



Ramith Hettiarachchi
@ramith.fyi
PhD Student @CMUPittCompBio.bsky.social / @SCSatCMU.bsky.social
Interested in ML for science/Compuational drug discovery/AI-assisted scientific discovery 🤞
from 🇱🇰🫶 https://ramith.fyi
Interested in ML for science/Compuational drug discovery/AI-assisted scientific discovery 🤞
from 🇱🇰🫶 https://ramith.fyi
Pinned
Ramith Hettiarachchi
@ramith.fyi
· Nov 29
The self-hosted 'machine learning in structural biology' feed has been fairly stable to maintain so far, so I'm sharing the GitHub repo for anyone to edit the algorithm (in reply)
bsky.app/profile/rami...
bsky.app/profile/rami...
Installing alphafold3 on the DGX Spark was pretty easy, but I forgot that JAX preallocates gpu memory* (XLA_CLIENT_MEM_FRACTION=0.95)
Forgot to change those settings, and the spark froze without me being able to ssh 😆
*In the spark, it’s unified mem
Gotto test again either reduced reallocation
Forgot to change those settings, and the spark froze without me being able to ssh 😆
*In the spark, it’s unified mem
Gotto test again either reduced reallocation

November 14, 2025 at 12:58 PM
Installing alphafold3 on the DGX Spark was pretty easy, but I forgot that JAX preallocates gpu memory* (XLA_CLIENT_MEM_FRACTION=0.95)
Forgot to change those settings, and the spark froze without me being able to ssh 😆
*In the spark, it’s unified mem
Gotto test again either reduced reallocation
Forgot to change those settings, and the spark froze without me being able to ssh 😆
*In the spark, it’s unified mem
Gotto test again either reduced reallocation
atomworks is a pretty cool GitHub repo!
November 11, 2025 at 7:47 PM
atomworks is a pretty cool GitHub repo!
Reposted by Ramith Hettiarachchi

Messy thinker? That's a superpower! Find panel coming soon in Muse helps you jump straight to your thought in a busy board.
November 11, 2025 at 5:48 PM
Messy thinker? That's a superpower! Find panel coming soon in Muse helps you jump straight to your thought in a busy board.
Reposted by Ramith Hettiarachchi

Are you a Ph.D. student at @cmu.edu? Can you describe your research and its importance in under 3 minutes to a layperson?
In 2025, 🥇 went to a @cmurobotics.bsky.social student. 🥈🥉 to @cmuengineering.bsky.social.
Register to compete in the 2026 #3MTCMU competition by 2/4. cmu.is/2026-3MT-Compete
In 2025, 🥇 went to a @cmurobotics.bsky.social student. 🥈🥉 to @cmuengineering.bsky.social.
Register to compete in the 2026 #3MTCMU competition by 2/4. cmu.is/2026-3MT-Compete

November 11, 2025 at 1:47 PM
Are you a Ph.D. student at @cmu.edu? Can you describe your research and its importance in under 3 minutes to a layperson?
In 2025, 🥇 went to a @cmurobotics.bsky.social student. 🥈🥉 to @cmuengineering.bsky.social.
Register to compete in the 2026 #3MTCMU competition by 2/4. cmu.is/2026-3MT-Compete
In 2025, 🥇 went to a @cmurobotics.bsky.social student. 🥈🥉 to @cmuengineering.bsky.social.
Register to compete in the 2026 #3MTCMU competition by 2/4. cmu.is/2026-3MT-Compete

🧗♂️ If any kind soul can guide me with the next steps, appreciate it #bouldering 🤪

To be continued…
YouTube video by Ramith Hettiarachchi
www.youtube.com
November 6, 2025 at 3:28 PM
🧗♂️ If any kind soul can guide me with the next steps, appreciate it #bouldering 🤪
An application asked for the lifetime number of lines coded.. with gemini's help wrote a code to count net lines (.cpp or .py) an author contributed to a repo..
Thinking of polishing it up further:
current version: gist.github.com/ramithuh/aa6...
Thinking of polishing it up further:
current version: gist.github.com/ramithuh/aa6...

November 5, 2025 at 4:49 PM
An application asked for the lifetime number of lines coded.. with gemini's help wrote a code to count net lines (.cpp or .py) an author contributed to a repo..
Thinking of polishing it up further:
current version: gist.github.com/ramithuh/aa6...
Thinking of polishing it up further:
current version: gist.github.com/ramithuh/aa6...
Reposted by Ramith Hettiarachchi

What will you do today, knowing that you are one of the rarest forms of life to ever walk the Earth?
Mark Nepo
Mark Nepo

November 4, 2025 at 6:38 PM
What will you do today, knowing that you are one of the rarest forms of life to ever walk the Earth?
Mark Nepo
Mark Nepo
dgx spark training speed impression while training a diffusion language model on Shakespeare:
DGX Spark: ~1.3 it/s
L40: ~3.5 it/s
(same batch size used here)
DGX Spark: ~1.3 it/s
L40: ~3.5 it/s
(same batch size used here)

