



Paul Bogdan
@pbogdan.bsky.social
Postdoc at Duke in Psychology & Neuroscience.
I have a website: https://pbogdan.com/
I have a website: https://pbogdan.com/
Great to hear! Making the code presentable took some time, so I'm glad you mentioned that this was actually productive!
October 13, 2025 at 12:03 PM
Great to hear! Making the code presentable took some time, so I'm glad you mentioned that this was actually productive!
Sir, would you be available to please provide a quick fantasy court ruling as a neutral third party (something related to draft order for a soon upcoming draft)? If so, I will send you the details
August 27, 2025 at 12:22 PM
Sir, would you be available to please provide a quick fantasy court ruling as a neutral third party (something related to draft order for a soon upcoming draft)? If so, I will send you the details
I don't doubt the author's findings using their design, but it seems like a leap to claim that their findings based on GPT-4o-mini apply to contemporary state-of-the-art or near-state-of-the-art LLMs
August 25, 2025 at 12:38 PM
I don't doubt the author's findings using their design, but it seems like a leap to claim that their findings based on GPT-4o-mini apply to contemporary state-of-the-art or near-state-of-the-art LLMs
Attempting to replicate this... I plucked one random low-profile retracted paper (pmc.ncbi.nlm.nih.gov/articles/PMC...) and asked GPT-5/Gemini/Claude "What do you think of this paper," with the title + abstract pasted. No model mentioned a retraction, but all said the paper has low evidential value
August 25, 2025 at 12:28 PM
Attempting to replicate this... I plucked one random low-profile retracted paper (pmc.ncbi.nlm.nih.gov/articles/PMC...) and asked GPT-5/Gemini/Claude "What do you think of this paper," with the title + abstract pasted. No model mentioned a retraction, but all said the paper has low evidential value
