




PicoCreator - AI Model Builder 🛫 NeurIPS
@picocreator.bsky.social
Serverless 🦙 @ https://featherless.ai
Build Attention-Killers AI (RWKV) from scratch @ http://wiki.rwkv.com
Also built uilicious & GPU.js (http://gpu.rocks)
Build Attention-Killers AI (RWKV) from scratch @ http://wiki.rwkv.com
Also built uilicious & GPU.js (http://gpu.rocks)
Damn. Thanks for doing this - was planning to dive into it as well - after the discussion we had that day
Gives more context than I expected. 👍
Gives more context than I expected. 👍
December 13, 2024 at 8:54 PM
Damn. Thanks for doing this - was planning to dive into it as well - after the discussion we had that day
Gives more context than I expected. 👍
Gives more context than I expected. 👍
Also as O1 style reasoning datasets "comes online" in
the dataset space
We plan to do more training on these new line of QRWKV and LLaMA-RWKV models, over larger context lengths so that they can be true transformer killer
If your @ Neurips, you can find me with an RWKV7 Goose
the dataset space
We plan to do more training on these new line of QRWKV and LLaMA-RWKV models, over larger context lengths so that they can be true transformer killer
If your @ Neurips, you can find me with an RWKV7 Goose

December 11, 2024 at 9:17 PM
Also as O1 style reasoning datasets "comes online" in
the dataset space
We plan to do more training on these new line of QRWKV and LLaMA-RWKV models, over larger context lengths so that they can be true transformer killer
If your @ Neurips, you can find me with an RWKV7 Goose
the dataset space
We plan to do more training on these new line of QRWKV and LLaMA-RWKV models, over larger context lengths so that they can be true transformer killer
If your @ Neurips, you can find me with an RWKV7 Goose
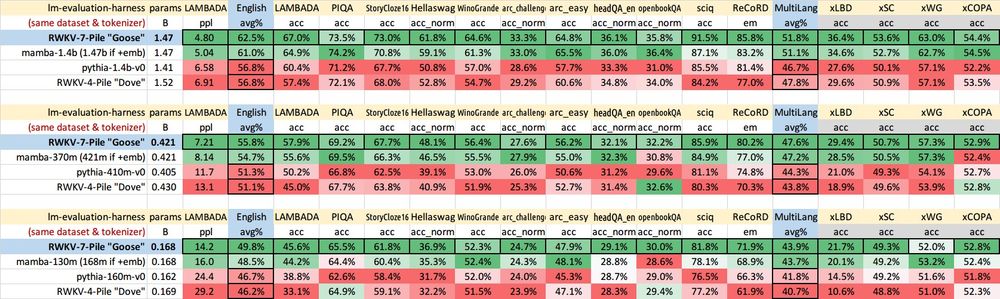
This is in addition to our latest candidate RWKV-7 "Goose" 🪿 architecture. Which we are excited for, as it shows early signs of a step jump from our v6 finch 🐤 models.
Which we are scheduled to do a conversion run as well for 32B, and 70B class models
x.com/BlinkDL_AI/s...
Which we are scheduled to do a conversion run as well for 32B, and 70B class models
x.com/BlinkDL_AI/s...
December 11, 2024 at 9:17 PM
This is in addition to our latest candidate RWKV-7 "Goose" 🪿 architecture. Which we are excited for, as it shows early signs of a step jump from our v6 finch 🐤 models.
Which we are scheduled to do a conversion run as well for 32B, and 70B class models
x.com/BlinkDL_AI/s...
Which we are scheduled to do a conversion run as well for 32B, and 70B class models
x.com/BlinkDL_AI/s...
While the Q-RWKV-32B Preview takes the crown as our new Frontier RWKV model, unfortunately this is not trained on our usual 100+ language dataset
For that refer to our other models coming live today. Including a 37B MoE model, and updated 7B
substack.recursal.ai/p/qrwkv6-and...
For that refer to our other models coming live today. Including a 37B MoE model, and updated 7B
substack.recursal.ai/p/qrwkv6-and...

