



Qihong (Q) Lu
@qlu.bsky.social
Computational models of episodic memory
Postdoc with Daphna Shohamy & Stefano Fusi @ Columbia
PhD with Ken Norman & Uri Hasson @ Princeton
https://qihongl.github.io/
Postdoc with Daphna Shohamy & Stefano Fusi @ Columbia
PhD with Ken Norman & Uri Hasson @ Princeton
https://qihongl.github.io/
had so much fun hanging out with Uri in Hong Kong 😆

June 8, 2025 at 2:22 PM
had so much fun hanging out with Uri in Hong Kong 😆
I’d like to share some slides and code for a “Memory Model 101 workshop” I gave recently, which has some minimal examples to illustrate the Rumelhart network & catastrophic interference :)
slides: shorturl.at/q2iKq
code (with colab support!): github.com/qihongl/demo...
slides: shorturl.at/q2iKq
code (with colab support!): github.com/qihongl/demo...
May 26, 2025 at 11:56 AM
I’d like to share some slides and code for a “Memory Model 101 workshop” I gave recently, which has some minimal examples to illustrate the Rumelhart network & catastrophic interference :)
slides: shorturl.at/q2iKq
code (with colab support!): github.com/qihongl/demo...
slides: shorturl.at/q2iKq
code (with colab support!): github.com/qihongl/demo...
City U of HK is a great university and an English-speaking environment!
More generally, HK is very English-friendly (I use English there, too) and a fun place to live!
(2/5)
More generally, HK is very English-friendly (I use English there, too) and a fun place to live!
(2/5)

May 8, 2025 at 1:16 AM
City U of HK is a great university and an English-speaking environment!
More generally, HK is very English-friendly (I use English there, too) and a fun place to live!
(2/5)
More generally, HK is very English-friendly (I use English there, too) and a fun place to live!
(2/5)
In simulation 2, the model had to learn 12 classification tasks that varied along a ring manifold. Models with EM learned the ring. Again, models without EM suffered from excessive representation drift, which hindered learning.

May 7, 2024 at 1:14 PM
In simulation 2, the model had to learn 12 classification tasks that varied along a ring manifold. Models with EM learned the ring. Again, models without EM suffered from excessive representation drift, which hindered learning.
… this is because encoding and retrieving TRs in EM can reduce representation drift, which facilitates learning. Without EM, “good representation” for the ongoing task is often non-unique, leading to unnecessary TR drift – change in TRs after performance converges.

May 7, 2024 at 1:14 PM
… this is because encoding and retrieving TRs in EM can reduce representation drift, which facilitates learning. Without EM, “good representation” for the ongoing task is often non-unique, leading to unnecessary TR drift – change in TRs after performance converges.
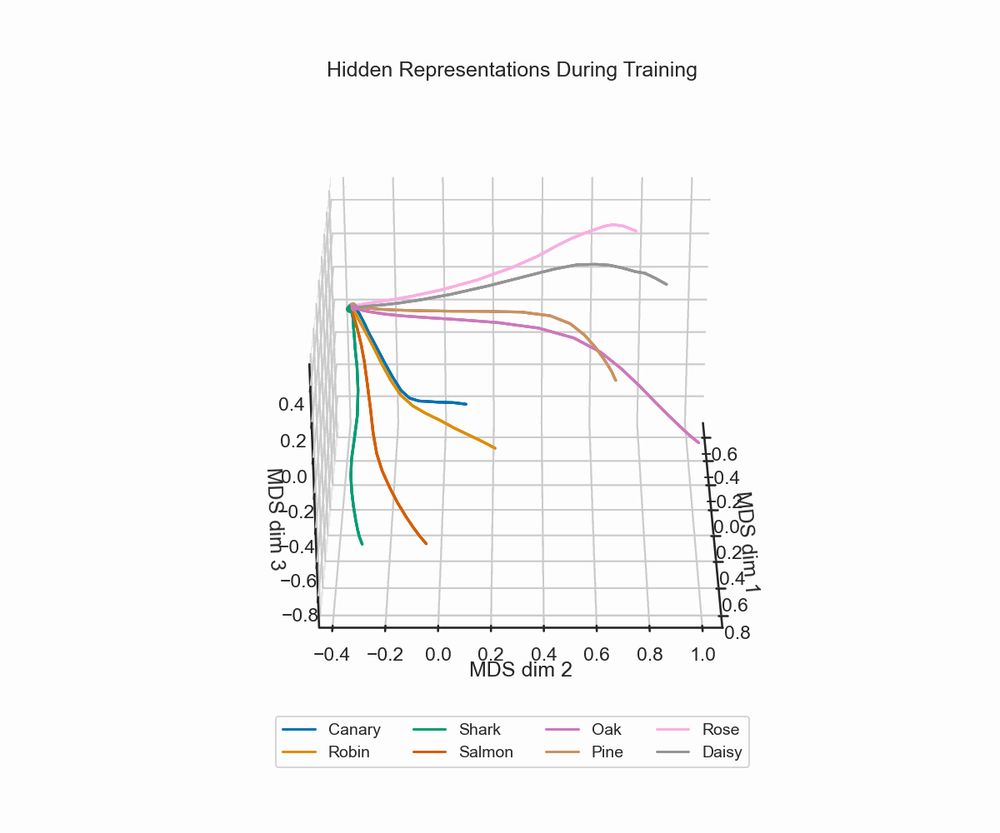
In simulation 1, the model had to learn 8 sequence prediction tasks that varied along 3 independent feature dimensions. Models with EM learned to represent the 3 dims in abstract format (Bernardi 2020)...

