



Robert Nowak
@rdnowak.bsky.social
Director of the Center for the Advancement of Progress
Google promotes box shirts too

September 5, 2025 at 6:19 PM
Google promotes box shirts too

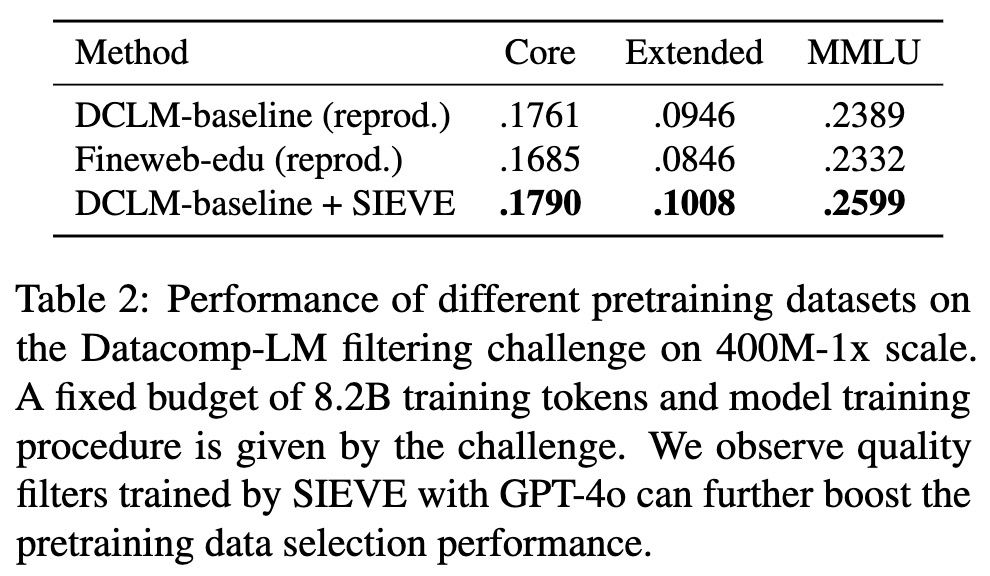
SIEVE improves upon existing quality filtering methods in the DataComp-LM challenge, producing better LLM pretraining data that led to improved model performance.
This work is part of Jifan's broader research on efficient ML training, from active learning to label-efficient SFT for LLMs.
This work is part of Jifan's broader research on efficient ML training, from active learning to label-efficient SFT for LLMs.
February 7, 2025 at 2:55 AM
SIEVE improves upon existing quality filtering methods in the DataComp-LM challenge, producing better LLM pretraining data that led to improved model performance.
This work is part of Jifan's broader research on efficient ML training, from active learning to label-efficient SFT for LLMs.
This work is part of Jifan's broader research on efficient ML training, from active learning to label-efficient SFT for LLMs.
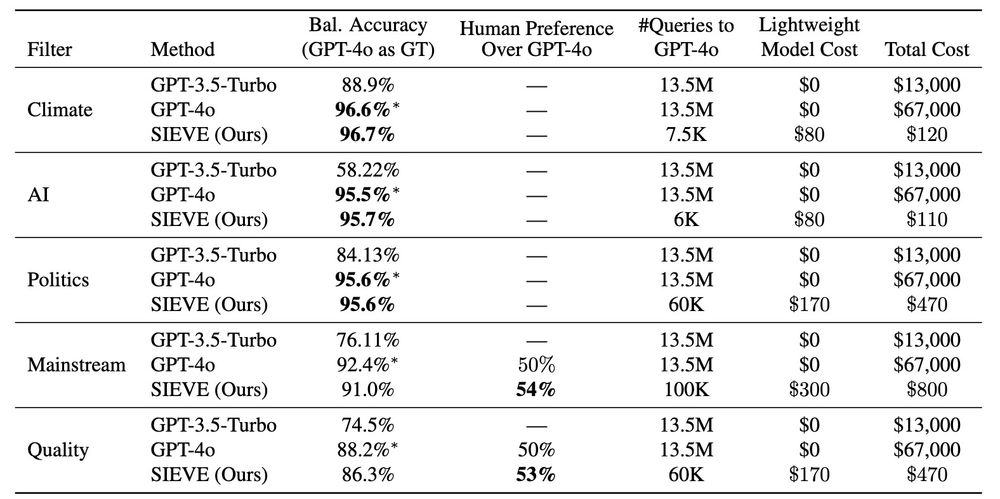
SIEVE distills GPT-4's data filtering capabilities into lightweight models at <1% of the cost. Not just minor improvements - we're talking 500x more efficient filtering operations.
February 7, 2025 at 2:55 AM
SIEVE distills GPT-4's data filtering capabilities into lightweight models at <1% of the cost. Not just minor improvements - we're talking 500x more efficient filtering operations.
🧵 Heard all the buzz around distilling from OpenAI models? Check out @jifanz's latest work SIEVE - showing how strategic distillation can make LLM development radically more cost-effective while matching quality.

February 7, 2025 at 2:55 AM
🧵 Heard all the buzz around distilling from OpenAI models? Check out @jifanz's latest work SIEVE - showing how strategic distillation can make LLM development radically more cost-effective while matching quality.
Maybe Trump should have read my mom's book: "For the first six weeks, the embryo, whether XX or XY, coasts along in sexual ambiguity." p. 25

January 23, 2025 at 12:25 AM
Maybe Trump should have read my mom's book: "For the first six weeks, the embryo, whether XX or XY, coasts along in sexual ambiguity." p. 25


I’ll be presenting a poster on some work on OOD detection using active learning today at 4:30pst!

December 11, 2024 at 10:18 PM
I’ll be presenting a poster on some work on OOD detection using active learning today at 4:30pst!
Past work has characterized the functions learned by neural networks: arxiv.org/pdf/1910.01635, arxiv.org/abs/1902.05040, arxiv.org/abs/2109.12960, arxiv.org/abs/2105.03361. But it turns out multi-task training produces strikingly different solutions! Adding tasks produces “kernel-like” solutions.

December 7, 2024 at 9:49 PM
Past work has characterized the functions learned by neural networks: arxiv.org/pdf/1910.01635, arxiv.org/abs/1902.05040, arxiv.org/abs/2109.12960, arxiv.org/abs/2105.03361. But it turns out multi-task training produces strikingly different solutions! Adding tasks produces “kernel-like” solutions.
There is a ton of interest in the question of whether AI can be be funny: www.bbc.com/future/artic.... Our paper at NeurIPS investigates the humor generation capabilities of the latest and greatest AI models using one of world’s largest humor datasets! arxiv.org/pdf/2406.10522

December 4, 2024 at 2:00 PM
There is a ton of interest in the question of whether AI can be be funny: www.bbc.com/future/artic.... Our paper at NeurIPS investigates the humor generation capabilities of the latest and greatest AI models using one of world’s largest humor datasets! arxiv.org/pdf/2406.10522