



Zaid Humayun
@redixhumayun.bsky.social
Engineer @conviva | Figuring out databases
I keep getting lucky with the PR numbers


May 28, 2025 at 6:21 PM
I keep getting lucky with the PR numbers
Nested match statements, as the Lord intended
May 10, 2025 at 11:57 AM
Nested match statements, as the Lord intended
I like this thought process.
Easier to think of a database = storage layer + data model + query layer (language + optimizer)
Easier to think of a database = storage layer + data model + query layer (language + optimizer)

May 6, 2025 at 8:24 AM
I like this thought process.
Easier to think of a database = storage layer + data model + query layer (language + optimizer)
Easier to think of a database = storage layer + data model + query layer (language + optimizer)
Its issues like this that make me thankful I finally jumped to having a dedicated Ubuntu box. Open source tools actually *just work*

May 5, 2025 at 2:24 PM
Its issues like this that make me thankful I finally jumped to having a dedicated Ubuntu box. Open source tools actually *just work*
My toy database coming along quite nicely

April 28, 2025 at 5:39 AM
My toy database coming along quite nicely
Me trying to write code quickly in Rust

April 27, 2025 at 7:04 PM
Me trying to write code quickly in Rust
Really, really liking Rust's iterator pattern the more I use it!
Makes composition so much nicer to look at and reason about
Makes composition so much nicer to look at and reason about

April 6, 2025 at 1:43 PM
Really, really liking Rust's iterator pattern the more I use it!
Makes composition so much nicer to look at and reason about
Makes composition so much nicer to look at and reason about
In the year of our lord 2025, this is not a heretical opinion solely because of the abysmal state of debugging tooling in Rust z

March 24, 2025 at 3:37 AM
In the year of our lord 2025, this is not a heretical opinion solely because of the abysmal state of debugging tooling in Rust z
The more Rust I write, the more I vibe with this meme

February 23, 2025 at 3:28 PM
The more Rust I write, the more I vibe with this meme
Kolkata got some banging food

February 21, 2025 at 1:07 PM
Kolkata got some banging food
Functional programming got jokes

January 28, 2025 at 7:39 AM
Functional programming got jokes
Now, we see much better performance when comparing cache stats for the 3 implementations.
It isn't enough to have contiguous memory access, you also need to be aware of the cache hardware and how many entries can fit per cache line.
It isn't enough to have contiguous memory access, you also need to be aware of the cache hardware and how many entries can fit per cache line.



January 27, 2025 at 2:44 PM
Now, we see much better performance when comparing cache stats for the 3 implementations.
It isn't enough to have contiguous memory access, you also need to be aware of the cache hardware and how many entries can fit per cache line.
It isn't enough to have contiguous memory access, you also need to be aware of the cache hardware and how many entries can fit per cache line.
Doing all of the above requires you to know some information about your hardware, like the size of your cache and the size of a cache line.

January 27, 2025 at 2:44 PM
Doing all of the above requires you to know some information about your hardware, like the size of your cache and the size of a cache line.
We can do a more compact open addressing scheme which will fit 4 entries per cache line
Also, using u64 instead of Strings leads to better performance since Strings are always heap allocated
Also, using u64 instead of Strings leads to better performance since Strings are always heap allocated

January 27, 2025 at 2:44 PM
We can do a more compact open addressing scheme which will fit 4 entries per cache line
Also, using u64 instead of Strings leads to better performance since Strings are always heap allocated
Also, using u64 instead of Strings leads to better performance since Strings are always heap allocated
Profiling, however, shows very different results. It shows chaining and open addressing displaying roughly the same levels of cache performance.
Open addressing ends up performing better but that's only due to fewer overall instructions
Open addressing ends up performing better but that's only due to fewer overall instructions



January 27, 2025 at 2:44 PM
Profiling, however, shows very different results. It shows chaining and open addressing displaying roughly the same levels of cache performance.
Open addressing ends up performing better but that's only due to fewer overall instructions
Open addressing ends up performing better but that's only due to fewer overall instructions
You can handle collisions via open addressing (linear probing). This is where you just search through every subsequent entry until you find one where you can insert the key-value pair.
This should be more cache friendly since the entire memory is contiguously allocated
This should be more cache friendly since the entire memory is contiguously allocated


January 27, 2025 at 2:44 PM
You can handle collisions via open addressing (linear probing). This is where you just search through every subsequent entry until you find one where you can insert the key-value pair.
This should be more cache friendly since the entire memory is contiguously allocated
This should be more cache friendly since the entire memory is contiguously allocated
You can handle collisions via chaining where each entry becomes a linked list. This is simple but tends to lead to fragmented memory since each node is allocated separately.
Fragmented memory should theoretically lead to poorer cache performance.
Fragmented memory should theoretically lead to poorer cache performance.


