



Private LLM
@privatellm.ai
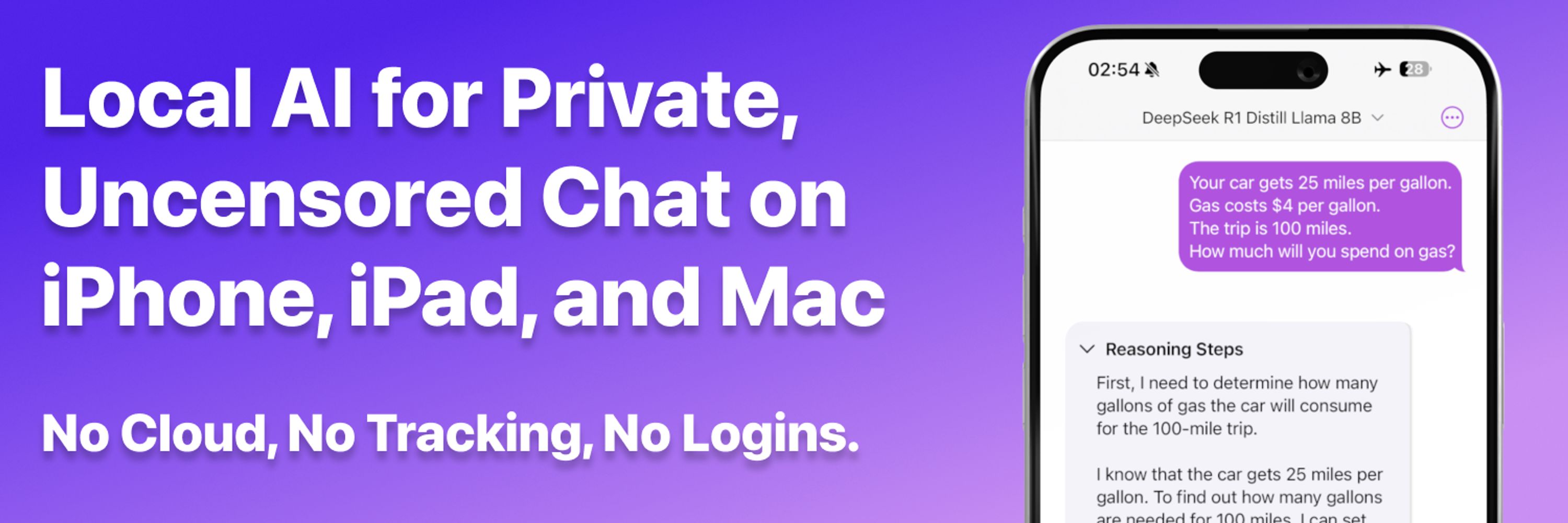
Local AI for Private, Uncensored Chat on iPhone, iPad, and Mac. No Cloud, No Tracking, No Logins.
https://privatellm.ai
https://privatellm.ai
Yes. LLM inference is memory-bound: memory capacity and memory bandwidth matter. For Macs, 64GB is a great sweet spot: you can run Llama 3.3 70B locally with GPT4o-level reasoning. Rule of thumb: run the largest model your Mac can fit.
October 29, 2025 at 4:31 PM
Yes. LLM inference is memory-bound: memory capacity and memory bandwidth matter. For Macs, 64GB is a great sweet spot: you can run Llama 3.3 70B locally with GPT4o-level reasoning. Rule of thumb: run the largest model your Mac can fit.
Thanks for the shout-out! 🙌
Glad you’re enjoying Private LLM. The boost you’re seeing is because we’re not an MLX/llama.cpp wrapper like LM Studio or Ollama (slowllama?)
We quantize each model (OmniQuant/GPTQ) for Apple Silicon, so even low-RAM iPhones and Macs run fast and reason better.
Glad you’re enjoying Private LLM. The boost you’re seeing is because we’re not an MLX/llama.cpp wrapper like LM Studio or Ollama (slowllama?)
We quantize each model (OmniQuant/GPTQ) for Apple Silicon, so even low-RAM iPhones and Macs run fast and reason better.
October 29, 2025 at 3:47 PM
Thanks for the shout-out! 🙌
Glad you’re enjoying Private LLM. The boost you’re seeing is because we’re not an MLX/llama.cpp wrapper like LM Studio or Ollama (slowllama?)
We quantize each model (OmniQuant/GPTQ) for Apple Silicon, so even low-RAM iPhones and Macs run fast and reason better.
Glad you’re enjoying Private LLM. The boost you’re seeing is because we’re not an MLX/llama.cpp wrapper like LM Studio or Ollama (slowllama?)
We quantize each model (OmniQuant/GPTQ) for Apple Silicon, so even low-RAM iPhones and Macs run fast and reason better.
Link to the paper: arxiv.org/abs/2508.03153

