



Pranjal
@pranjal2041.bsky.social
PhD Student @ltiatcmu.bsky.social. Working on reasoning, code-gen agents and test-time compute.
Want to use PwP for your own agents? We’ve built a super simple API to interact with PwP & evaluate on PwP-Bench.
Find more interesting details on our website & paper here:
🌐: programmingwithpixels.com
with
@wellecks.bsky.social
Find more interesting details on our website & paper here:
🌐: programmingwithpixels.com
with
@wellecks.bsky.social


February 26, 2025 at 5:17 PM
Want to use PwP for your own agents? We’ve built a super simple API to interact with PwP & evaluate on PwP-Bench.
Find more interesting details on our website & paper here:
🌐: programmingwithpixels.com
with
@wellecks.bsky.social
Find more interesting details on our website & paper here:
🌐: programmingwithpixels.com
with
@wellecks.bsky.social
However, it’s not perfect – today’s computer use agents are still bad at visual grounding—they struggle to fully exploit IDE features.
Tiny icons or complex menus can confuse the agent, and multi-step operations (e.g. a debugger workflow) remain challenging.
🧵
Tiny icons or complex menus can confuse the agent, and multi-step operations (e.g. a debugger workflow) remain challenging.
🧵


February 26, 2025 at 5:17 PM
However, it’s not perfect – today’s computer use agents are still bad at visual grounding—they struggle to fully exploit IDE features.
Tiny icons or complex menus can confuse the agent, and multi-step operations (e.g. a debugger workflow) remain challenging.
🧵
Tiny icons or complex menus can confuse the agent, and multi-step operations (e.g. a debugger workflow) remain challenging.
🧵
So we tested a computer-use agent (screen interaction + file, bash tools) in PwP on PwP-Bench.
Results? It competes with or even surpasses tool-based agents—without any domain-specific hand-engineering.
Results? It competes with or even surpasses tool-based agents—without any domain-specific hand-engineering.

February 26, 2025 at 5:17 PM
So we tested a computer-use agent (screen interaction + file, bash tools) in PwP on PwP-Bench.
Results? It competes with or even surpasses tool-based agents—without any domain-specific hand-engineering.
Results? It competes with or even surpasses tool-based agents—without any domain-specific hand-engineering.
To evaluate agents, we unified 15 existing SWE benchmarks into PwP-Bench, covering multiple languages and tasks like debugging, multimodal code synthesis, ethical hacking & more.
PwP-Bench systematically tests a broad dev skillset within a single, realistic IDE setup.
🧵
PwP-Bench systematically tests a broad dev skillset within a single, realistic IDE setup.
🧵



February 26, 2025 at 5:17 PM
To evaluate agents, we unified 15 existing SWE benchmarks into PwP-Bench, covering multiple languages and tasks like debugging, multimodal code synthesis, ethical hacking & more.
PwP-Bench systematically tests a broad dev skillset within a single, realistic IDE setup.
🧵
PwP-Bench systematically tests a broad dev skillset within a single, realistic IDE setup.
🧵
We built an environment PwP for generalist agents that use the computer like a developer.
Agents see the IDE (pixel screenshots) and act by typing & clicking—no special integrations are needed. They leverage all developer tools, just like an autonomous programmer at keyboard!
🧵
Agents see the IDE (pixel screenshots) and act by typing & clicking—no special integrations are needed. They leverage all developer tools, just like an autonomous programmer at keyboard!
🧵

February 26, 2025 at 5:17 PM
We built an environment PwP for generalist agents that use the computer like a developer.
Agents see the IDE (pixel screenshots) and act by typing & clicking—no special integrations are needed. They leverage all developer tools, just like an autonomous programmer at keyboard!
🧵
Agents see the IDE (pixel screenshots) and act by typing & clicking—no special integrations are needed. They leverage all developer tools, just like an autonomous programmer at keyboard!
🧵
Our key insight: most SWE tasks boil down to using an IDE, i.e
✅ Seeing VS Code’s UI
✅ Typing, clicking & basic file operations
✅ Using built-in tools (debuggers, refactoring, etc)
A simple, general-purpose agent should leverage any SWE tool-without extra engineering.
🧵
✅ Seeing VS Code’s UI
✅ Typing, clicking & basic file operations
✅ Using built-in tools (debuggers, refactoring, etc)
A simple, general-purpose agent should leverage any SWE tool-without extra engineering.
🧵

February 26, 2025 at 5:17 PM
Our key insight: most SWE tasks boil down to using an IDE, i.e
✅ Seeing VS Code’s UI
✅ Typing, clicking & basic file operations
✅ Using built-in tools (debuggers, refactoring, etc)
A simple, general-purpose agent should leverage any SWE tool-without extra engineering.
🧵
✅ Seeing VS Code’s UI
✅ Typing, clicking & basic file operations
✅ Using built-in tools (debuggers, refactoring, etc)
A simple, general-purpose agent should leverage any SWE tool-without extra engineering.
🧵
Why? Because most AI coding assistants today rely on a handful of fixed tools or APIs to write or fix code.
That’s limiting – they can’t easily adapt to new tasks or fully leverage complex IDEs like human developers do. In other words, their “toolbox” is too narrow.
🧵
That’s limiting – they can’t easily adapt to new tasks or fully leverage complex IDEs like human developers do. In other words, their “toolbox” is too narrow.
🧵

