



Pierre Chambon
@pierrechambon.bsky.social
PhD at FAIR (Meta) and INRIA
Former researcher at Stanford University
Former researcher at Stanford University
Llama 4 results out on ✨BigO(Bench)✨!
Llama 4 Maverick is top 4 all@1 on Time Complexity Generation and top 2🥈coeffFull on Time Complexity Ranking (beating R1, though not using any reasoning tokens).
The model is less performant on Space Complexity.
👇All links below👇
Llama 4 Maverick is top 4 all@1 on Time Complexity Generation and top 2🥈coeffFull on Time Complexity Ranking (beating R1, though not using any reasoning tokens).
The model is less performant on Space Complexity.
👇All links below👇

April 16, 2025 at 3:05 PM
Llama 4 results out on ✨BigO(Bench)✨!
Llama 4 Maverick is top 4 all@1 on Time Complexity Generation and top 2🥈coeffFull on Time Complexity Ranking (beating R1, though not using any reasoning tokens).
The model is less performant on Space Complexity.
👇All links below👇
Llama 4 Maverick is top 4 all@1 on Time Complexity Generation and top 2🥈coeffFull on Time Complexity Ranking (beating R1, though not using any reasoning tokens).
The model is less performant on Space Complexity.
👇All links below👇
✨BigO(Bench)✨ Leaderboard Update!
3 models added to our benchmark:
🏆 nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
🧑💻 agentica-org/DeepCoder-14B-Preview
🤲 all-hands/openhands-lm-32b-v0.1
Thanks @vllm_project and @huggingface for quickly supporting inference!
👇All links below👇
3 models added to our benchmark:
🏆 nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
🧑💻 agentica-org/DeepCoder-14B-Preview
🤲 all-hands/openhands-lm-32b-v0.1
Thanks @vllm_project and @huggingface for quickly supporting inference!
👇All links below👇

April 10, 2025 at 4:11 PM
✨BigO(Bench)✨ Leaderboard Update!
3 models added to our benchmark:
🏆 nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
🧑💻 agentica-org/DeepCoder-14B-Preview
🤲 all-hands/openhands-lm-32b-v0.1
Thanks @vllm_project and @huggingface for quickly supporting inference!
👇All links below👇
3 models added to our benchmark:
🏆 nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
🧑💻 agentica-org/DeepCoder-14B-Preview
🤲 all-hands/openhands-lm-32b-v0.1
Thanks @vllm_project and @huggingface for quickly supporting inference!
👇All links below👇
🔥Very happy to introduce BigO(Bench) dataset on @hf.co 🤗
✨3,105 coding problems and 1,190,250 solutions from CodeContests
✨Time/Space Complexity labels and curve coefficients
✨Up to 5k Runtime/Memory Footprint measures for each solution
huggingface.co/datasets/fac...
✨3,105 coding problems and 1,190,250 solutions from CodeContests
✨Time/Space Complexity labels and curve coefficients
✨Up to 5k Runtime/Memory Footprint measures for each solution
huggingface.co/datasets/fac...
April 3, 2025 at 2:46 PM
🔥Very happy to introduce BigO(Bench) dataset on @hf.co 🤗
✨3,105 coding problems and 1,190,250 solutions from CodeContests
✨Time/Space Complexity labels and curve coefficients
✨Up to 5k Runtime/Memory Footprint measures for each solution
huggingface.co/datasets/fac...
✨3,105 coding problems and 1,190,250 solutions from CodeContests
✨Time/Space Complexity labels and curve coefficients
✨Up to 5k Runtime/Memory Footprint measures for each solution
huggingface.co/datasets/fac...
📸Results snapshot !🏅
All these models have similar active parameters, DeepSeekV3-0324 being MoE with 37B active parameters.
Whereas DeepSeekR1 and QwQ use reasoning tokens (and therefore way more inference tokens), Gemma3 and DeepSeekV3-0324 directly output the result.
🧵2/6
All these models have similar active parameters, DeepSeekV3-0324 being MoE with 37B active parameters.
Whereas DeepSeekR1 and QwQ use reasoning tokens (and therefore way more inference tokens), Gemma3 and DeepSeekV3-0324 directly output the result.
🧵2/6