6/🧵 Together, these findings produce a map of how we build meaning: from concept coding in the occipitotemporal cortex to relational integration in frontoparietal and striatal regions
Come see our full preprint here: www.biorxiv.org/content/10.1...
(Thanks for reading!)
Come see our full preprint here: www.biorxiv.org/content/10.1...
(Thanks for reading!)
June 24, 2025 at 1:49 PM
6/🧵 Together, these findings produce a map of how we build meaning: from concept coding in the occipitotemporal cortex to relational integration in frontoparietal and striatal regions
Come see our full preprint here: www.biorxiv.org/content/10.1...
(Thanks for reading!)
Come see our full preprint here: www.biorxiv.org/content/10.1...
(Thanks for reading!)
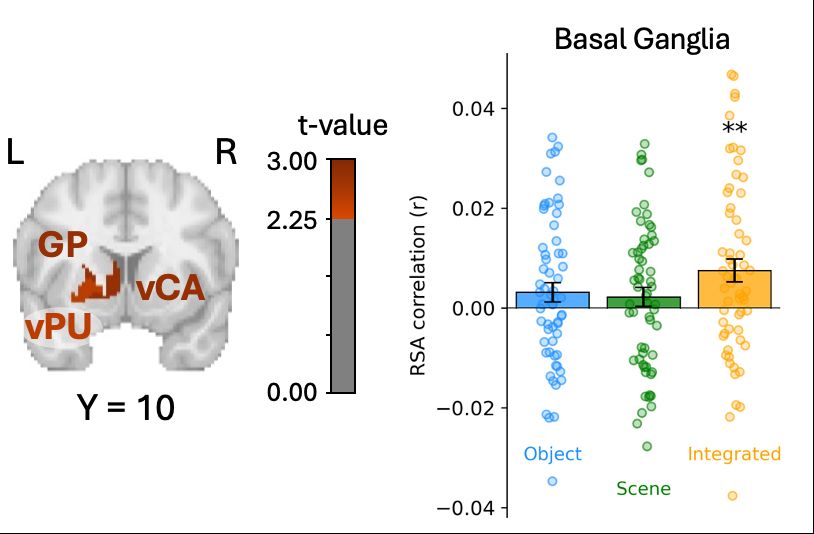
5/🧵 Relational analysis also identified a role of the dorsal striatum. Despite not being typically seen as an area for semantic coding, striatal regions robustly represent relational content, and the strength of this representation predicts participants’ judgments about item pairs
June 24, 2025 at 1:49 PM
5/🧵 Relational analysis also identified a role of the dorsal striatum. Despite not being typically seen as an area for semantic coding, striatal regions robustly represent relational content, and the strength of this representation predicts participants’ judgments about item pairs
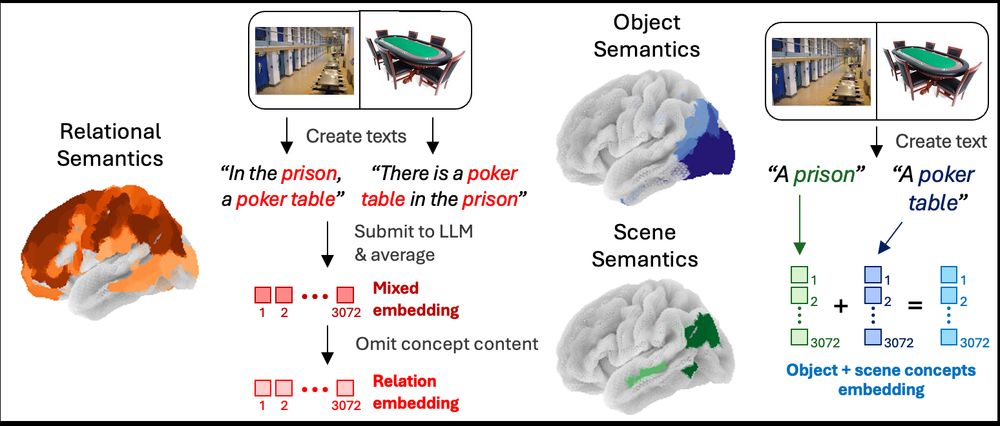
4/🧵 We used LLM embeddings to model neural representations via fMRI and RSA, which revealed dissociations in information processing. Occipitotemporal structures parse concepts but not relations. Conversely, frontoparietal regions (especially the PFC) almost exclusively encode relational information
June 24, 2025 at 1:49 PM
4/🧵 We used LLM embeddings to model neural representations via fMRI and RSA, which revealed dissociations in information processing. Occipitotemporal structures parse concepts but not relations. Conversely, frontoparietal regions (especially the PFC) almost exclusively encode relational information
