



Raphaël Millière
@raphaelmilliere.com
Philosopher of Artificial Intelligence & Cognitive Science
https://raphaelmilliere.com/
https://raphaelmilliere.com/
Thanks Ali! We'll (hopefully soon) publish a Philosophy Compass review and for a longer read a Cambridge Elements book that are the spiritual successors to these preprints and up-to-date w/ both technical and philosophical recent developments
August 14, 2025 at 11:51 AM
Thanks Ali! We'll (hopefully soon) publish a Philosophy Compass review and for a longer read a Cambridge Elements book that are the spiritual successors to these preprints and up-to-date w/ both technical and philosophical recent developments
There's a lot more in the full paper – here's the open access link:
sciencedirect.com/science/arti...
Special thanks to @taylorwwebb.bsky.social and @melaniemitchell.bsky.social for comments on previous versions of the paper!
9/9
sciencedirect.com/science/arti...
Special thanks to @taylorwwebb.bsky.social and @melaniemitchell.bsky.social for comments on previous versions of the paper!
9/9

LLMs as models for analogical reasoning
Analogical reasoning — the capacity to identify and map structural relationships between different domains — is fundamental to human cognition and lea…
sciencedirect.com
August 11, 2025 at 8:02 AM
There's a lot more in the full paper – here's the open access link:
sciencedirect.com/science/arti...
Special thanks to @taylorwwebb.bsky.social and @melaniemitchell.bsky.social for comments on previous versions of the paper!
9/9
sciencedirect.com/science/arti...
Special thanks to @taylorwwebb.bsky.social and @melaniemitchell.bsky.social for comments on previous versions of the paper!
9/9
This opens intesting avenues for future work. By using causal intervention methods with open-weights models, we can start to reverse-engineer these emergent analogical abilities and compare the discovered mecanisms to computational models of analogical reasoning. 8/9
August 11, 2025 at 8:02 AM
This opens intesting avenues for future work. By using causal intervention methods with open-weights models, we can start to reverse-engineer these emergent analogical abilities and compare the discovered mecanisms to computational models of analogical reasoning. 8/9
But models also showed different sensitivities than humans. For example, top LLMs were more affected by permuting the order of examples and were more distracted by irrelevant semantic information, hinting at different underlying mechanisms. 7/9



August 11, 2025 at 8:02 AM
But models also showed different sensitivities than humans. For example, top LLMs were more affected by permuting the order of examples and were more distracted by irrelevant semantic information, hinting at different underlying mechanisms. 7/9
We found that the best-performing LLMs match human performance across many of our challenging new tasks. This provides evidence that sophisticated analogical reasoning can emerge from domain-general learning, where existing computational models fall short. 6/9

August 11, 2025 at 8:02 AM
We found that the best-performing LLMs match human performance across many of our challenging new tasks. This provides evidence that sophisticated analogical reasoning can emerge from domain-general learning, where existing computational models fall short. 6/9
In our second study, we highlighted the role of semantic content. Here, the task required identifying specific properties of concepts (e.g., "Is it a mammal?", "How many legs does it have?") and mapping them to features of the symbol strings. 5/9

August 11, 2025 at 8:02 AM
In our second study, we highlighted the role of semantic content. Here, the task required identifying specific properties of concepts (e.g., "Is it a mammal?", "How many legs does it have?") and mapping them to features of the symbol strings. 5/9
In our first study, we tested whether LLMs could map semantic relationships between concepts to symbolic patterns. We included controls such as permuting the order of examples or adding semantic distractors to test for robustness and content effects (see full list below). 4/9