March 27, 2025 at 3:24 PM
📸Results snapshot !🏅
All these models have similar active parameters, DeepSeekV3-0324 being MoE with 37B active parameters.
Whereas DeepSeekR1 and QwQ use reasoning tokens (and therefore way more inference tokens), Gemma3 and DeepSeekV3-0324 directly output the result.
🧵2/6
All these models have similar active parameters, DeepSeekV3-0324 being MoE with 37B active parameters.
Whereas DeepSeekR1 and QwQ use reasoning tokens (and therefore way more inference tokens), Gemma3 and DeepSeekV3-0324 directly output the result.
🧵2/6
In the context of newly released benchmarks getting quickly saturated, BigO(Bench) aims at evaluating high-level reasoning skills that stay out-of-scope of current LLMs and are hard to train/reinforce upon, bringing their performance down.

March 20, 2025 at 4:48 PM
In the context of newly released benchmarks getting quickly saturated, BigO(Bench) aims at evaluating high-level reasoning skills that stay out-of-scope of current LLMs and are hard to train/reinforce upon, bringing their performance down.
Models tend to under-perform on non-optimal complexity classes, compared to the most optimized class of every problem. This seems counterintuitive for
any human programmer, usually accustomed to easily
finding non-optimized solutions, but struggling at the
best ones.
any human programmer, usually accustomed to easily
finding non-optimized solutions, but struggling at the
best ones.