May 7, 2024 at 1:14 PM
In simulation 1, the model had to learn 8 sequence prediction tasks that varied along 3 independent feature dimensions. Models with EM learned to represent the 3 dims in abstract format (Bernardi 2020)...
We developed an NN model augmented with a task representation (TR) layer and an episodic memory (EM) buffer. It uses EM to retrieve and encode TRs, so when it searches for a TR online (Giallanza 2023; Hummos 2022), it can retrieve previously used TRs from EM.
1/n
1/n

May 7, 2024 at 1:13 PM
We developed an NN model augmented with a task representation (TR) layer and an episodic memory (EM) buffer. It uses EM to retrieve and encode TRs, so when it searches for a TR online (Giallanza 2023; Hummos 2022), it can retrieve previously used TRs from EM.
1/n
1/n
The latent causes inferred by LCNet captured the ground truth event structure, and the inferred event boundaries were correlated with human judgments, as was previously found using SEM2.0, a variant of SEM modified to account for this dataset (Bezdek et al., 2022b). (12/N)

December 15, 2023 at 12:52 PM
The latent causes inferred by LCNet captured the ground truth event structure, and the inferred event boundaries were correlated with human judgments, as was previously found using SEM2.0, a variant of SEM modified to account for this dataset (Bezdek et al., 2022b). (12/N)
Finally, we used LCNet to process naturalistic video data of daily events (Bezdek et al., 2022a). LCNet was trained to predict “what would happen next” (i.e., the next frame of the video). (11/N)

December 15, 2023 at 12:52 PM
Finally, we used LCNet to process naturalistic video data of daily events (Bezdek et al., 2022a). LCNet was trained to predict “what would happen next” (i.e., the next frame of the video). (11/N)
In Simulation 2, LCNet was able to account for data showing that humans were better at learning event schemas in a blocked training curriculum compared to an interleaved curriculum (Beukers et al., 2023), a pattern that standard neural network models can't explain. (8/N)

December 15, 2023 at 12:51 PM
In Simulation 2, LCNet was able to account for data showing that humans were better at learning event schemas in a blocked training curriculum compared to an interleaved curriculum (Beukers et al., 2023), a pattern that standard neural network models can't explain. (8/N)
In simulation 1, we found that LCNet was able to extract and reuse the shared structure across contexts (e.g., learning a new related task was faster) and overcome catastrophic interference. (7/N)

December 15, 2023 at 12:51 PM
In simulation 1, we found that LCNet was able to extract and reuse the shared structure across contexts (e.g., learning a new related task was faster) and overcome catastrophic interference. (7/N)
To address this limitation, we proposed the Latent Cause Network (LCNet), which uses a single neural network shared across all latent causes... (5/N)

December 15, 2023 at 12:50 PM
To address this limitation, we proposed the Latent Cause Network (LCNet), which uses a single neural network shared across all latent causes... (5/N)
In this paper, we are interested in event processing – a form of continual learning where an intelligent agent has to learn about the properties of different contexts, and the context changes are not (necessarily) signaled explicitly to the agent. (2/N)

December 15, 2023 at 12:50 PM
In this paper, we are interested in event processing – a form of continual learning where an intelligent agent has to learn about the properties of different contexts, and the context changes are not (necessarily) signaled explicitly to the agent. (2/N)