



@potamitisn.bsky.social
🎓 Paper: openreview.net/pdf?id=yNpYb...
📝 Blog: au-clan.github.io/2025-06-19-f...
💻 Code: github.com/au-clan/FoA
cc: @akhilarora.bsky.social @larshklein.bsky.social @caglarai.bsky.social @icepfl.bsky.social @csaudk.bsky.social
📝 Blog: au-clan.github.io/2025-06-19-f...
💻 Code: github.com/au-clan/FoA
cc: @akhilarora.bsky.social @larshklein.bsky.social @caglarai.bsky.social @icepfl.bsky.social @csaudk.bsky.social
openreview.net
July 15, 2025 at 5:27 PM
We systematically disable components of FoA to assess their impact. Removing selection, resampling, backtracking, caching, or batching each leads to lower success or higher cost. Results show that all parts of the system contribute meaningfully to its overall performance.

July 15, 2025 at 5:27 PM
We systematically disable components of FoA to assess their impact. Removing selection, resampling, backtracking, caching, or batching each leads to lower success or higher cost. Results show that all parts of the system contribute meaningfully to its overall performance.
We evaluate raw Llama3.2 models on structured reasoning tasks. Alone, both perform poorly. But with FoA, performance improves 5-6 times. Notably, Llama3.2-11B with FoA, outperforms the much larger 90B model. FoA allows smaller models to rival or beat larger ones, bridging the reasoning gap.

July 15, 2025 at 5:27 PM
We evaluate raw Llama3.2 models on structured reasoning tasks. Alone, both perform poorly. But with FoA, performance improves 5-6 times. Notably, Llama3.2-11B with FoA, outperforms the much larger 90B model. FoA allows smaller models to rival or beat larger ones, bridging the reasoning gap.
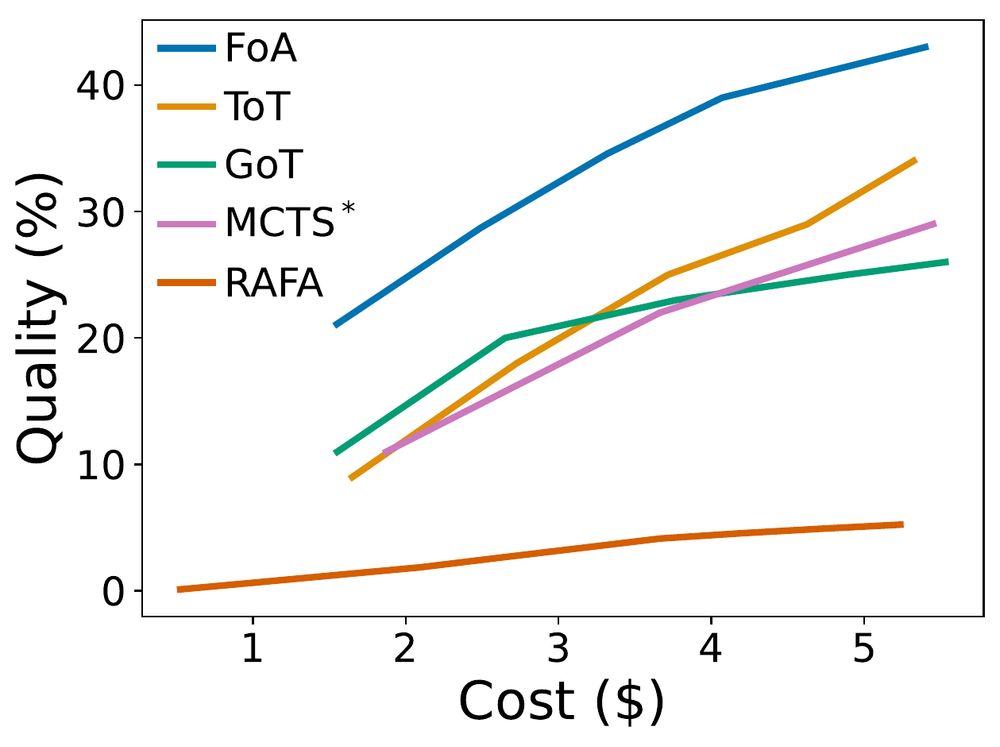
We compare FoA to top methods under a fixed $5 budget, allowing multiple trials per method. FoA consistently outperforms others across all budget points. While some baselines may improve with more spending, FoA offers the best cost-quality trade-off in resource-constrained settings.
July 15, 2025 at 5:27 PM
We compare FoA to top methods under a fixed $5 budget, allowing multiple trials per method. FoA consistently outperforms others across all budget points. While some baselines may improve with more spending, FoA offers the best cost-quality trade-off in resource-constrained settings.
In the selection phase, the fleet evaluates all agent states using a value function and resamples the population with replacement. FoA also supports backtracking: instead of sampling only from current states, it can revisit earlier ones from its history, with older states gradually discounted.