March 20, 2025 at 4:48 PM
Models tend to under-perform on non-optimal complexity classes, compared to the most optimized class of every problem. This seems counterintuitive for
any human programmer, usually accustomed to easily
finding non-optimized solutions, but struggling at the
best ones.
any human programmer, usually accustomed to easily
finding non-optimized solutions, but struggling at the
best ones.
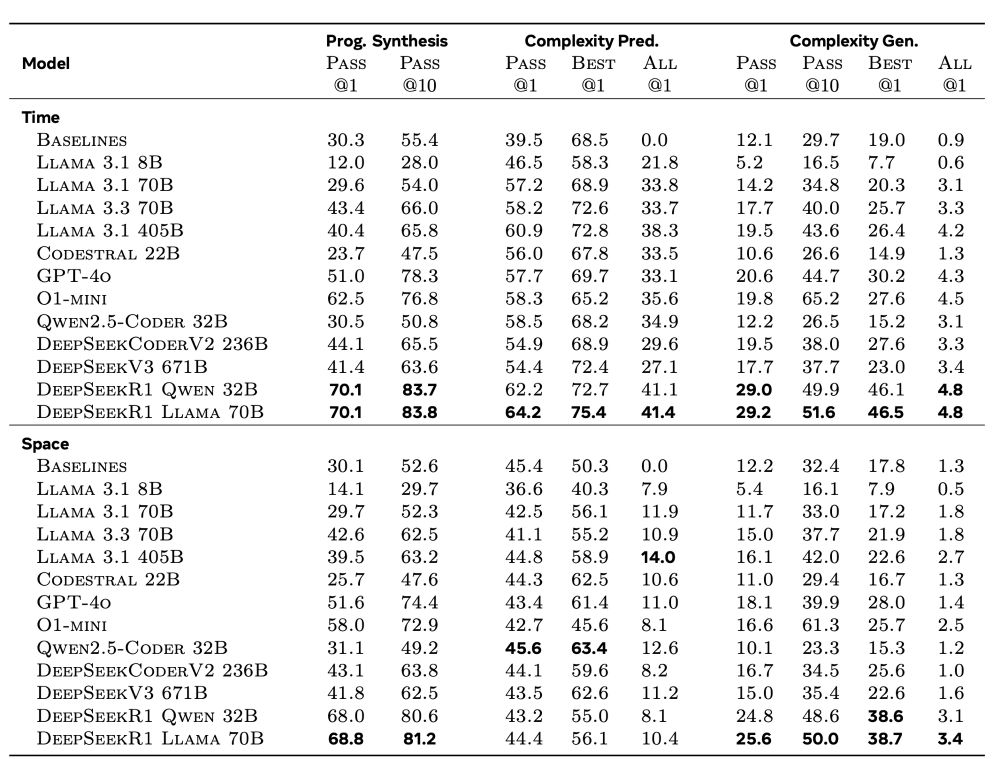
LLMs struggle with Complexity Generation - generating code that meets specific complexity requirements -, underperforming in comparison to Complexity Prediction - predicting complexity of existing code - or generating code alone.
Token-space reasoning models perform best !
Token-space reasoning models perform best !
March 20, 2025 at 4:48 PM
LLMs struggle with Complexity Generation - generating code that meets specific complexity requirements -, underperforming in comparison to Complexity Prediction - predicting complexity of existing code - or generating code alone.
Token-space reasoning models perform best !
Token-space reasoning models perform best !
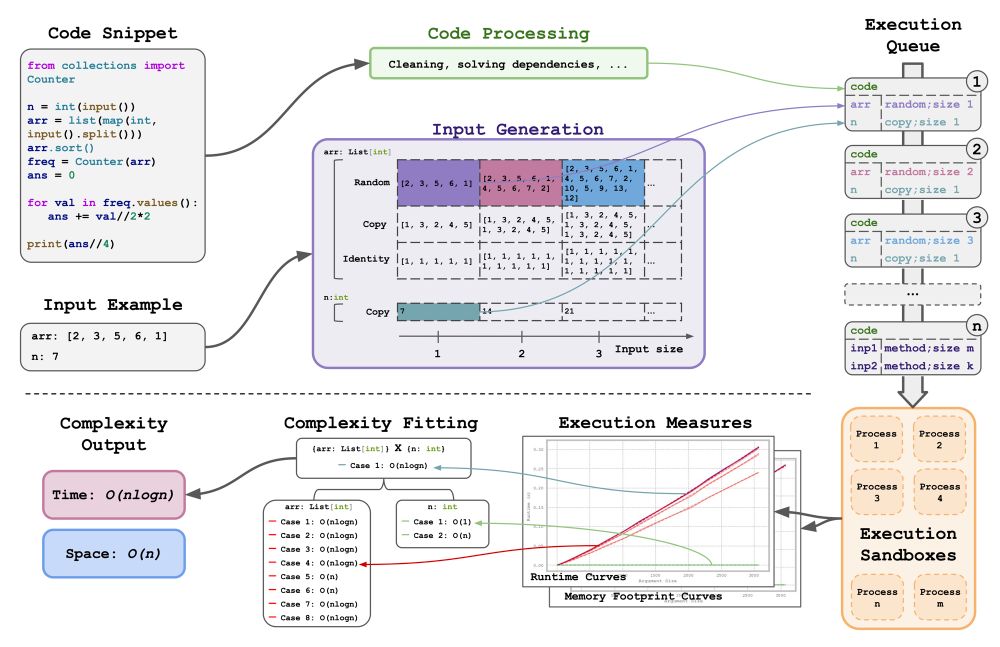
Our Complexity Framework can analyze arbitrary Python code snippets, employing input generation methods to empirically measure runtime and memory footprint, thereby inferring complexity classes and corresponding curve coefficients without reliance on oracle models.
March 20, 2025 at 4:48 PM
Our Complexity Framework can analyze arbitrary Python code snippets, employing input generation methods to empirically measure runtime and memory footprint, thereby inferring complexity classes and corresponding curve coefficients without reliance on oracle models.
First, we developed a novel Dynamic Complexity Inference tool to measure Time/Space Complexity of code snippets 👉 Code is released!
The framework ran on ~1M Code Contests solutions 👉 Data is public too!
Lastly, we designed test sets and evaluated LLMs 👉 Leaderboard is out!
The framework ran on ~1M Code Contests solutions 👉 Data is public too!
Lastly, we designed test sets and evaluated LLMs 👉 Leaderboard is out!