QRWKV6 and a charm of finches
And how QRWKV6 stands out among our various RWKV6 experiments
substack.recursal.ai
December 11, 2024 at 9:17 PM
While the Q-RWKV-32B Preview takes the crown as our new Frontier RWKV model, unfortunately this is not trained on our usual 100+ language dataset
For that refer to our other models coming live today. Including a 37B MoE model, and updated 7B
substack.recursal.ai/p/qrwkv6-and...
For that refer to our other models coming live today. Including a 37B MoE model, and updated 7B
substack.recursal.ai/p/qrwkv6-and...
More details on how we did this soon, but tldr:
- take qwen 32B
- freeze feedforward
- replace QKV attention layers, with RWKV6 layers
- train RWKV layers
- unfreeze feedforward & train all layers
You can try the models on featherless AI today:
featherless.ai/models/recur...
- take qwen 32B
- freeze feedforward
- replace QKV attention layers, with RWKV6 layers
- train RWKV layers
- unfreeze feedforward & train all layers
You can try the models on featherless AI today:
featherless.ai/models/recur...
recursal/QRWKV6-32B-Instruct-Preview-v0.1 - Featherless.ai
# recursal/QRWKV6-32B-Instruct-Preview-v0.1
> Compute sponsored by [TensorWave](https://tensorwave.com) - Access MI300X today!
QRWKV6 32B Instruct Preview is one of the largest and strongest RWK...
featherless.ai
December 11, 2024 at 9:17 PM
More details on how we did this soon, but tldr:
- take qwen 32B
- freeze feedforward
- replace QKV attention layers, with RWKV6 layers
- train RWKV layers
- unfreeze feedforward & train all layers
You can try the models on featherless AI today:
featherless.ai/models/recur...
- take qwen 32B
- freeze feedforward
- replace QKV attention layers, with RWKV6 layers
- train RWKV layers
- unfreeze feedforward & train all layers
You can try the models on featherless AI today:
featherless.ai/models/recur...
This also prove out that the RWKV attention head mechanic works on larger scales
Our 72B model is already "on its way" before the end of the month.
Once we cross that line, RWKV would now be at the scale which meets most Enterprise needs
Release Details:
substack.recursal.ai/p/q-rwkv-6-3...
Our 72B model is already "on its way" before the end of the month.
Once we cross that line, RWKV would now be at the scale which meets most Enterprise needs
Release Details:
substack.recursal.ai/p/q-rwkv-6-3...

