



@rbalestr.bsky.social
We validate our pipeline on many noise levels/types across datasets, architectures, and SSL objectives, demonstrating that **data curriculum remains a fully under-explored axis of improvement for SSL pretraining**! Huge congrats to
Wenquan Lu, Jiaqi Zhang and Hugues Van Hassel
Wenquan Lu, Jiaqi Zhang and Hugues Van Hassel
May 20, 2025 at 2:38 PM
We validate our pipeline on many noise levels/types across datasets, architectures, and SSL objectives, demonstrating that **data curriculum remains a fully under-explored axis of improvement for SSL pretraining**! Huge congrats to
Wenquan Lu, Jiaqi Zhang and Hugues Van Hassel
Wenquan Lu, Jiaqi Zhang and Hugues Van Hassel
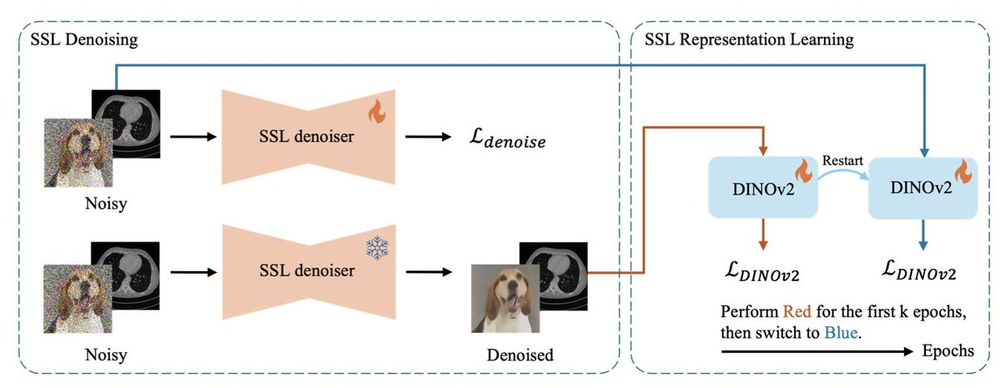
Our solution is to train a SSL denoiser only to create a data curriculum for the SSL method you are interested in. By first observing denoised samples and gradually going back to the original samples, the final SSL model performs better than the baseline!
May 20, 2025 at 2:38 PM
Our solution is to train a SSL denoiser only to create a data curriculum for the SSL method you are interested in. By first observing denoised samples and gradually going back to the original samples, the final SSL model performs better than the baseline!
With high levels of noise, it is standard to have a denoiser as part of the train/test preprocessing pipeline... but this has drawbacks e.g. adding a bias to your pipeline, cross-validation, sensitivity to distribution shifts... AI/SSL should strive for denoiser-free pipelines!

May 20, 2025 at 2:38 PM
With high levels of noise, it is standard to have a denoiser as part of the train/test preprocessing pipeline... but this has drawbacks e.g. adding a bias to your pipeline, cross-validation, sensitivity to distribution shifts... AI/SSL should strive for denoiser-free pipelines!
None of this would have been possible without the incredible work of co-authors Jeremy Budd, Javier Ideami, Benjamin Macdowall Rynne, and Keith Duggar
! And behind it all, MLST and the open Discord channel where we all met!
! And behind it all, MLST and the open Discord channel where we all met!
May 20, 2025 at 2:08 PM
None of this would have been possible without the incredible work of co-authors Jeremy Budd, Javier Ideami, Benjamin Macdowall Rynne, and Keith Duggar
! And behind it all, MLST and the open Discord channel where we all met!
! And behind it all, MLST and the open Discord channel where we all met!
The spline connection offers closed-form solution for many questions we have been wondering around SAEs--and provides clear actionable solutions such as our PAM-SGD training algo. PAM-SGD is EM-like, relying on the partition and region assignment, outperforming typical Adam/SGD

May 20, 2025 at 2:08 PM
The spline connection offers closed-form solution for many questions we have been wondering around SAEs--and provides clear actionable solutions such as our PAM-SGD training algo. PAM-SGD is EM-like, relying on the partition and region assignment, outperforming typical Adam/SGD
The findings stem from expressing SAEs as splines (arxiv.org/abs/2408.04809) and doing a deep dive into their partition, constraints, and underlying geometry! We not only characterize their input space partition and geometry, but tie SAE to common methods such as k-means and PCA

May 20, 2025 at 2:08 PM
The findings stem from expressing SAEs as splines (arxiv.org/abs/2408.04809) and doing a deep dive into their partition, constraints, and underlying geometry! We not only characterize their input space partition and geometry, but tie SAE to common methods such as k-means and PCA
Our work also raises a deeper question: which of the attention or MLP blocks have to be adapted to steer a model to your specific downstream application? Tons of open questions to explore!
This amazing work was led by
@pszwnzl.bsky.social , Wojciech Jasiński, Marek Śmieja and Bartosz Zielinski
This amazing work was led by
@pszwnzl.bsky.social , Wojciech Jasiński, Marek Śmieja and Bartosz Zielinski
December 5, 2024 at 6:47 PM
Our work also raises a deeper question: which of the attention or MLP blocks have to be adapted to steer a model to your specific downstream application? Tons of open questions to explore!
This amazing work was led by
@pszwnzl.bsky.social , Wojciech Jasiński, Marek Śmieja and Bartosz Zielinski
This amazing work was led by
@pszwnzl.bsky.social , Wojciech Jasiński, Marek Śmieja and Bartosz Zielinski
That bias towards capturing details manifests itself in terms of different attention behavior within ViTs. From those findings, we propose a new token aggregator that can counter such attention bias without having to finetune the backbone -> gains in linear probe performance!

December 5, 2024 at 6:47 PM
That bias towards capturing details manifests itself in terms of different attention behavior within ViTs. From those findings, we propose a new token aggregator that can counter such attention bias without having to finetune the backbone -> gains in linear probe performance!
That finding comes from our previous study (arxiv.org/abs/2402.11337) proving why methods like MAE do not perform well without finetuning compared to joint embedding methods: they learn too many details about the data that are not useful for coarse scale (semantic) classification

Learning by Reconstruction Produces Uninformative Features For Perception
Input space reconstruction is an attractive representation learning paradigm. Despite interpretability of the reconstruction and generation, we identify a misalignment between learning by reconstructi...
arxiv.org
December 5, 2024 at 6:47 PM
That finding comes from our previous study (arxiv.org/abs/2402.11337) proving why methods like MAE do not perform well without finetuning compared to joint embedding methods: they learn too many details about the data that are not useful for coarse scale (semantic) classification
This great work was led by great collaborators Xue Xia, Tao Zhang and Lorenz Hurni! And we will be presenting a poster at the SSL Workshop at NeurIPS2024!
December 2, 2024 at 2:22 PM
This great work was led by great collaborators Xue Xia, Tao Zhang and Lorenz Hurni! And we will be presenting a poster at the SSL Workshop at NeurIPS2024!
We propose an approach that combines segmentation and association of geographic entities in historical maps using video instance segmentation (VIS). Combined with a novel method for generating synthetic videos from unlabeled historical maps, we produce SSL models with high acc.

December 2, 2024 at 2:22 PM
We propose an approach that combines segmentation and association of geographic entities in historical maps using video instance segmentation (VIS). Combined with a novel method for generating synthetic videos from unlabeled historical maps, we produce SSL models with high acc.