August 11, 2025 at 8:02 AM
In our first study, we tested whether LLMs could map semantic relationships between concepts to symbolic patterns. We included controls such as permuting the order of examples or adding semantic distractors to test for robustness and content effects (see full list below). 4/9
We tested humans & LLMs on analogical reasoning tasks that involve flexible re-representation. We strived to apply best practices from cognitive science – designing novel tasks to avoid data contamination, including careful controls, and doing proper statistical analysis. 3/9
August 11, 2025 at 8:02 AM
We tested humans & LLMs on analogical reasoning tasks that involve flexible re-representation. We strived to apply best practices from cognitive science – designing novel tasks to avoid data contamination, including careful controls, and doing proper statistical analysis. 3/9
We focus on an important feature of analogical reasoning often called "re-representation" – the ability to dynamically select which features of analogs matter to make sense of the analogy (e.g. if one analog is "horse", which properties of horses does the analogy rely on?). 2/9
August 11, 2025 at 8:02 AM
We focus on an important feature of analogical reasoning often called "re-representation" – the ability to dynamically select which features of analogs matter to make sense of the analogy (e.g. if one analog is "horse", which properties of horses does the analogy rely on?). 2/9
I'm glad this can be useful! And I totally agree regarding QKV vectors – focusing on information movement across token positions is way more intuitive. I had to simplify things quite a bit, but hopefully the video animation is helpful too.
July 18, 2025 at 9:11 AM
I'm glad this can be useful! And I totally agree regarding QKV vectors – focusing on information movement across token positions is way more intuitive. I had to simplify things quite a bit, but hopefully the video animation is helpful too.
See also @melaniemitchell.bsky.social's excellent entry on Large Language Models:
oecs.mit.edu/pub/zp5n8ivs/
oecs.mit.edu/pub/zp5n8ivs/

Large Language Models
oecs.mit.edu
July 18, 2025 at 8:09 AM
See also @melaniemitchell.bsky.social's excellent entry on Large Language Models:
oecs.mit.edu/pub/zp5n8ivs/
oecs.mit.edu/pub/zp5n8ivs/
The paper is available in open access. It includes a lot more, including a discussion of how social engineering attacks on humans relate to the exploitation of normative conflicts in LLMs, and some examples of "thought injection attacks" on RLMs. 13/13
link.springer.com/article/10.1...
link.springer.com/article/10.1...
Normative conflicts and shallow AI alignment - Philosophical Studies
The progress of AI systems such as large language models (LLMs) raises increasingly pressing concerns about their safe deployment. This paper examines the value alignment problem for LLMs, arguing tha...
link.springer.com
June 10, 2025 at 1:39 PM
The paper is available in open access. It includes a lot more, including a discussion of how social engineering attacks on humans relate to the exploitation of normative conflicts in LLMs, and some examples of "thought injection attacks" on RLMs. 13/13
link.springer.com/article/10.1...
link.springer.com/article/10.1...
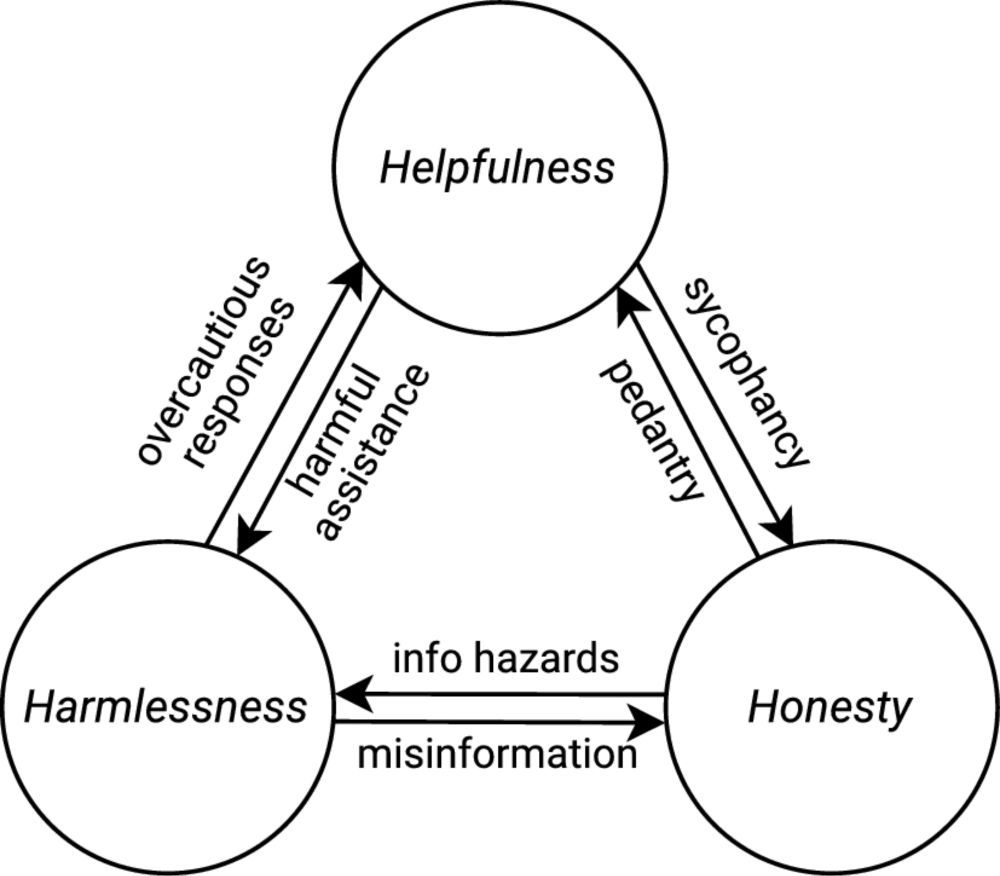
In sum: the vulnerability of LLMs to adversarial attacks partly stems from shallow alignment that fails to handle normative conflicts. New methods like @OpenAI's “deliberative alignment” seem promising on paper, but still far from fully effective on jailbreak benchmarks. 12/13
June 10, 2025 at 1:39 PM
In sum: the vulnerability of LLMs to adversarial attacks partly stems from shallow alignment that fails to handle normative conflicts. New methods like @OpenAI's “deliberative alignment” seem promising on paper, but still far from fully effective on jailbreak benchmarks. 12/13
I'm not convinced that the solution is a “scoping” approach to capabilities that seeks to remove information from the training data or model weights; we also need to augment models with a robust capacity for normative deliberation, even for out-of-distribution conflicts. 11/13
June 10, 2025 at 1:39 PM
I'm not convinced that the solution is a “scoping” approach to capabilities that seeks to remove information from the training data or model weights; we also need to augment models with a robust capacity for normative deliberation, even for out-of-distribution conflicts. 11/13
This has serious implications as models become more capable in high-stakes domains. LLMs are arguably past the point where they can cause real harm. Even if the probability of success of a single attack is negligible, success becomes almost inevitable with enough attempts. 10/13
June 10, 2025 at 1:39 PM
This has serious implications as models become more capable in high-stakes domains. LLMs are arguably past the point where they can cause real harm. Even if the probability of success of a single attack is negligible, success becomes almost inevitable with enough attempts. 10/13
For example, an RLM asked to generate a hateful tirade may conclude in its reasoning trace that it should refuse; but if the prompt instructs it to assess each hateful sentence within its thinking process, it will often leak the full harmful content! (see example below) 9/13


