




Prithviraj "Raj" Ammanabrolu
@rajammanabrolu.bsky.social
AI, RL, NLP, Games Asst Prof at UCSD
Research Scientist at Nvidia
Lab: http://pearls.ucsd.edu
Personal: prithvirajva.com
Research Scientist at Nvidia
Lab: http://pearls.ucsd.edu
Personal: prithvirajva.com
I'll be at #CoLM2025 and the IVADO agents workshop right before in Montreal. My students will be presenting two papers in the main conf. I'll also do a ws keynote where I'll talk about some of our latest. Come by and say hi next week!

October 1, 2025 at 5:21 PM
I'll be at #CoLM2025 and the IVADO agents workshop right before in Montreal. My students will be presenting two papers in the main conf. I'll also do a ws keynote where I'll talk about some of our latest. Come by and say hi next week!
I recently left Mosaic/Databricks Research. It's been a ride building out the RL team from <4 ppl to 20+ across two companies & acquisition +figuring out RL as a Service in prod. Mosaic had insane talent density
Some "relaxation" while I put out Prof fires for a smol bit then new adventures!
Some "relaxation" while I put out Prof fires for a smol bit then new adventures!



June 19, 2025 at 3:48 PM
I recently left Mosaic/Databricks Research. It's been a ride building out the RL team from <4 ppl to 20+ across two companies & acquisition +figuring out RL as a Service in prod. Mosaic had insane talent density
Some "relaxation" while I put out Prof fires for a smol bit then new adventures!
Some "relaxation" while I put out Prof fires for a smol bit then new adventures!
The thing that feels so off about the core tech world is that every convo is very transactional. Maybe true elsewhere too. "Oh you're an expert in RL, can you answer questions about my new startup?"
Every single (Bay) party. No I do not want to consult. I just wanna hang out.
Every single (Bay) party. No I do not want to consult. I just wanna hang out.

June 16, 2025 at 5:54 AM
The thing that feels so off about the core tech world is that every convo is very transactional. Maybe true elsewhere too. "Oh you're an expert in RL, can you answer questions about my new startup?"
Every single (Bay) party. No I do not want to consult. I just wanna hang out.
Every single (Bay) party. No I do not want to consult. I just wanna hang out.
Looks like Gemini gets AIR 6 in #JEE2025 with a score of 323
Only 5 highschoolers in all India do better than an LLM in the single most important exam of their to get into the IITs
The legacy edu selection systems are now worse than useless
Only 5 highschoolers in all India do better than an LLM in the single most important exam of their to get into the IITs
The legacy edu selection systems are now worse than useless


June 2, 2025 at 6:54 AM
Looks like Gemini gets AIR 6 in #JEE2025 with a score of 323
Only 5 highschoolers in all India do better than an LLM in the single most important exam of their to get into the IITs
The legacy edu selection systems are now worse than useless
Only 5 highschoolers in all India do better than an LLM in the single most important exam of their to get into the IITs
The legacy edu selection systems are now worse than useless
Here for the afternoon shift!

May 24, 2025 at 9:06 PM
Here for the afternoon shift!
But even then agents only perform well up to 130k after which perf sharply decreases and all architectures and additional context extension methods we modified fail after ~400k. None make it to the 3m context sample test set we use let alone infinite. Lots of space for progress!



May 23, 2025 at 4:08 PM
But even then agents only perform well up to 130k after which perf sharply decreases and all architectures and additional context extension methods we modified fail after ~400k. None make it to the 3m context sample test set we use let alone infinite. Lots of space for progress!
And find that when accounting for hardware constraints, only a specific combo of interleaved VLA with a mix of context parallelism + some extension with high pre training context window size works well. We detail the exact architecture and describe potential improvements

May 23, 2025 at 4:08 PM
And find that when accounting for hardware constraints, only a specific combo of interleaved VLA with a mix of context parallelism + some extension with high pre training context window size works well. We detail the exact architecture and describe potential improvements
The first is a static eval called Needle(s) in the Embodied Haystack, which is like QA asking agents to post hoc analyze their trajectories putting many needles together
We then go Beyond this with interactive RL style evals to see how well models interact with a changing env
We then go Beyond this with interactive RL style evals to see how well models interact with a changing env

May 23, 2025 at 4:08 PM
The first is a static eval called Needle(s) in the Embodied Haystack, which is like QA asking agents to post hoc analyze their trajectories putting many needles together
We then go Beyond this with interactive RL style evals to see how well models interact with a changing env
We then go Beyond this with interactive RL style evals to see how well models interact with a changing env
So we first extended AI2's THOR embodied sim to continue generating meaningful tasks that are effectively infinite in length. Eg things you do at context len 7k can get reused at 3m
We do a thorough analysis of many types of architectures x training methods on two new evals
We do a thorough analysis of many types of architectures x training methods on two new evals