January 27, 2025 at 2:44 PM
You can handle collisions via chaining where each entry becomes a linked list. This is simple but tends to lead to fragmented memory since each node is allocated separately.
Fragmented memory should theoretically lead to poorer cache performance.
Fragmented memory should theoretically lead to poorer cache performance.
Building a hash map is easy enough - a few public methods and a couple of internal methods to track when to resize the hash map

January 27, 2025 at 2:44 PM
Building a hash map is easy enough - a few public methods and a couple of internal methods to track when to resize the hash map
I've been trying to understand profiling tools better and decided to build a cache conscious hash map as a way to get more familiar with the tooling.
I wrote a small blog post and I'll cover the high level points in this 🧵
I wrote a small blog post and I'll cover the high level points in this 🧵

January 27, 2025 at 2:44 PM
I've been trying to understand profiling tools better and decided to build a cache conscious hash map as a way to get more familiar with the tooling.
I wrote a small blog post and I'll cover the high level points in this 🧵
I wrote a small blog post and I'll cover the high level points in this 🧵
The database is the log

January 14, 2025 at 5:45 PM
The database is the log
This falls apart when using Strings because the compact version ends up performing worse than regular, despite better cache performance
Presumably because I pay the cost of pointer chases to get the String data along with the cost of looking up the status separately
Presumably because I pay the cost of pointer chases to get the String data along with the cost of looking up the status separately

January 14, 2025 at 3:18 PM
This falls apart when using Strings because the compact version ends up performing worse than regular, despite better cache performance
Presumably because I pay the cost of pointer chases to get the String data along with the cost of looking up the status separately
Presumably because I pay the cost of pointer chases to get the String data along with the cost of looking up the status separately
Turns out my hypothesis was correct. Shifting to a more compact structure like the one below (which I think some commenters already suggested) significantly improves cache performance! The LLC misses see more than a 50% drop!

January 14, 2025 at 3:18 PM
Turns out my hypothesis was correct. Shifting to a more compact structure like the one below (which I think some commenters already suggested) significantly improves cache performance! The LLC misses see more than a 50% drop!
Well, I spent some more time playing around with this and think I have a hypothesis for why.
My struct for my open addressing variant is an enum which occupies 24 bytes when u64 is used as key-value. Each cache line is 64 bytes which means 2-3 per line
My struct for my open addressing variant is an enum which occupies 24 bytes when u64 is used as key-value. Each cache line is 64 bytes which means 2-3 per line

January 12, 2025 at 5:35 PM
Well, I spent some more time playing around with this and think I have a hypothesis for why.
My struct for my open addressing variant is an enum which occupies 24 bytes when u64 is used as key-value. Each cache line is 64 bytes which means 2-3 per line
My struct for my open addressing variant is an enum which occupies 24 bytes when u64 is used as key-value. Each cache line is 64 bytes which means 2-3 per line
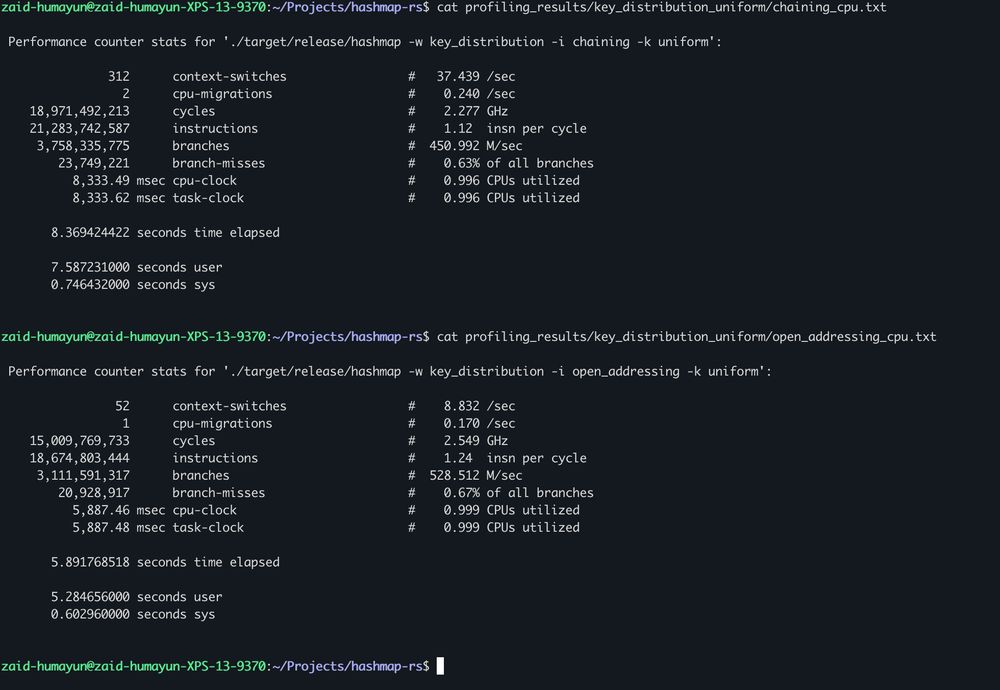
I had an idea that it could be CPU migrations which was causing the cache performance issues but it doesn't look like that's the case either
This is just plain strange...
This is just plain strange...
January 12, 2025 at 10:54 AM
I had an idea that it could be CPU migrations which was causing the cache performance issues but it doesn't look like that's the case either
This is just plain strange...
This is just plain strange...
Open addressing still performs better overall but that seems to primarily because of better CPU performance rather than better cache performance
Chaining uses a LinkedList which is adding a lot of overhead in terms of instructions
Chaining uses a LinkedList which is adding a lot of overhead in terms of instructions

January 12, 2025 at 10:22 AM
Open addressing still performs better overall but that seems to primarily because of better CPU performance rather than better cache performance
Chaining uses a LinkedList which is adding a lot of overhead in terms of instructions
Chaining uses a LinkedList which is adding a lot of overhead in terms of instructions