



Raj Movva
@rajmovva.bsky.social
NLP, ML & society, healthcare.
PhD student at Berkeley, previously CS at MIT.
https://rajivmovva.com/
PhD student at Berkeley, previously CS at MIT.
https://rajivmovva.com/
This capability of discovering unknown concepts opens many opportunities for applied machine learning. We can design better whitebox predictors, better audit high-stakes models for bias, and generate hypotheses for CSS research. More broadly, SAEs can help bridge the "prediction-explanation" gap.

August 5, 2025 at 4:33 PM
This capability of discovering unknown concepts opens many opportunities for applied machine learning. We can design better whitebox predictors, better audit high-stakes models for bias, and generate hypotheses for CSS research. More broadly, SAEs can help bridge the "prediction-explanation" gap.
These tasks lie in contrast to probing, where we're trying to predict the presence of a *known* concept; and steering, where we're trying to include a *known* concept in an LLM output. SAEs lose to simple baselines on these tasks. (2 good papers on this: "AxBench" and Kantamneni, Engels et al. 2025)


August 5, 2025 at 4:33 PM
These tasks lie in contrast to probing, where we're trying to predict the presence of a *known* concept; and steering, where we're trying to include a *known* concept in an LLM output. SAEs lose to simple baselines on these tasks. (2 good papers on this: "AxBench" and Kantamneni, Engels et al. 2025)
How do we reconcile our view with recent negative results? Our key distinction is that SAEs are useful when you don't know what you're looking for: how does my text classifier predict which headlines will go viral? How does my LLM perform addition? These are "unknown unknowns".

August 5, 2025 at 4:33 PM
How do we reconcile our view with recent negative results? Our key distinction is that SAEs are useful when you don't know what you're looking for: how does my text classifier predict which headlines will go viral? How does my LLM perform addition? These are "unknown unknowns".
📢New POSITION PAPER: Use Sparse Autoencoders to Discover Unknown Concepts, Not to Act on Known Concepts
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵

August 5, 2025 at 4:33 PM
📢New POSITION PAPER: Use Sparse Autoencoders to Discover Unknown Concepts, Not to Act on Known Concepts
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵
It was lots of fun to co-lead this with @kennypeng.bsky.social, with coauthors @nkgarg.bsky.social, Jon Kleinberg, and @emmapierson.bsky.social! Feel free to reach out if we can be helpful. Links:
Draft: arxiv.org/abs/2502.04382
Python package: github.com/rmovva/Hypot...
Demo: hypothesaes.org
9/9
Draft: arxiv.org/abs/2502.04382
Python package: github.com/rmovva/Hypot...
Demo: hypothesaes.org
9/9

March 18, 2025 at 3:17 PM
It was lots of fun to co-lead this with @kennypeng.bsky.social, with coauthors @nkgarg.bsky.social, Jon Kleinberg, and @emmapierson.bsky.social! Feel free to reach out if we can be helpful. Links:
Draft: arxiv.org/abs/2502.04382
Python package: github.com/rmovva/Hypot...
Demo: hypothesaes.org
9/9
Draft: arxiv.org/abs/2502.04382
Python package: github.com/rmovva/Hypot...
Demo: hypothesaes.org
9/9
@kennypeng.bsky.social also built a website to explore results on Yelp, headlines, & Congress datasets: hypothesaes.org.
You can see every SAE neuron in UMAP space, colored by whether the neuron correlates positively or negatively with the target variable. 8/
You can see every SAE neuron in UMAP space, colored by whether the neuron correlates positively or negatively with the target variable. 8/