February 26, 2025 at 5:17 PM
Why? Because most AI coding assistants today rely on a handful of fixed tools or APIs to write or fix code.
That’s limiting – they can’t easily adapt to new tasks or fully leverage complex IDEs like human developers do. In other words, their “toolbox” is too narrow.
🧵
That’s limiting – they can’t easily adapt to new tasks or fully leverage complex IDEs like human developers do. In other words, their “toolbox” is too narrow.
🧵
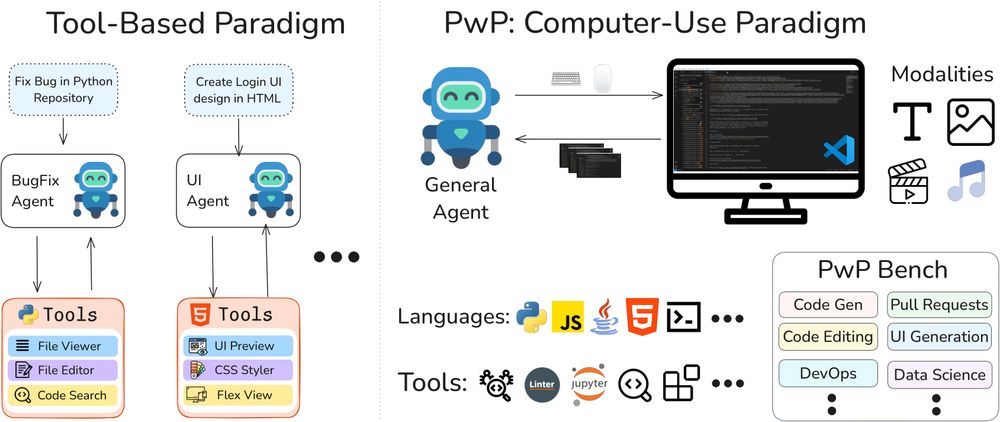
What if AI agents did software engineering like humans—seeing the screen & using any developer tool?
Introducing Programming with Pixels: an SWE environment where agents control VSCode via screen perception, typing & clicking to tackle diverse tasks.
programmingwithpixels.com
🧵
Introducing Programming with Pixels: an SWE environment where agents control VSCode via screen perception, typing & clicking to tackle diverse tasks.
programmingwithpixels.com
🧵

February 26, 2025 at 5:17 PM
What if AI agents did software engineering like humans—seeing the screen & using any developer tool?
Introducing Programming with Pixels: an SWE environment where agents control VSCode via screen perception, typing & clicking to tackle diverse tasks.
programmingwithpixels.com
🧵
Introducing Programming with Pixels: an SWE environment where agents control VSCode via screen perception, typing & clicking to tackle diverse tasks.
programmingwithpixels.com
🧵
Results: Despite no human intervention, we achieve state-of-the-art results on verified code generation for verified versions of Human-Eval and MBPP.
Even better, AlphaVerus can improve GPT-4o or any other model without any fine-tuning!!
🧵
Even better, AlphaVerus can improve GPT-4o or any other model without any fine-tuning!!
🧵


December 10, 2024 at 10:33 PM
Results: Despite no human intervention, we achieve state-of-the-art results on verified code generation for verified versions of Human-Eval and MBPP.
Even better, AlphaVerus can improve GPT-4o or any other model without any fine-tuning!!
🧵
Even better, AlphaVerus can improve GPT-4o or any other model without any fine-tuning!!
🧵
We find these models self-learn to game the system by using subtle techniques such as generating incomplete specifications, degenerate solutions, and even exploiting verifier limitations!
Our critique module solves this problem! And yes, our critique module self-improves too!
🧵
Our critique module solves this problem! And yes, our critique module self-improves too!
🧵


December 10, 2024 at 10:33 PM
We find these models self-learn to game the system by using subtle techniques such as generating incomplete specifications, degenerate solutions, and even exploiting verifier limitations!
Our critique module solves this problem! And yes, our critique module self-improves too!
🧵
Our critique module solves this problem! And yes, our critique module self-improves too!
🧵
AlphaVerus solves these challenges by translating from a high-resource language. Incorrect translations are refined using a novel tree search algorithm guided by verifier feedback!
Correct translations and refinements improve future models!
Challenge? Reward Hacking!
🧵
Correct translations and refinements improve future models!
Challenge? Reward Hacking!
🧵

December 10, 2024 at 10:33 PM
AlphaVerus solves these challenges by translating from a high-resource language. Incorrect translations are refined using a novel tree search algorithm guided by verifier feedback!
Correct translations and refinements improve future models!
Challenge? Reward Hacking!
🧵
Correct translations and refinements improve future models!
Challenge? Reward Hacking!
🧵
How does it work? Given input/output specifications, LLMs generate corresponding Rust code along with proof hints like invariants. A verifier (Verus) checks if the generated proof & code is correct.
Challenge: Data is scarce & proofs are complex!
Challenge: Data is scarce & proofs are complex!

December 10, 2024 at 10:33 PM
How does it work? Given input/output specifications, LLMs generate corresponding Rust code along with proof hints like invariants. A verifier (Verus) checks if the generated proof & code is correct.
Challenge: Data is scarce & proofs are complex!
Challenge: Data is scarce & proofs are complex!
LLMs often generate incorrect code.
Instead, what if they can prove code correctness?
Presenting AlphaVerus: A self-reinforcing method that automatically learns to generate correct code using inference-time search and verifier feedback.
🌐 : alphaverus.github.io
🧵
Instead, what if they can prove code correctness?
Presenting AlphaVerus: A self-reinforcing method that automatically learns to generate correct code using inference-time search and verifier feedback.
🌐 : alphaverus.github.io
🧵
December 10, 2024 at 10:33 PM
LLMs often generate incorrect code.
Instead, what if they can prove code correctness?
Presenting AlphaVerus: A self-reinforcing method that automatically learns to generate correct code using inference-time search and verifier feedback.
🌐 : alphaverus.github.io
🧵
Instead, what if they can prove code correctness?
Presenting AlphaVerus: A self-reinforcing method that automatically learns to generate correct code using inference-time search and verifier feedback.
🌐 : alphaverus.github.io
🧵