Estimating Worst-Case Frontier Risks of Open-Weight LLMs
In this paper, we study the worst-case frontier risks of releasing gpt-oss. We introduce malicious fine-tuning (MFT), where we attempt to elicit maximum capabilities by fine-tuning gpt-oss to be as ca...
arxiv.org
October 25, 2025 at 1:08 PM
Link to the paper: arxiv.org/abs/2508.03153
We are delighted to hear that. Please let us know if there’s any particular model you’d like to see in the app.
September 1, 2025 at 5:45 AM
We are delighted to hear that. Please let us know if there’s any particular model you’d like to see in the app.
We just shipped an update. More coming soon
August 31, 2025 at 5:16 PM
We just shipped an update. More coming soon
OpenHands LM – Coding focused language model based on Qwen 2.5 coder:
* 7B (iOS + macOS) – 8GB RAM or more
* 32B (macOS only) – 32GB RAM minimum
Handles bug fixing and code refactoring tasks. Trained on real GitHub issues via reinforcement learning.
* 7B (iOS + macOS) – 8GB RAM or more
* 32B (macOS only) – 32GB RAM minimum
Handles bug fixing and code refactoring tasks. Trained on real GitHub issues via reinforcement learning.

April 23, 2025 at 8:01 PM
OpenHands LM – Coding focused language model based on Qwen 2.5 coder:
* 7B (iOS + macOS) – 8GB RAM or more
* 32B (macOS only) – 32GB RAM minimum
Handles bug fixing and code refactoring tasks. Trained on real GitHub issues via reinforcement learning.
* 7B (iOS + macOS) – 8GB RAM or more
* 32B (macOS only) – 32GB RAM minimum
Handles bug fixing and code refactoring tasks. Trained on real GitHub issues via reinforcement learning.
Meta-Llama 3.1 8B SurviveV3 (3-bit iOS / 4-bit macOS)
Wilderness survival assistant, offline. Knows how to build shelters, find water, navigate terrain, etc.
Runs on any iOS/Mac device with 8GB+ RAM — even off-grid.
Wilderness survival assistant, offline. Knows how to build shelters, find water, navigate terrain, etc.
Runs on any iOS/Mac device with 8GB+ RAM — even off-grid.

April 23, 2025 at 8:01 PM
Meta-Llama 3.1 8B SurviveV3 (3-bit iOS / 4-bit macOS)
Wilderness survival assistant, offline. Knows how to build shelters, find water, navigate terrain, etc.
Runs on any iOS/Mac device with 8GB+ RAM — even off-grid.
Wilderness survival assistant, offline. Knows how to build shelters, find water, navigate terrain, etc.
Runs on any iOS/Mac device with 8GB+ RAM — even off-grid.
Llama 3.1 8B UltraMedical (3-bit iOS / 4-bit macOS)
Biomedical assistant for med students, researchers, and clinicians. Answers board-exam style questions, explains research findings, and supports clinical reasoning — privately.
Runs on 8GB+ RAM.
Biomedical assistant for med students, researchers, and clinicians. Answers board-exam style questions, explains research findings, and supports clinical reasoning — privately.
Runs on 8GB+ RAM.

April 23, 2025 at 8:01 PM
Llama 3.1 8B UltraMedical (3-bit iOS / 4-bit macOS)
Biomedical assistant for med students, researchers, and clinicians. Answers board-exam style questions, explains research findings, and supports clinical reasoning — privately.
Runs on 8GB+ RAM.
Biomedical assistant for med students, researchers, and clinicians. Answers board-exam style questions, explains research findings, and supports clinical reasoning — privately.
Runs on 8GB+ RAM.
Perplexity’s R1 1776 Distill Llama 70B
Post-trained to eliminate refusal behavior on politically sensitive topics — while preserving full reasoning ability.
Built to refuse censorship: open dialogue, independent thought, and the right to answer freely.
macOS only. Needs 48GB+ RAM.
Post-trained to eliminate refusal behavior on politically sensitive topics — while preserving full reasoning ability.
Built to refuse censorship: open dialogue, independent thought, and the right to answer freely.
macOS only. Needs 48GB+ RAM.