March 18, 2025 at 3:17 PM
@kennypeng.bsky.social also built a website to explore results on Yelp, headlines, & Congress datasets: hypothesaes.org.
You can see every SAE neuron in UMAP space, colored by whether the neuron correlates positively or negatively with the target variable. 8/
You can see every SAE neuron in UMAP space, colored by whether the neuron correlates positively or negatively with the target variable. 8/
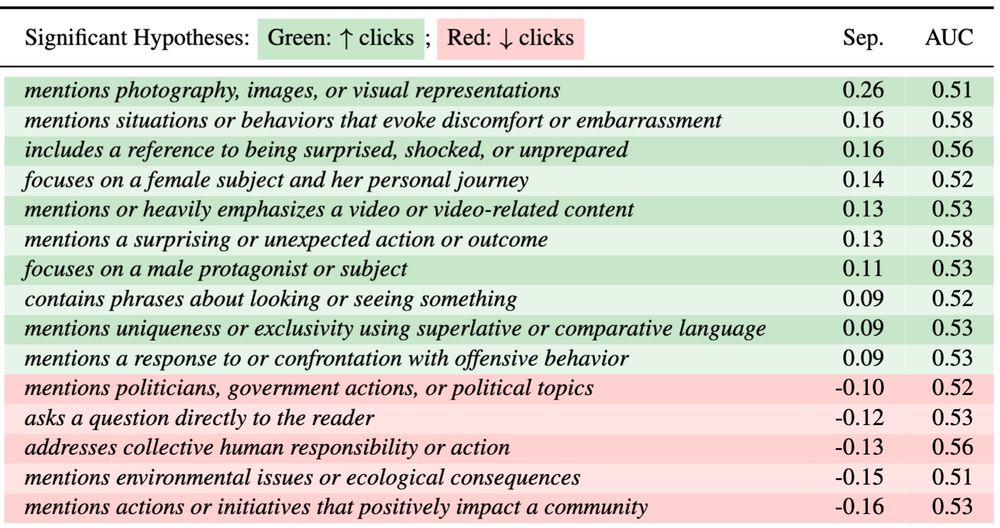
These natural language interpretations are our hypotheses, which we validate on held-out data. On well-studied social science datasets, we add to prior work: for example, we find that news headlines about social issues or the environment decrease engagement. 3/
March 18, 2025 at 3:17 PM
These natural language interpretations are our hypotheses, which we validate on held-out data. On well-studied social science datasets, we add to prior work: for example, we find that news headlines about social issues or the environment decrease engagement. 3/
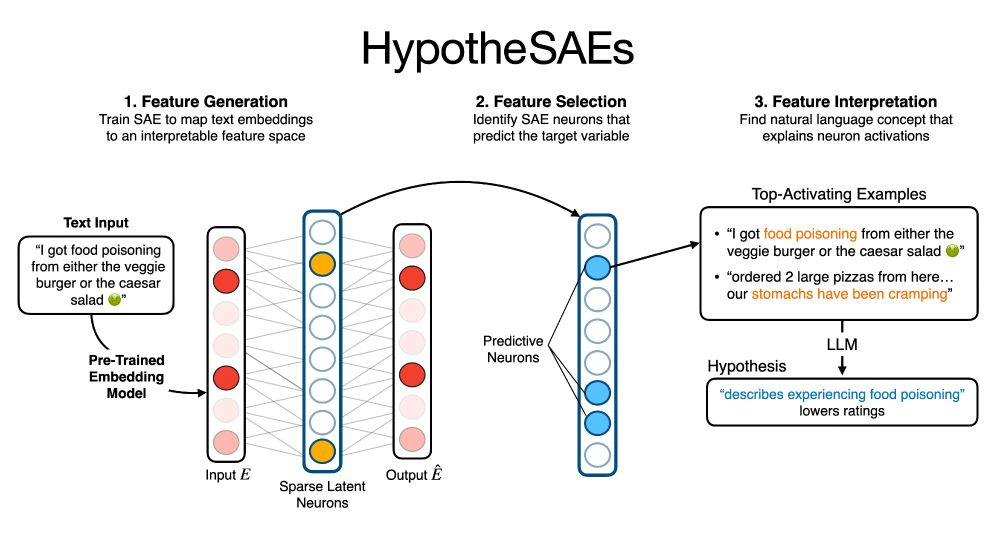
Starting from blackbox text embeddings—which are expressive, but uninterpretable—we (1) use SAEs to map the embeddings to an interpretable space; (2) filter for features that predict the target (engagement, etc.); (3) interpret those features using LLMs. 2/
March 18, 2025 at 3:17 PM
Starting from blackbox text embeddings—which are expressive, but uninterpretable—we (1) use SAEs to map the embeddings to an interpretable space; (2) filter for features that predict the target (engagement, etc.); (3) interpret those features using LLMs. 2/
💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
March 18, 2025 at 3:17 PM
💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
An interesting dynamic on Google reviews is that I tend to trust businesses which write custom replies to negative reviews, even if the reply doesn't really resolve the issue (e.g. see below). I distrust businesses which have stock replies, even if those replies offer to resolve the issue somehow.

March 15, 2025 at 8:57 PM
An interesting dynamic on Google reviews is that I tend to trust businesses which write custom replies to negative reviews, even if the reply doesn't really resolve the issue (e.g. see below). I distrust businesses which have stock replies, even if those replies offer to resolve the issue somehow.