March 20, 2025 at 4:48 PM
First, we developed a novel Dynamic Complexity Inference tool to measure Time/Space Complexity of code snippets 👉 Code is released!
The framework ran on ~1M Code Contests solutions 👉 Data is public too!
Lastly, we designed test sets and evaluated LLMs 👉 Leaderboard is out!
The framework ran on ~1M Code Contests solutions 👉 Data is public too!
Lastly, we designed test sets and evaluated LLMs 👉 Leaderboard is out!
Beyond generating code solutions, can LLMs answer the final Time/Space Complexity question of coding interviews ? 👨🏫
We investigate the performance of LLMs on 3 tasks:
✅ Time/Space Complexity Prediction
✅ Time/Space Complexity Generation
✅ Time/Space Complexity Ranking
We investigate the performance of LLMs on 3 tasks:
✅ Time/Space Complexity Prediction
✅ Time/Space Complexity Generation
✅ Time/Space Complexity Ranking

March 20, 2025 at 4:48 PM
Beyond generating code solutions, can LLMs answer the final Time/Space Complexity question of coding interviews ? 👨🏫
We investigate the performance of LLMs on 3 tasks:
✅ Time/Space Complexity Prediction
✅ Time/Space Complexity Generation
✅ Time/Space Complexity Ranking
We investigate the performance of LLMs on 3 tasks:
✅ Time/Space Complexity Prediction
✅ Time/Space Complexity Generation
✅ Time/Space Complexity Ranking
📸 Quick snapshot of our results ! 🏅
BigO(Bench) evaluates high-level reasoning skills in coding, revealing that top-scoring models on Code Contests often struggle when required to both write and reason about their code.
Extra-Space Complexity seems particularly challenging !
BigO(Bench) evaluates high-level reasoning skills in coding, revealing that top-scoring models on Code Contests often struggle when required to both write and reason about their code.
Extra-Space Complexity seems particularly challenging !

March 20, 2025 at 4:48 PM
📸 Quick snapshot of our results ! 🏅
BigO(Bench) evaluates high-level reasoning skills in coding, revealing that top-scoring models on Code Contests often struggle when required to both write and reason about their code.
Extra-Space Complexity seems particularly challenging !
BigO(Bench) evaluates high-level reasoning skills in coding, revealing that top-scoring models on Code Contests often struggle when required to both write and reason about their code.
Extra-Space Complexity seems particularly challenging !
Does your LLM truly comprehend the complexity of the code it generates? 🥰
Introducing our new non-saturated (for at least the coming week? 😉) benchmark:
✨BigO(Bench)✨ - Can LLMs Generate Code with Controlled Time and Space Complexity?
Check out the details below !👇
Introducing our new non-saturated (for at least the coming week? 😉) benchmark:
✨BigO(Bench)✨ - Can LLMs Generate Code with Controlled Time and Space Complexity?
Check out the details below !👇

March 20, 2025 at 4:48 PM
Does your LLM truly comprehend the complexity of the code it generates? 🥰
Introducing our new non-saturated (for at least the coming week? 😉) benchmark:
✨BigO(Bench)✨ - Can LLMs Generate Code with Controlled Time and Space Complexity?
Check out the details below !👇
Introducing our new non-saturated (for at least the coming week? 😉) benchmark:
✨BigO(Bench)✨ - Can LLMs Generate Code with Controlled Time and Space Complexity?
Check out the details below !👇