November 2, 2025 at 4:38 PM
dgx spark training speed impression while training a diffusion language model on Shakespeare:
DGX Spark: ~1.3 it/s
L40: ~3.5 it/s
(same batch size used here)
DGX Spark: ~1.3 it/s
L40: ~3.5 it/s
(same batch size used here)
I like the la-proteina architecture :
- transformer with Pair-Biased Multi-Head Attention
| Model | Layers | Parameters |
+---------+------+------------+
| Encoder | 12 | ~130M |
| Decoder | 12 | ~130M |
| Denoiser| 14 | ~160M |
+---------+------+-----------+
- transformer with Pair-Biased Multi-Head Attention
| Model | Layers | Parameters |
+---------+------+------------+
| Encoder | 12 | ~130M |
| Decoder | 12 | ~130M |
| Denoiser| 14 | ~160M |
+---------+------+-----------+
November 2, 2025 at 2:13 AM
I like the la-proteina architecture :
- transformer with Pair-Biased Multi-Head Attention
| Model | Layers | Parameters |
+---------+------+------------+
| Encoder | 12 | ~130M |
| Decoder | 12 | ~130M |
| Denoiser| 14 | ~160M |
+---------+------+-----------+
- transformer with Pair-Biased Multi-Head Attention
| Model | Layers | Parameters |
+---------+------+------------+
| Encoder | 12 | ~130M |
| Decoder | 12 | ~130M |
| Denoiser| 14 | ~160M |
+---------+------+-----------+
realizing that understanding something on various levels of granularity is important..
October 30, 2025 at 5:03 AM
realizing that understanding something on various levels of granularity is important..
Reposted by Ramith Hettiarachchi

How to organize your talk?
I used to present like this, thinking that I was being "academic", "organized", and "professional".
BUT, from the audience's viewpoints, this sucks. 😱
Look how far they need to hold a long-term context to just make sense of what you're saying!
I used to present like this, thinking that I was being "academic", "organized", and "professional".
BUT, from the audience's viewpoints, this sucks. 😱
Look how far they need to hold a long-term context to just make sense of what you're saying!
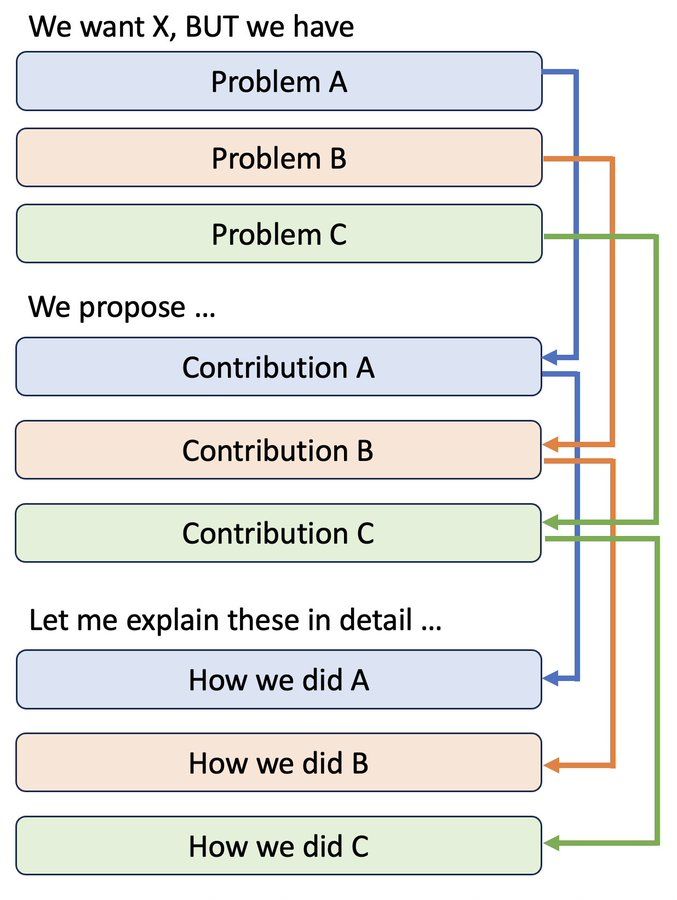
October 29, 2025 at 7:27 PM
How to organize your talk?
I used to present like this, thinking that I was being "academic", "organized", and "professional".
BUT, from the audience's viewpoints, this sucks. 😱
Look how far they need to hold a long-term context to just make sense of what you're saying!
I used to present like this, thinking that I was being "academic", "organized", and "professional".
BUT, from the audience's viewpoints, this sucks. 😱
Look how far they need to hold a long-term context to just make sense of what you're saying!
Reposted by Ramith Hettiarachchi

Is 3D dragging you down? Wish you could instead use the 2D ColabFold representation for all your work? 🤓
Introducing: py2Dmol 🧬
(feedback, suggestions, requests are welcome)
Introducing: py2Dmol 🧬
(feedback, suggestions, requests are welcome)