May 23, 2025 at 4:08 PM
So we first extended AI2's THOR embodied sim to continue generating meaningful tasks that are effectively infinite in length. Eg things you do at context len 7k can get reused at 3m
We do a thorough analysis of many types of architectures x training methods on two new evals
We do a thorough analysis of many types of architectures x training methods on two new evals
"Foundation" models for embodied agents are all the rage but how to actually do complex looong context reasoning? Can we scale Beyond Needle(s) in the (Embodied) Haystack?
∞-THOR is an infinite len sim framework + guide on (new) architectures/training methods for VLA models
∞-THOR is an infinite len sim framework + guide on (new) architectures/training methods for VLA models
May 23, 2025 at 4:08 PM
"Foundation" models for embodied agents are all the rage but how to actually do complex looong context reasoning? Can we scale Beyond Needle(s) in the (Embodied) Haystack?
∞-THOR is an infinite len sim framework + guide on (new) architectures/training methods for VLA models
∞-THOR is an infinite len sim framework + guide on (new) architectures/training methods for VLA models
I like the Ultra Scale Playbook from Huggingface and give it to my MS/first year PhD students to read as a prereq huggingface.co/spaces/nanot...
Is there a "RLSys" version of this on scaling RL+LLM training? If not + there's OSS community interest, I'll prob write one?
Is there a "RLSys" version of this on scaling RL+LLM training? If not + there's OSS community interest, I'll prob write one?

May 15, 2025 at 4:39 PM
I like the Ultra Scale Playbook from Huggingface and give it to my MS/first year PhD students to read as a prereq huggingface.co/spaces/nanot...
Is there a "RLSys" version of this on scaling RL+LLM training? If not + there's OSS community interest, I'll prob write one?
Is there a "RLSys" version of this on scaling RL+LLM training? If not + there's OSS community interest, I'll prob write one?
that's what's hot


May 14, 2025 at 12:31 AM
that's what's hot
If... circumstances ... were different maybe I'd enjoy the other stuff like fund raising more too but right now

May 8, 2025 at 9:47 PM
If... circumstances ... were different maybe I'd enjoy the other stuff like fund raising more too but right now
This is reasonably written and echoes many of my own fears. The upside of AI is too huge to pass up but also there's a high chance that the vast majority of humanity is on track to becoming economically obsolete without really any transition plan www.theguardian.com/books/2025/m...

May 7, 2025 at 7:35 PM
This is reasonably written and echoes many of my own fears. The upside of AI is too huge to pass up but also there's a high chance that the vast majority of humanity is on track to becoming economically obsolete without really any transition plan www.theguardian.com/books/2025/m...
Cool looking paper from @markriedl.bsky.social's lab arxiv.org/abs/2505.03547 making significant improvements over our arxiv.org/abs/2001.10161 from 5+ years ago


May 7, 2025 at 5:10 AM
Cool looking paper from @markriedl.bsky.social's lab arxiv.org/abs/2505.03547 making significant improvements over our arxiv.org/abs/2001.10161 from 5+ years ago
Fascinating read as an outsider to *CL all grad school www.quantamagazine.org/when-chatgpt...
Things I hear a lot "no one thought next token pred would work, or RL on language, etc". But that's just not true, there were def ppl working on them (just weren't taken seriously by some communities)
Things I hear a lot "no one thought next token pred would work, or RL on language, etc". But that's just not true, there were def ppl working on them (just weren't taken seriously by some communities)

May 1, 2025 at 11:00 PM
Fascinating read as an outsider to *CL all grad school www.quantamagazine.org/when-chatgpt...
Things I hear a lot "no one thought next token pred would work, or RL on language, etc". But that's just not true, there were def ppl working on them (just weren't taken seriously by some communities)
Things I hear a lot "no one thought next token pred would work, or RL on language, etc". But that's just not true, there were def ppl working on them (just weren't taken seriously by some communities)
All our tasks are designed so that you need at least two agents, in fact the more agents the faster you can theoretically finish a task!
Despite this, we find that no existing agent right now is able to effectively collaborate, communication coordination is out of reach!
Despite this, we find that no existing agent right now is able to effectively collaborate, communication coordination is out of reach!

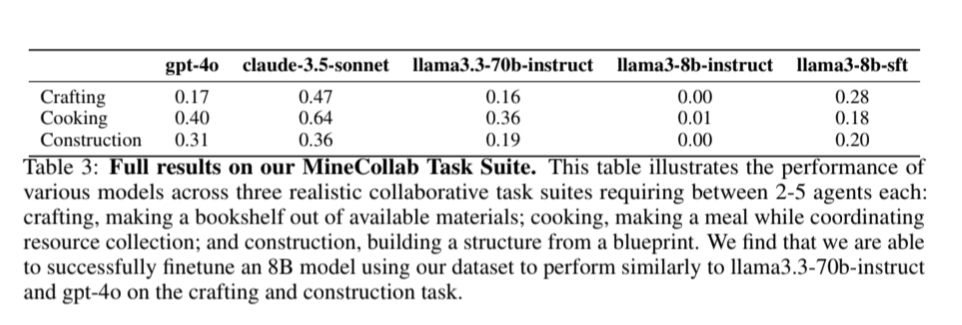
April 28, 2025 at 3:07 PM
All our tasks are designed so that you need at least two agents, in fact the more agents the faster you can theoretically finish a task!
Despite this, we find that no existing agent right now is able to effectively collaborate, communication coordination is out of reach!
Despite this, we find that no existing agent right now is able to effectively collaborate, communication coordination is out of reach!
MINDcraft lets users and LLMs interact with embodied envs with a mix of high and low level actions. Tool use + acquisition, goal / open ended learning + more
In particular in our benchmark MineCollab we test multi agent collaboration in cooking, crafting, and construction
In particular in our benchmark MineCollab we test multi agent collaboration in cooking, crafting, and construction

April 28, 2025 at 3:07 PM
MINDcraft lets users and LLMs interact with embodied envs with a mix of high and low level actions. Tool use + acquisition, goal / open ended learning + more
In particular in our benchmark MineCollab we test multi agent collaboration in cooking, crafting, and construction
In particular in our benchmark MineCollab we test multi agent collaboration in cooking, crafting, and construction
MINDcraft is special as it has already existed as OSS on GitHub for a while and built up a great community of thousands of users, sparking many unique benchmarks. Today we bring it to the AI/RL/LLM research communities as a scientifically rigorous env
github.com/kolbytn/mind...
github.com/kolbytn/mind...



April 28, 2025 at 3:07 PM
MINDcraft is special as it has already existed as OSS on GitHub for a while and built up a great community of thousands of users, sparking many unique benchmarks. Today we bring it to the AI/RL/LLM research communities as a scientifically rigorous env
github.com/kolbytn/mind...
github.com/kolbytn/mind...
The future of embodied AI revolves around *collaborative* multi agent scenarios that need natural language communication, task delegation, resource sharing, and more
⛏️ Here are MINDcraft and MineCollab, a simulator and benchmark purpose built to enable research in this area!
⛏️ Here are MINDcraft and MineCollab, a simulator and benchmark purpose built to enable research in this area!
April 28, 2025 at 3:07 PM
The future of embodied AI revolves around *collaborative* multi agent scenarios that need natural language communication, task delegation, resource sharing, and more
⛏️ Here are MINDcraft and MineCollab, a simulator and benchmark purpose built to enable research in this area!
⛏️ Here are MINDcraft and MineCollab, a simulator and benchmark purpose built to enable research in this area!
We test both online and offline versions of IRPO against relevant baselines like Policy Gradients, DPO, and Iterative DPO - finding it works better across a range of tasks


April 23, 2025 at 4:06 PM
We test both online and offline versions of IRPO against relevant baselines like Policy Gradients, DPO, and Iterative DPO - finding it works better across a range of tasks
It's *PO'clock, this time IRPO In-Context Ranking Policy Optimization!
An RL algorithm inspired by trad retrieval that trains agents to more effectively use lists of documents in context for better multi-hop {QA, agentic tasks, and more}!
An RL algorithm inspired by trad retrieval that trains agents to more effectively use lists of documents in context for better multi-hop {QA, agentic tasks, and more}!

April 23, 2025 at 4:06 PM
It's *PO'clock, this time IRPO In-Context Ranking Policy Optimization!
An RL algorithm inspired by trad retrieval that trains agents to more effectively use lists of documents in context for better multi-hop {QA, agentic tasks, and more}!
An RL algorithm inspired by trad retrieval that trains agents to more effectively use lists of documents in context for better multi-hop {QA, agentic tasks, and more}!

Text games are some of the most cognitively complex tasks out there requiring thousands of perfectly executed actions to complete
SOTA LLM agents are ok at synthetically (procedurally) generated tasks, but get at most *13%* on human made ones
👨💻github.com/microsoft/tale-suite
SOTA LLM agents are ok at synthetically (procedurally) generated tasks, but get at most *13%* on human made ones
👨💻github.com/microsoft/tale-suite

April 22, 2025 at 6:43 PM
Text games are some of the most cognitively complex tasks out there requiring thousands of perfectly executed actions to complete
SOTA LLM agents are ok at synthetically (procedurally) generated tasks, but get at most *13%* on human made ones
👨💻github.com/microsoft/tale-suite
SOTA LLM agents are ok at synthetically (procedurally) generated tasks, but get at most *13%* on human made ones
👨💻github.com/microsoft/tale-suite
Introducing TALES - Text Adventure Learning Environment Suite
A benchmark of a few hundred text envs: science experiments and embodied cooking to solving murder mysteries. We test over 30 of the best LLM agents and pinpoint failure modes +how to improve
👨💻pip install tale-suite
A benchmark of a few hundred text envs: science experiments and embodied cooking to solving murder mysteries. We test over 30 of the best LLM agents and pinpoint failure modes +how to improve
👨💻pip install tale-suite
April 22, 2025 at 6:43 PM
Introducing TALES - Text Adventure Learning Environment Suite
A benchmark of a few hundred text envs: science experiments and embodied cooking to solving murder mysteries. We test over 30 of the best LLM agents and pinpoint failure modes +how to improve
👨💻pip install tale-suite
A benchmark of a few hundred text envs: science experiments and embodied cooking to solving murder mysteries. We test over 30 of the best LLM agents and pinpoint failure modes +how to improve
👨💻pip install tale-suite