Q-RWKV-6 32B Instruct Preview
The strongest, and largest RWKV model variant to date: QRWKV6 32B Instruct Preview
substack.recursal.ai
December 11, 2024 at 9:17 PM
This also prove out that the RWKV attention head mechanic works on larger scales
Our 72B model is already "on its way" before the end of the month.
Once we cross that line, RWKV would now be at the scale which meets most Enterprise needs
Release Details:
substack.recursal.ai/p/q-rwkv-6-3...
Our 72B model is already "on its way" before the end of the month.
Once we cross that line, RWKV would now be at the scale which meets most Enterprise needs
Release Details:
substack.recursal.ai/p/q-rwkv-6-3...
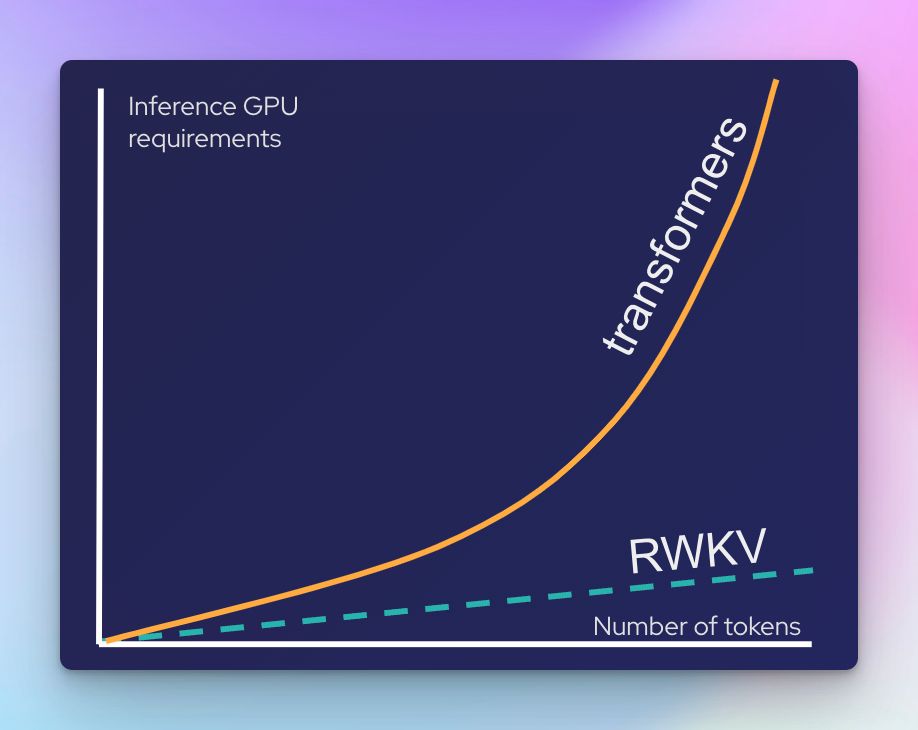
Why is this important?
With the move to inference time thinking (O1-reasoning, chain-of-thought, etc). There is an increasing need for scalable inference over larger context lengths
The quadratic inference cost scaling of transformer models is ill suited for such long contexts
With the move to inference time thinking (O1-reasoning, chain-of-thought, etc). There is an increasing need for scalable inference over larger context lengths
The quadratic inference cost scaling of transformer models is ill suited for such long contexts
December 11, 2024 at 9:17 PM
Why is this important?
With the move to inference time thinking (O1-reasoning, chain-of-thought, etc). There is an increasing need for scalable inference over larger context lengths
The quadratic inference cost scaling of transformer models is ill suited for such long contexts
With the move to inference time thinking (O1-reasoning, chain-of-thought, etc). There is an increasing need for scalable inference over larger context lengths
The quadratic inference cost scaling of transformer models is ill suited for such long contexts
You can find out more details here
substack.recursal.ai/p/q-rwkv-6-3...
Considering its 3AM where I am.
I will be napping first before adding more details, and doing a more formal tweet thread
substack.recursal.ai/p/q-rwkv-6-3...
Considering its 3AM where I am.
I will be napping first before adding more details, and doing a more formal tweet thread
Q-RWKV-6 32B Instruct Preview
The strongest, and largest RWKV model variant to date: QRWKV6 32B Instruct Preview
substack.recursal.ai
December 11, 2024 at 11:14 AM
You can find out more details here
substack.recursal.ai/p/q-rwkv-6-3...
Considering its 3AM where I am.
I will be napping first before adding more details, and doing a more formal tweet thread
substack.recursal.ai/p/q-rwkv-6-3...
Considering its 3AM where I am.
I will be napping first before adding more details, and doing a more formal tweet thread
Last neurips I spent more time meeting ppl outside the convention
Then the posters itself: so that’s fair haha 😅
Then the posters itself: so that’s fair haha 😅
December 9, 2024 at 9:44 PM
Last neurips I spent more time meeting ppl outside the convention
Then the posters itself: so that’s fair haha 😅
Then the posters itself: so that’s fair haha 😅
Honestly even internal org A/B human eval with a handful of people…. is a step up from what most orgs are doing 😭
December 7, 2024 at 7:14 PM
Honestly even internal org A/B human eval with a handful of people…. is a step up from what most orgs are doing 😭
Finally done with work meetings and got to chill and slowly experience proper Canadian food:
Poutine and beer at a bar
Discord Quebec gang: Toronto Poutine ain’t real Poutine 🤣
(Will be back in SF tomorrow)
Poutine and beer at a bar
Discord Quebec gang: Toronto Poutine ain’t real Poutine 🤣
(Will be back in SF tomorrow)

December 6, 2024 at 11:22 PM
Finally done with work meetings and got to chill and slowly experience proper Canadian food:
Poutine and beer at a bar
Discord Quebec gang: Toronto Poutine ain’t real Poutine 🤣
(Will be back in SF tomorrow)
Poutine and beer at a bar
Discord Quebec gang: Toronto Poutine ain’t real Poutine 🤣
(Will be back in SF tomorrow)
Clearly. Ain’t enough to make a proper snowball (I tried sadly 🥹)
December 6, 2024 at 10:57 PM
Clearly. Ain’t enough to make a proper snowball (I tried sadly 🥹)