October 29, 2025 at 1:39 AM
Is 3D dragging you down? Wish you could instead use the 2D ColabFold representation for all your work? 🤓
Introducing: py2Dmol 🧬
(feedback, suggestions, requests are welcome)
Introducing: py2Dmol 🧬
(feedback, suggestions, requests are welcome)
prototyping a dashboard to submit training jobs to a cluster..
The idea is to do prototyping in a cluster-agnostic manner (local GPU), then once the prototype is ready for a production run, use a dashboard to see which kinds of GPUs are available and submit it..
The idea is to do prototyping in a cluster-agnostic manner (local GPU), then once the prototype is ready for a production run, use a dashboard to see which kinds of GPUs are available and submit it..
October 26, 2025 at 12:58 AM
prototyping a dashboard to submit training jobs to a cluster..
The idea is to do prototyping in a cluster-agnostic manner (local GPU), then once the prototype is ready for a production run, use a dashboard to see which kinds of GPUs are available and submit it..
The idea is to do prototyping in a cluster-agnostic manner (local GPU), then once the prototype is ready for a production run, use a dashboard to see which kinds of GPUs are available and submit it..

The Show Must Go On (Remastered 2011)
YouTube video by Queen - Topic
youtu.be
October 25, 2025 at 3:08 PM
Reposted by Ramith Hettiarachchi

Underrated advice: Have one friend who tells you the truth. Not the comfortable truth. The uncomfortable truth. The truth that makes you better, not feel better. That's love.
October 25, 2025 at 2:36 PM
Underrated advice: Have one friend who tells you the truth. Not the comfortable truth. The uncomfortable truth. The truth that makes you better, not feel better. That's love.
when you cant miss out a dinner w friends, yet as a TA you have to answer some questions students have* 🥹😅
*for a HW that's due midnight
*for a HW that's due midnight

October 22, 2025 at 6:26 AM
when you cant miss out a dinner w friends, yet as a TA you have to answer some questions students have* 🥹😅
*for a HW that's due midnight
*for a HW that's due midnight
one of the fondest memories I have during high school time is intel shipping me an edison development board..
back in 2014, i emailed a PM @ Intel with a suggestion, she kindly acknowleged it.. and the next day she asked for my address so that she could send me an intel galileo board..
(1/4)
back in 2014, i emailed a PM @ Intel with a suggestion, she kindly acknowleged it.. and the next day she asked for my address so that she could send me an intel galileo board..
(1/4)

October 21, 2025 at 5:00 AM
one of the fondest memories I have during high school time is intel shipping me an edison development board..
back in 2014, i emailed a PM @ Intel with a suggestion, she kindly acknowleged it.. and the next day she asked for my address so that she could send me an intel galileo board..
(1/4)
back in 2014, i emailed a PM @ Intel with a suggestion, she kindly acknowleged it.. and the next day she asked for my address so that she could send me an intel galileo board..
(1/4)
Reposted by Ramith Hettiarachchi
Did you know that even when Muse (and half the internet) are offline, you can still access 100% of your data in Muse. Even edit from multiple devices, and everything will sync when the internet comes back online. Keep your notes where you can always see them: museapp.com

Think deeper than one page
Muse is a cozy space for deep thinking. Let your ideas branch and grow inside nested boards. Available for iPad and Mac.
museapp.com
October 20, 2025 at 9:47 PM
Did you know that even when Muse (and half the internet) are offline, you can still access 100% of your data in Muse. Even edit from multiple devices, and everything will sync when the internet comes back online. Keep your notes where you can always see them: museapp.com
Sometimes I cook so that I can listen to a podcast

October 19, 2025 at 5:40 PM
Sometimes I cook so that I can listen to a podcast
Reposted by Ramith Hettiarachchi

The two best days in a Git repo owner’s life are the day they add a submodule and the day they delete it.

time has come when i finally have to use git submodules
October 19, 2025 at 4:23 PM
The two best days in a Git repo owner’s life are the day they add a submodule and the day they delete it.
Reposted by Ramith Hettiarachchi

It's tough to realize you're not good at something,
but it's the first step to improvement.
Acknowledge it, then start working on it.
Appreciate those who are brutally honest with you.
but it's the first step to improvement.
Acknowledge it, then start working on it.
Appreciate those who are brutally honest with you.
October 19, 2025 at 2:57 AM
It's tough to realize you're not good at something,
but it's the first step to improvement.
Acknowledge it, then start working on it.
Appreciate those who are brutally honest with you.
but it's the first step to improvement.
Acknowledge it, then start working on it.
Appreciate those who are brutally honest with you.

Reposted by Ramith Hettiarachchi

Anyone from the Bio community already got their hands on a NVidia DGX Spark for structure prediction and Protein design workloads ?
October 15, 2025 at 5:43 AM
Anyone from the Bio community already got their hands on a NVidia DGX Spark for structure prediction and Protein design workloads ?