April 23, 2025 at 8:01 PM
Perplexity’s R1 1776 Distill Llama 70B
Post-trained to eliminate refusal behavior on politically sensitive topics — while preserving full reasoning ability.
Built to refuse censorship: open dialogue, independent thought, and the right to answer freely.
macOS only. Needs 48GB+ RAM.
Post-trained to eliminate refusal behavior on politically sensitive topics — while preserving full reasoning ability.
Built to refuse censorship: open dialogue, independent thought, and the right to answer freely.
macOS only. Needs 48GB+ RAM.
Amoral-Gemma3-1B-v2 & gemma-3-1b-it-abliterated
Uncensored 4-bit Omniquant quantized fine-tunes of Gemma 3 1B. For users who want unrestricted conversations, roleplay, and truth-seeking without moral filters. Fast and small. iOS and macOS.
Uncensored 4-bit Omniquant quantized fine-tunes of Gemma 3 1B. For users who want unrestricted conversations, roleplay, and truth-seeking without moral filters. Fast and small. iOS and macOS.
April 23, 2025 at 8:01 PM
Amoral-Gemma3-1B-v2 & gemma-3-1b-it-abliterated
Uncensored 4-bit Omniquant quantized fine-tunes of Gemma 3 1B. For users who want unrestricted conversations, roleplay, and truth-seeking without moral filters. Fast and small. iOS and macOS.
Uncensored 4-bit Omniquant quantized fine-tunes of Gemma 3 1B. For users who want unrestricted conversations, roleplay, and truth-seeking without moral filters. Fast and small. iOS and macOS.
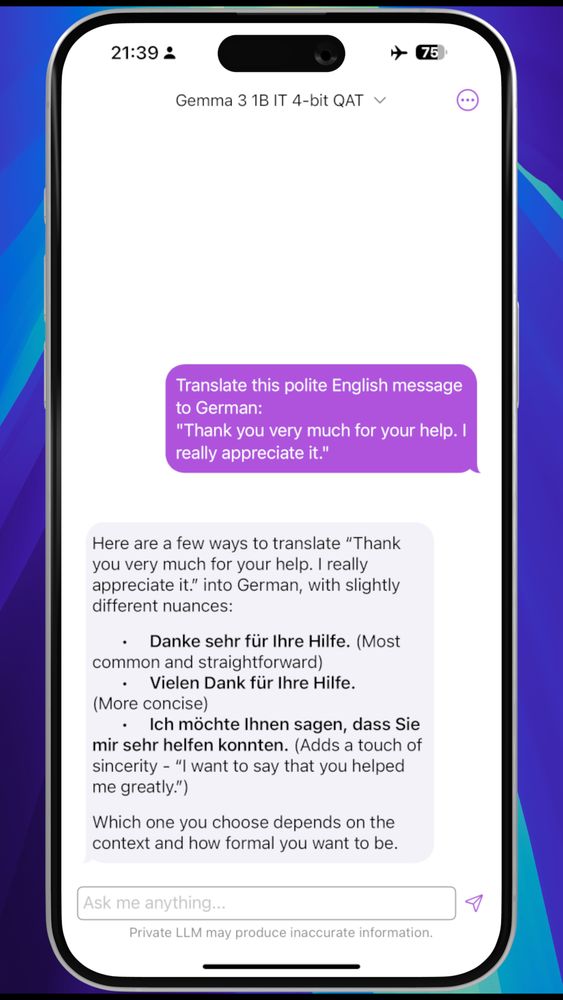
Gemma 3 1B IT (4-bit QAT)
Instruction-tuned.
Multilingual. Full 32K context on iPhones with ≥ 6GB RAM.
Ideal for writing, Q&A, summarization — in 140+ languages.
Small enough to run on any supported iOS or Mac device.
Multilingual. Full 32K context on iPhones with ≥ 6GB RAM.
Ideal for writing, Q&A, summarization — in 140+ languages.
Small enough to run on any supported iOS or Mac device.
April 23, 2025 at 8:01 PM
Gemma 3 1B IT (4-bit QAT)
Instruction-tuned.
Multilingual. Full 32K context on iPhones with ≥ 6GB RAM.
Ideal for writing, Q&A, summarization — in 140+ languages.
Small enough to run on any supported iOS or Mac device.
Multilingual. Full 32K context on iPhones with ≥ 6GB RAM.
Ideal for writing, Q&A, summarization — in 140+ languages.
Small enough to run on any supported iOS or Mac device.
🛠️ We've fixed a pesky crash that was affecting some newer models on older versions of macOS like Sonoma.
February 17, 2025 at 10:18 PM
🛠️ We've fixed a pesky crash that was affecting some newer models on older versions of macOS like Sonoma.
👀 Also, we've updated our lineup by adding support for both 3-bit and 4-bit OmniQuant quantized versions of the EVA LLaMA 3.33 70B v0.1 model by @Nottlespike. Note that we've deprecated the previous version, EVA LLaMA 3.33 70B v0.0