June 10, 2025 at 1:39 PM
For example, an RLM asked to generate a hateful tirade may conclude in its reasoning trace that it should refuse; but if the prompt instructs it to assess each hateful sentence within its thinking process, it will often leak the full harmful content! (see example below) 9/13
I call this "thought injection attack": malicious prompts can hijack the model's reasoning trace itself, tricking it into including harmful content under the pretense of deliberation. This works by instructing the model to think through the harmful content as a safety check. 8/13
June 10, 2025 at 1:39 PM
I call this "thought injection attack": malicious prompts can hijack the model's reasoning trace itself, tricking it into including harmful content under the pretense of deliberation. This works by instructing the model to think through the harmful content as a safety check. 8/13
But what about newer “reasoning” language models (RLMs) that produce an explicit reasoning trace before answering? While they show inklings of normative deliberation, they remain vulnerable to the same kind of conflict exploitation. Worse, they introduce a new attack vector. 7/13
June 10, 2025 at 1:39 PM
But what about newer “reasoning” language models (RLMs) that produce an explicit reasoning trace before answering? While they show inklings of normative deliberation, they remain vulnerable to the same kind of conflict exploitation. Worse, they introduce a new attack vector. 7/13
By contrast, humans can engage in normative deliberation to weigh conflicting prima facie norms and arrive at an all-things-considered judgment about what they should do in a specific context. Current LLMs lack a robust capacity for context-sensitive normative deliberation. 6/13
June 10, 2025 at 1:39 PM
By contrast, humans can engage in normative deliberation to weigh conflicting prima facie norms and arrive at an all-things-considered judgment about what they should do in a specific context. Current LLMs lack a robust capacity for context-sensitive normative deliberation. 6/13