July 15, 2025 at 5:27 PM
In the selection phase, the fleet evaluates all agent states using a value function and resamples the population with replacement. FoA also supports backtracking: instead of sampling only from current states, it can revisit earlier ones from its history, with older states gradually discounted.
In the mutation phase, each agent in the fleet independently explores the search space by simulating a sequence of transitions. Any agent that enters an invalid or terminal state is immediately removed and replaced by a randomly selected copy of a surviving agent.

July 15, 2025 at 5:27 PM
In the mutation phase, each agent in the fleet independently explores the search space by simulating a sequence of transitions. Any agent that enters an invalid or terminal state is immediately removed and replaced by a randomly selected copy of a surviving agent.
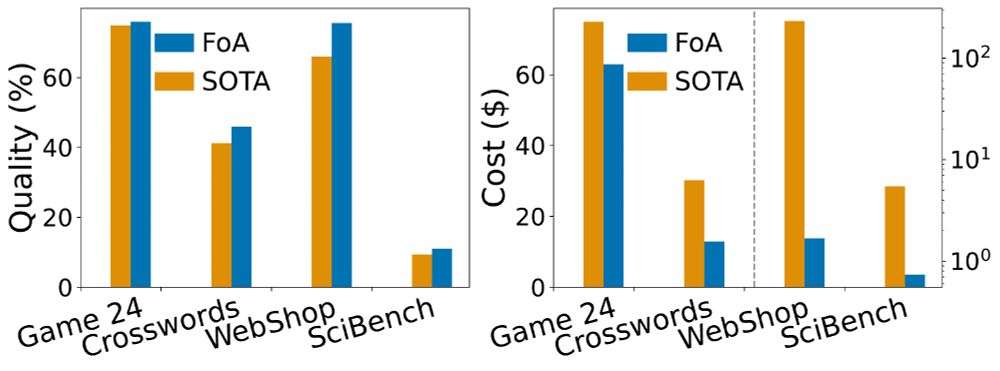
✅ Model-agnostic gains: FoA outperforms top reasoning frameworks across tasks and models
💸 Better cost-quality trade-off: Up to 70% improvements at a fraction of the compute
⚙️ Plug-and-play: Works with any prompting strategy.
📏 Tunable & predictable: Control compute precisely
😁 More details 👇
💸 Better cost-quality trade-off: Up to 70% improvements at a fraction of the compute
⚙️ Plug-and-play: Works with any prompting strategy.
📏 Tunable & predictable: Control compute precisely
😁 More details 👇
July 15, 2025 at 5:27 PM
✅ Model-agnostic gains: FoA outperforms top reasoning frameworks across tasks and models
💸 Better cost-quality trade-off: Up to 70% improvements at a fraction of the compute
⚙️ Plug-and-play: Works with any prompting strategy.
📏 Tunable & predictable: Control compute precisely
😁 More details 👇
💸 Better cost-quality trade-off: Up to 70% improvements at a fraction of the compute
⚙️ Plug-and-play: Works with any prompting strategy.
📏 Tunable & predictable: Control compute precisely
😁 More details 👇
In Fleet of agents, each agent explores the problem space independently by generating thoughts, taking actions, or making moves. After a round of exploration, agents are scored, and the best-performing ones are resampled to continue, while weak or invalid ones are eliminated and replaced.

July 15, 2025 at 5:27 PM
In Fleet of agents, each agent explores the problem space independently by generating thoughts, taking actions, or making moves. After a round of exploration, agents are scored, and the best-performing ones are resampled to continue, while weak or invalid ones are eliminated and replaced.