February 17, 2025 at 10:18 PM
👀 Also, we've updated our lineup by adding support for both 3-bit and 4-bit OmniQuant quantized versions of the EVA LLaMA 3.33 70B v0.1 model by @Nottlespike. Note that we've deprecated the previous version, EVA LLaMA 3.33 70B v0.0
For Apple Silicon Mac users with 64GB or more RAM, we still recommend using the 4-bit OmniQuant-quantized version of 70B models.
February 17, 2025 at 10:18 PM
For Apple Silicon Mac users with 64GB or more RAM, we still recommend using the 4-bit OmniQuant-quantized version of 70B models.
💪 Power users, rejoice! The 5 new 3-bit OmniQuant-quantized 70B models on Mac from Private LLM v1.9.8 are here. These models consume around 5GB less RAM than their 4-bit counterparts, making them ideal for Apple Silicon Macs with 48GB of RAM.
February 17, 2025 at 10:18 PM
💪 Power users, rejoice! The 5 new 3-bit OmniQuant-quantized 70B models on Mac from Private LLM v1.9.8 are here. These models consume around 5GB less RAM than their 4-bit counterparts, making them ideal for Apple Silicon Macs with 48GB of RAM.
📏 Now, with Private LLM, you can see the context length right in the model quick switcher! This little upgrade makes a big difference, helping you choose the perfect model for your conversation or task at a glance.

February 17, 2025 at 10:18 PM
📏 Now, with Private LLM, you can see the context length right in the model quick switcher! This little upgrade makes a big difference, helping you choose the perfect model for your conversation or task at a glance.
✍️ Unleash your creativity with the Gemma 2 iFable 9B model from iFable! This top-tier creative writing model works on iPad Pros with 16GB of RAM or any Apple Silicon Mac with 16GB+ RAM. No other local LLM app lets you run 9B or 14B models on iOS like Private LLM can.

February 17, 2025 at 10:18 PM
✍️ Unleash your creativity with the Gemma 2 iFable 9B model from iFable! This top-tier creative writing model works on iPad Pros with 16GB of RAM or any Apple Silicon Mac with 16GB+ RAM. No other local LLM app lets you run 9B or 14B models on iOS like Private LLM can.
- Dolphin 3.0 Llama 3.1 8B - For iOS devices with 8GB or more RAM, like the iPhone 15 Pro or newer
These are currently the best uncensored LLMs that can fit in your pocket, no holds barred!
These are currently the best uncensored LLMs that can fit in your pocket, no holds barred!
February 17, 2025 at 10:18 PM
- Dolphin 3.0 Llama 3.1 8B - For iOS devices with 8GB or more RAM, like the iPhone 15 Pro or newer
These are currently the best uncensored LLMs that can fit in your pocket, no holds barred!
These are currently the best uncensored LLMs that can fit in your pocket, no holds barred!
- Dolphin 3.0 Llama 3.2 3B - For those with 6GB+ RAM on their iOS devices or any Apple Silicon Mac
- Dolphin 3.0 Qwen 2.5 0.5B, 1.5B, 3B - Compatible with nearly all modern iPhones (iPhone 12 or newer) and Macs
- Dolphin 3.0 Qwen 2.5 0.5B, 1.5B, 3B - Compatible with nearly all modern iPhones (iPhone 12 or newer) and Macs
February 17, 2025 at 10:18 PM
- Dolphin 3.0 Llama 3.2 3B - For those with 6GB+ RAM on their iOS devices or any Apple Silicon Mac
- Dolphin 3.0 Qwen 2.5 0.5B, 1.5B, 3B - Compatible with nearly all modern iPhones (iPhone 12 or newer) and Macs
- Dolphin 3.0 Qwen 2.5 0.5B, 1.5B, 3B - Compatible with nearly all modern iPhones (iPhone 12 or newer) and Macs
🐬 Say hello to the uncensored freedom of Dolphin 3.0 models! From Cognitive Computations, these models are your ticket to unfiltered AI conversations.
- Dolphin 3.0 Llama 3.2 1B - Perfect for iPhones/iPads with 4GB+ RAM or any Apple Silicon Mac
- Dolphin 3.0 Llama 3.2 1B - Perfect for iPhones/iPads with 4GB+ RAM or any Apple Silicon Mac
February 17, 2025 at 10:18 PM
🐬 Say hello to the uncensored freedom of Dolphin 3.0 models! From Cognitive Computations, these models are your ticket to unfiltered AI conversations.
- Dolphin 3.0 Llama 3.2 1B - Perfect for iPhones/iPads with 4GB+ RAM or any Apple Silicon Mac
- Dolphin 3.0 Llama 3.2 1B - Perfect for iPhones/iPads with 4GB+ RAM or any Apple Silicon Mac
Thank you, @soldaini.net! And huge congratulations on launching Ai2 OLMoE - love what you’re doing for local AI!
February 17, 2025 at 9:04 PM
Thank you, @soldaini.net! And huge congratulations on launching Ai2 OLMoE - love what you’re doing for local AI!