py file in HumanEval. Instead of running the unsafe exec(), call Riza's Code Interpreter API.
Just import riza, and add 2 lines of code:
Modify the execute.py file in HumanEval. Instead of running the unsafe exec(), call Riza's Code Interpreter API.
Just import riza, and add 2 lines of code:

February 13, 2025 at 7:27 PM
4️⃣ Modify HumanEval to use Riza
Modify the execute.py file in HumanEval. Instead of running the unsafe exec(), call Riza's Code Interpreter API.
Just import riza, and add 2 lines of code:
Modify the execute.py file in HumanEval. Instead of running the unsafe exec(), call Riza's Code Interpreter API.
Just import riza, and add 2 lines of code:


🛑 The problem?
❌ Executing LLM-generated code on your machine is dangerous. HumanEval itself comes with a big warning.
❌The code might delete files, steal secrets, or do other bad things.
And you don't want to have to manually review all 164 functions.
❌ Executing LLM-generated code on your machine is dangerous. HumanEval itself comes with a big warning.
❌The code might delete files, steal secrets, or do other bad things.
And you don't want to have to manually review all 164 functions.

February 13, 2025 at 7:27 PM
🛑 The problem?
❌ Executing LLM-generated code on your machine is dangerous. HumanEval itself comes with a big warning.
❌The code might delete files, steal secrets, or do other bad things.
And you don't want to have to manually review all 164 functions.
❌ Executing LLM-generated code on your machine is dangerous. HumanEval itself comes with a big warning.
❌The code might delete files, steal secrets, or do other bad things.
And you don't want to have to manually review all 164 functions.
💡 Here's an example HumanEval problem:
To run HumanEval, you
1️⃣First get the LLM to generate code to complete 164 functions like this.
2️⃣Then run the generated code and check if it passes the tests.
To run HumanEval, you
1️⃣First get the LLM to generate code to complete 164 functions like this.
2️⃣Then run the generated code and check if it passes the tests.

February 13, 2025 at 7:27 PM
💡 Here's an example HumanEval problem:
To run HumanEval, you
1️⃣First get the LLM to generate code to complete 164 functions like this.
2️⃣Then run the generated code and check if it passes the tests.
To run HumanEval, you
1️⃣First get the LLM to generate code to complete 164 functions like this.
2️⃣Then run the generated code and check if it passes the tests.
🧑💻🔒Run HumanEval safely with Riza
Codegen is a hot topic. Today, many LLMs can generate functions and even apps.
But how do you know which model writes the best code?
Enter #HumanEval.
Codegen is a hot topic. Today, many LLMs can generate functions and even apps.
But how do you know which model writes the best code?
Enter #HumanEval.

February 13, 2025 at 7:27 PM
🧑💻🔒Run HumanEval safely with Riza
Codegen is a hot topic. Today, many LLMs can generate functions and even apps.
But how do you know which model writes the best code?
Enter #HumanEval.
Codegen is a hot topic. Today, many LLMs can generate functions and even apps.
But how do you know which model writes the best code?
Enter #HumanEval.
As always, you can call this API with curl, or use our SDKs.
Our SDK is available in JavaScript, Python, and Go.
Here’s the same example, using our JavaScript SDK:
Our SDK is available in JavaScript, Python, and Go.
Here’s the same example, using our JavaScript SDK:

February 10, 2025 at 7:00 PM
As always, you can call this API with curl, or use our SDKs.
Our SDK is available in JavaScript, Python, and Go.
Here’s the same example, using our JavaScript SDK:
Our SDK is available in JavaScript, Python, and Go.
Here’s the same example, using our JavaScript SDK:
You can pass this function to Riza’s Execute Function API with a structured “input” parameter like this:
{"name": "Andrew"}
And you’ll get back a structured object:
"output": {
"greeting": "Hello, Andrew"
}
{"name": "Andrew"}
And you’ll get back a structured object:
"output": {
"greeting": "Hello, Andrew"
}

February 10, 2025 at 7:00 PM
You can pass this function to Riza’s Execute Function API with a structured “input” parameter like this:
{"name": "Andrew"}
And you’ll get back a structured object:
"output": {
"greeting": "Hello, Andrew"
}
{"name": "Andrew"}
And you’ll get back a structured object:
"output": {
"greeting": "Hello, Andrew"
}

Introducing: the Execute Function API 🤖🚀
It's now easier to execute LLM-generated code with structured inputs and outputs.
Here's how:
It's now easier to execute LLM-generated code with structured inputs and outputs.
Here's how:

February 10, 2025 at 7:00 PM
Introducing: the Execute Function API 🤖🚀
It's now easier to execute LLM-generated code with structured inputs and outputs.
Here's how:
It's now easier to execute LLM-generated code with structured inputs and outputs.
Here's how:
