




Akarshan Biswas
@qnixsynapse.bsky.social
Stalking on ML updates.
Engineering inference @ Menlo
Engineering inference @ Menlo
Reposted by Akarshan Biswas

Speechless: instruction tuning for speech, without speech.
We're releasing new models, datasets, and a method for training speech instruction models without using any audio data. No waveforms, no TTS.
Links below.
We're releasing new models, datasets, and a method for training speech instruction models without using any audio data. No waveforms, no TTS.
Links below.

May 26, 2025 at 4:58 AM
Speechless: instruction tuning for speech, without speech.
We're releasing new models, datasets, and a method for training speech instruction models without using any audio data. No waveforms, no TTS.
Links below.
We're releasing new models, datasets, and a method for training speech instruction models without using any audio data. No waveforms, no TTS.
Links below.
Introducing AlphaMaze,
a model that enables LLMs to solve mazes and think visually. By combining synthetic reasoning data, fine-tuning, and GRPO, the research team at Menlo Research has successfully trained a model that can navigate spatial reasoning tasks. #ML #RL
www.youtube.com/watch?v=dUS9...
a model that enables LLMs to solve mazes and think visually. By combining synthetic reasoning data, fine-tuning, and GRPO, the research team at Menlo Research has successfully trained a model that can navigate spatial reasoning tasks. #ML #RL
www.youtube.com/watch?v=dUS9...

AlphaMaze: LLM Visual Reasoning with GRPO (Feb 13 2025)
YouTube video by Menlo Research
www.youtube.com
February 21, 2025 at 3:30 PM
Introducing AlphaMaze,
a model that enables LLMs to solve mazes and think visually. By combining synthetic reasoning data, fine-tuning, and GRPO, the research team at Menlo Research has successfully trained a model that can navigate spatial reasoning tasks. #ML #RL
www.youtube.com/watch?v=dUS9...
a model that enables LLMs to solve mazes and think visually. By combining synthetic reasoning data, fine-tuning, and GRPO, the research team at Menlo Research has successfully trained a model that can navigate spatial reasoning tasks. #ML #RL
www.youtube.com/watch?v=dUS9...
Reposted by Akarshan Biswas

It's 2025, and I’ve finally updated my Python setup guide to use uv + venv instead of conda + pip!
Here's my go-to recommendation for uv + venv in Python projects for faster installs, better dependency management: github.com/rasbt/LLMs-f...
(Any additional suggestions?)
Here's my go-to recommendation for uv + venv in Python projects for faster installs, better dependency management: github.com/rasbt/LLMs-f...
(Any additional suggestions?)
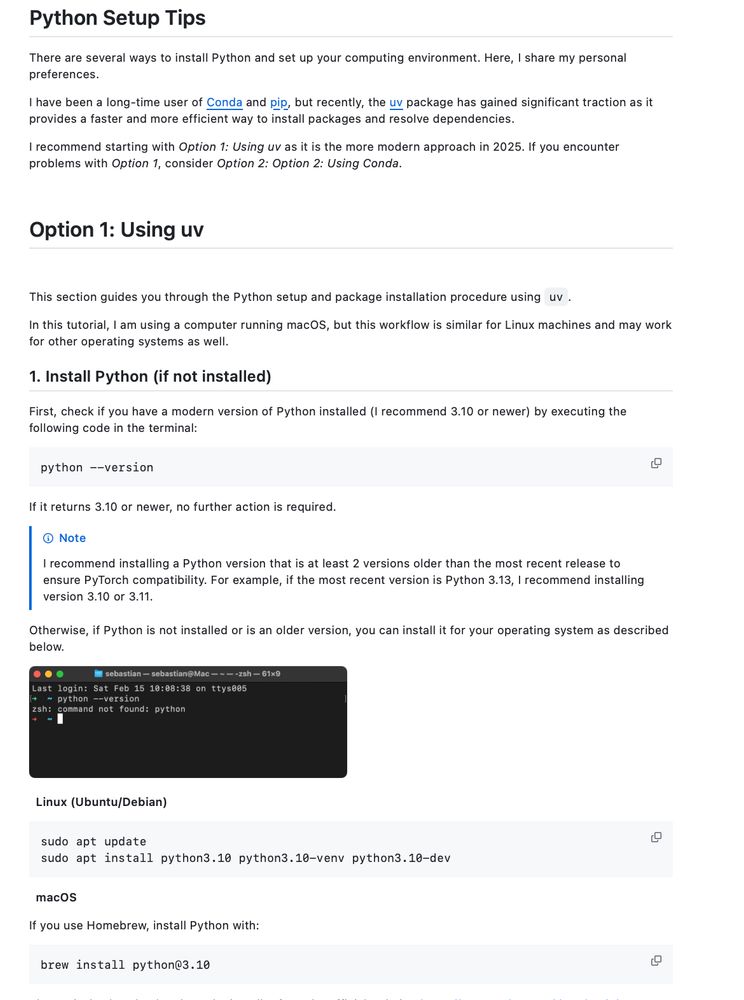
February 15, 2025 at 7:14 PM
It's 2025, and I’ve finally updated my Python setup guide to use uv + venv instead of conda + pip!
Here's my go-to recommendation for uv + venv in Python projects for faster installs, better dependency management: github.com/rasbt/LLMs-f...
(Any additional suggestions?)
Here's my go-to recommendation for uv + venv in Python projects for faster installs, better dependency management: github.com/rasbt/LLMs-f...
(Any additional suggestions?)
Reposted by Akarshan Biswas

Delighted to be a minor co-author on this work, led by
Pranav Nair: Combining losses for different Matyroshka-nested groups of bits in each weight within a neural network leads to an accuracy improvement for models (esp. 2-bit reps).
Paper: "Matryoshka Quantization" at arxiv.org/abs/2502.06786
Pranav Nair: Combining losses for different Matyroshka-nested groups of bits in each weight within a neural network leads to an accuracy improvement for models (esp. 2-bit reps).
Paper: "Matryoshka Quantization" at arxiv.org/abs/2502.06786

February 11, 2025 at 5:41 PM
Delighted to be a minor co-author on this work, led by
Pranav Nair: Combining losses for different Matyroshka-nested groups of bits in each weight within a neural network leads to an accuracy improvement for models (esp. 2-bit reps).
Paper: "Matryoshka Quantization" at arxiv.org/abs/2502.06786
Pranav Nair: Combining losses for different Matyroshka-nested groups of bits in each weight within a neural network leads to an accuracy improvement for models (esp. 2-bit reps).
Paper: "Matryoshka Quantization" at arxiv.org/abs/2502.06786
Reposted by Akarshan Biswas

OpenR: Can 1B LLM Surpass 405B LLM?
"A 1B LLM can exceed a 405B LLM on MATH-500. Moreover, on both MATH-500 and AIME24, a 0.5B LLM outperforms GPT-4o, a 3B LLM surpasses a 405B LLM, and a 7B LLM beats o1 and DeepSeek-R1, while with higher inference efficiency."
"A 1B LLM can exceed a 405B LLM on MATH-500. Moreover, on both MATH-500 and AIME24, a 0.5B LLM outperforms GPT-4o, a 3B LLM surpasses a 405B LLM, and a 7B LLM beats o1 and DeepSeek-R1, while with higher inference efficiency."
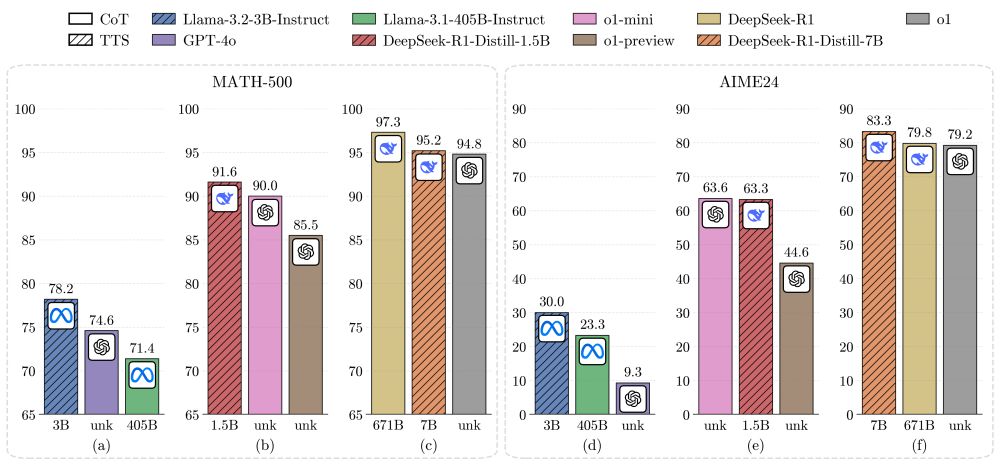
February 11, 2025 at 7:51 AM
OpenR: Can 1B LLM Surpass 405B LLM?
"A 1B LLM can exceed a 405B LLM on MATH-500. Moreover, on both MATH-500 and AIME24, a 0.5B LLM outperforms GPT-4o, a 3B LLM surpasses a 405B LLM, and a 7B LLM beats o1 and DeepSeek-R1, while with higher inference efficiency."
"A 1B LLM can exceed a 405B LLM on MATH-500. Moreover, on both MATH-500 and AIME24, a 0.5B LLM outperforms GPT-4o, a 3B LLM surpasses a 405B LLM, and a 7B LLM beats o1 and DeepSeek-R1, while with higher inference efficiency."
Excellent video!
www.youtube.com/watch?v=P_fH...
www.youtube.com/watch?v=P_fH...

What if all the world's biggest problems have the same solution?
YouTube video by Veritasium
www.youtube.com
February 10, 2025 at 3:06 PM
Excellent video!
www.youtube.com/watch?v=P_fH...
www.youtube.com/watch?v=P_fH...
Reposted by Akarshan Biswas

…there is a wrinkle, at least for the version of Gemini that runs on web searches… Google’s summary snippet of cheese dot com provides the 50-60% consumption numbers. But it is nowhere in the actual article…

February 7, 2025 at 12:30 PM
…there is a wrinkle, at least for the version of Gemini that runs on web searches… Google’s summary snippet of cheese dot com provides the 50-60% consumption numbers. But it is nowhere in the actual article…
LLMs will hallucinate. To mitagate this you would need massive amounts of RL(with reasoning before final response). Gemini by default, doesn't do that. Gemini flash thinking "experimental" model uses prompting techniques to generate the "thinking process" before generating a response.

"The commercial - which was supposed to showcase Gemini's abilities - was created to be broadcast during the Super Bowl.
It showed the tool helping a cheesemonger in Wisconsin write a product description by informing him Gouda accounts for '50 to 60 percent of global cheese consumption'."
It showed the tool helping a cheesemonger in Wisconsin write a product description by informing him Gouda accounts for '50 to 60 percent of global cheese consumption'."

Google remakes Super Bowl ad after AI cheese gaffe
Its Gemini tool wildly overestimated global gouda consumption in ad that was meant to show off its capabilities.
www.bbc.com
February 7, 2025 at 12:40 PM
LLMs will hallucinate. To mitagate this you would need massive amounts of RL(with reasoning before final response). Gemini by default, doesn't do that. Gemini flash thinking "experimental" model uses prompting techniques to generate the "thinking process" before generating a response.
Reposted by Akarshan Biswas

You can now reproduce DeepSeek-R1's reasoning on your own local device!
Experience the "Aha" moment with just 7GB VRAM.
Unsloth reduces GRPO training memory use by 80%.
15GB VRAM can transform Llama-3.1 (8B) & Phi-4 (14B) into reasoning models.
Blog: unsloth.ai/blog/r1-reas...
Experience the "Aha" moment with just 7GB VRAM.
Unsloth reduces GRPO training memory use by 80%.
15GB VRAM can transform Llama-3.1 (8B) & Phi-4 (14B) into reasoning models.
Blog: unsloth.ai/blog/r1-reas...

February 6, 2025 at 6:09 PM
You can now reproduce DeepSeek-R1's reasoning on your own local device!
Experience the "Aha" moment with just 7GB VRAM.
Unsloth reduces GRPO training memory use by 80%.
15GB VRAM can transform Llama-3.1 (8B) & Phi-4 (14B) into reasoning models.
Blog: unsloth.ai/blog/r1-reas...
Experience the "Aha" moment with just 7GB VRAM.
Unsloth reduces GRPO training memory use by 80%.
15GB VRAM can transform Llama-3.1 (8B) & Phi-4 (14B) into reasoning models.
Blog: unsloth.ai/blog/r1-reas...
Reposted by Akarshan Biswas
Ladder-residual
A parallelism-aware architecture modification that makes 70B Llama with tensor parallelism ~30% faster!
Paper: arxiv.org/abs/2501.06589
A parallelism-aware architecture modification that makes 70B Llama with tensor parallelism ~30% faster!
Paper: arxiv.org/abs/2501.06589

February 5, 2025 at 7:47 AM
Ladder-residual
A parallelism-aware architecture modification that makes 70B Llama with tensor parallelism ~30% faster!
Paper: arxiv.org/abs/2501.06589
A parallelism-aware architecture modification that makes 70B Llama with tensor parallelism ~30% faster!
Paper: arxiv.org/abs/2501.06589
Reposted by Akarshan Biswas

Announcing Aya 23, a state-of-the-art multilingual 8B and 35B open weights release.
Aya 23 pairs a highly performant pre-trained model with the recent Aya dataset, making multilingual generative AI breakthroughs accessible to the research community. 🌍
arxiv.org/abs/2405.15032
Aya 23 pairs a highly performant pre-trained model with the recent Aya dataset, making multilingual generative AI breakthroughs accessible to the research community. 🌍
arxiv.org/abs/2405.15032

February 4, 2025 at 3:04 PM
Announcing Aya 23, a state-of-the-art multilingual 8B and 35B open weights release.
Aya 23 pairs a highly performant pre-trained model with the recent Aya dataset, making multilingual generative AI breakthroughs accessible to the research community. 🌍
arxiv.org/abs/2405.15032
Aya 23 pairs a highly performant pre-trained model with the recent Aya dataset, making multilingual generative AI breakthroughs accessible to the research community. 🌍
arxiv.org/abs/2405.15032

Reposted by Akarshan Biswas

Yes! a 15-min-read post to catch up on all experiments, reproductions, explorations around DeepSeek R1
We've summarized everything we did & saw in this first week since DS came to light
Results/code/dataset/experiment => if we missed one, share & we'll update
Link: huggingface.co/blog/open-r1...
We've summarized everything we did & saw in this first week since DS came to light
Results/code/dataset/experiment => if we missed one, share & we'll update
Link: huggingface.co/blog/open-r1...

Open-R1: Update #1
A Blog post by Open R1 on Hugging Face
huggingface.co
February 2, 2025 at 9:49 AM
Yes! a 15-min-read post to catch up on all experiments, reproductions, explorations around DeepSeek R1
We've summarized everything we did & saw in this first week since DS came to light
Results/code/dataset/experiment => if we missed one, share & we'll update
Link: huggingface.co/blog/open-r1...
We've summarized everything we did & saw in this first week since DS came to light
Results/code/dataset/experiment => if we missed one, share & we'll update
Link: huggingface.co/blog/open-r1...
Reposted by Akarshan Biswas
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
- RL generalizes in rule-based envs, esp. when trained with an outcome-based reward
- SFT tends to memorize the training data and struggles to generalize OOD
- RL generalizes in rule-based envs, esp. when trained with an outcome-based reward
- SFT tends to memorize the training data and struggles to generalize OOD

January 29, 2025 at 1:43 PM
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
- RL generalizes in rule-based envs, esp. when trained with an outcome-based reward
- SFT tends to memorize the training data and struggles to generalize OOD
- RL generalizes in rule-based envs, esp. when trained with an outcome-based reward
- SFT tends to memorize the training data and struggles to generalize OOD
Reposted by Akarshan Biswas
A GRPO demo (gist) code by Will Brown.
It is running smoothly on Qwen-1.5B w/ longer max_completion_length + higher num_generations, but haven't gotten LoRA or grad checkpointing working on multi-gpu w/ deepspeed yet for it.
gist.github.com/willccbb/467...
It is running smoothly on Qwen-1.5B w/ longer max_completion_length + higher num_generations, but haven't gotten LoRA or grad checkpointing working on multi-gpu w/ deepspeed yet for it.
gist.github.com/willccbb/467...

GRPO Llama-1B
GRPO Llama-1B. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
January 29, 2025 at 6:43 AM
A GRPO demo (gist) code by Will Brown.
It is running smoothly on Qwen-1.5B w/ longer max_completion_length + higher num_generations, but haven't gotten LoRA or grad checkpointing working on multi-gpu w/ deepspeed yet for it.
gist.github.com/willccbb/467...
It is running smoothly on Qwen-1.5B w/ longer max_completion_length + higher num_generations, but haven't gotten LoRA or grad checkpointing working on multi-gpu w/ deepspeed yet for it.
gist.github.com/willccbb/467...
"That's intense" 😂

January 28, 2025 at 3:25 PM
"That's intense" 😂
IMO, he isn't wrong here. Converting model thoughts to "human readable tokens" using an "unembedding matrix" is a very expensive process. This matrix is very large (dim X size of vocabulary) which is costlier than feeding the raw embeddings directly(For example: refer COCONUT paper).
sam altman’s quote about losing money on o1-pro never struck me as innocent honesty as it did to seemingly everyone else on the internet. he was clearly up to something, i didn’t know what it was then, and i still don’t claim to know now. the guy is fishy af

I claimed a month ago that Sam Altman’s arm flailing of how they’re losing money on the $200-a-month plan was more price positioning than a statement of desperation.
The test for whether that’s true is whether OpenAI is relieved or not at the advent of DeepSeek.
The test for whether that’s true is whether OpenAI is relieved or not at the advent of DeepSeek.
January 28, 2025 at 3:00 AM
IMO, he isn't wrong here. Converting model thoughts to "human readable tokens" using an "unembedding matrix" is a very expensive process. This matrix is very large (dim X size of vocabulary) which is costlier than feeding the raw embeddings directly(For example: refer COCONUT paper).
Reposted by Akarshan Biswas
LOL. We may need to look for a new profession, as posted by Georgi Gerganov ( @ggerganov on X )
Paraphrasing him where he jokingly stated - "pack it up boys, it's over"
Source: github.com/ggerganov/ll...
Paraphrasing him where he jokingly stated - "pack it up boys, it's over"
Source: github.com/ggerganov/ll...

January 27, 2025 at 5:41 PM
LOL. We may need to look for a new profession, as posted by Georgi Gerganov ( @ggerganov on X )
Paraphrasing him where he jokingly stated - "pack it up boys, it's over"
Source: github.com/ggerganov/ll...
Paraphrasing him where he jokingly stated - "pack it up boys, it's over"
Source: github.com/ggerganov/ll...
I haven't seen this level of roast in my life LOL. 😂

January 27, 2025 at 3:29 PM
I haven't seen this level of roast in my life LOL. 😂

Reposted by Akarshan Biswas

apparently RLCoT (chain of thought learned via RL) is in itself an emergent behavior that doesn’t happen until about 1.5B sized models
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...

jiayipan
Weights & Biases, developer tools for machine learning
wandb.ai
January 25, 2025 at 6:46 PM
apparently RLCoT (chain of thought learned via RL) is in itself an emergent behavior that doesn’t happen until about 1.5B sized models
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...
PPO, GPRO, PRIME — doesn’t matter what RL you use, the key is that it’s RL
experiment logs: wandb.ai/jiayipan/Tin...
x: x.com/jiayi_pirate...
Reposted by Akarshan Biswas
an open source 7B replication of R1-zero and R1
notable: they claim they developed in parallel and that most of their experiments were performed *prior to* the release of R1 and they came to the same conclusions
hkust-nlp.notion.site/simplerl-rea...
notable: they claim they developed in parallel and that most of their experiments were performed *prior to* the release of R1 and they came to the same conclusions
hkust-nlp.notion.site/simplerl-rea...

7B Model and 8K Examples: Emerging Reasoning with Reinforcement Learning is Both Effective and Efficient | Notion
A replication of DeepSeek-R1 training on small models with limited data
hkust-nlp.notion.site
January 25, 2025 at 4:33 PM
an open source 7B replication of R1-zero and R1
notable: they claim they developed in parallel and that most of their experiments were performed *prior to* the release of R1 and they came to the same conclusions
hkust-nlp.notion.site/simplerl-rea...
notable: they claim they developed in parallel and that most of their experiments were performed *prior to* the release of R1 and they came to the same conclusions
hkust-nlp.notion.site/simplerl-rea...
Reposted by Akarshan Biswas

Want to dive deeper? Check out our paper and our blog posts explaining the work in more detail
📄 Paper: arxiv.org/abs/2501.13011
💡 Introductory explainer: deepmindsafetyresearch.medium.com/mona-a-meth...
⚙️ Technical safety post: www.alignmentforum.org/posts/zWySW...
📄 Paper: arxiv.org/abs/2501.13011
💡 Introductory explainer: deepmindsafetyresearch.medium.com/mona-a-meth...
⚙️ Technical safety post: www.alignmentforum.org/posts/zWySW...

January 23, 2025 at 3:33 PM
Want to dive deeper? Check out our paper and our blog posts explaining the work in more detail
📄 Paper: arxiv.org/abs/2501.13011
💡 Introductory explainer: deepmindsafetyresearch.medium.com/mona-a-meth...
⚙️ Technical safety post: www.alignmentforum.org/posts/zWySW...
📄 Paper: arxiv.org/abs/2501.13011
💡 Introductory explainer: deepmindsafetyresearch.medium.com/mona-a-meth...
⚙️ Technical safety post: www.alignmentforum.org/posts/zWySW...
Do LLMs have concept of time?
January 24, 2025 at 2:43 AM
Do LLMs have concept of time?
The media in India is hilarious man! And no, here Gemma isn't making things up.


January 23, 2025 at 1:42 PM
The media in India is hilarious man! And no, here Gemma isn't making things up.