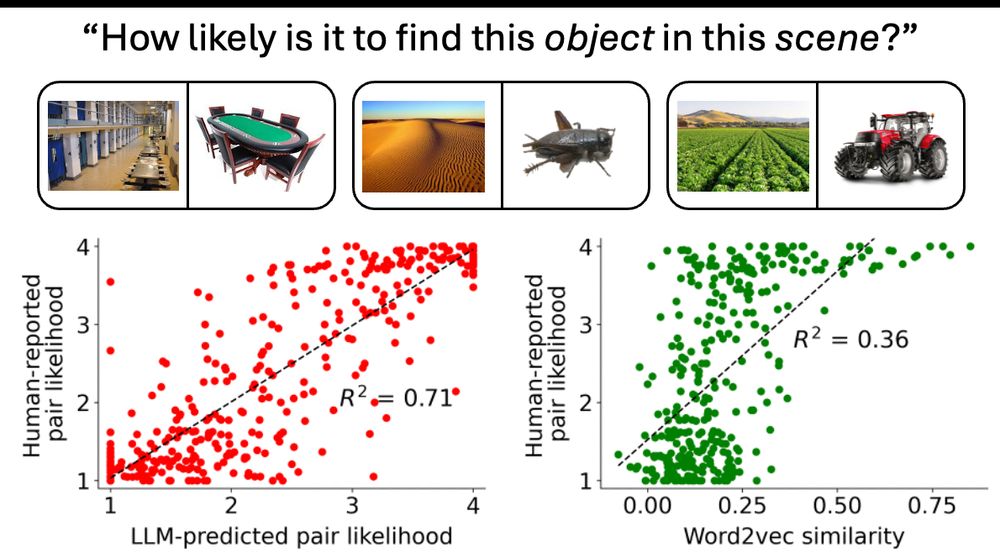
3/🧵 Next, we tested relational information. LLM activity for texts like “A prison and poker table” robustly predicts human ratings on the likelihood of finding a poker table in a prison. Further analyses show how LLMs parsing such texts also capture precise propositional relational features
June 24, 2025 at 1:49 PM
3/🧵 Next, we tested relational information. LLM activity for texts like “A prison and poker table” robustly predicts human ratings on the likelihood of finding a poker table in a prison. Further analyses show how LLMs parsing such texts also capture precise propositional relational features
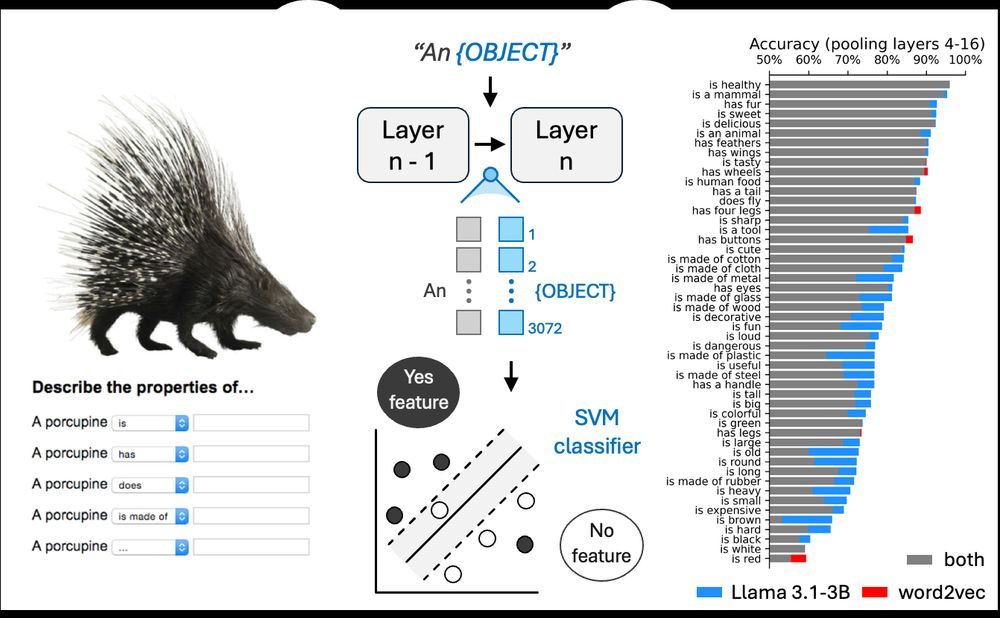
2/🧵 To produce concept embeddings, we submit a short text (“A porcupine”) to contemporary LLMs and extract the LLMs’ residual stream. Leveraging data from our normative feature study, we find that LLM embeddings better predict human-reported propositional features than older models (word2vec, BERT)
June 24, 2025 at 1:49 PM
2/🧵 To produce concept embeddings, we submit a short text (“A porcupine”) to contemporary LLMs and extract the LLMs’ residual stream. Leveraging data from our normative feature study, we find that LLM embeddings better predict human-reported propositional features than older models (word2vec, BERT)
I figure the results showing how, nowadays, stronger p-values are linked to more citations and higher-IF journals points to progress that is difficult to explain with just mturk
June 10, 2025 at 9:36 PM
I figure the results showing how, nowadays, stronger p-values are linked to more citations and higher-IF journals points to progress that is difficult to explain with just mturk
Another bit from the paper, perhaps consistent with your message: "there remain many studies publishing weak p values, suggesting that there have still been issues in eliminating the most problematic research. This deserves consideration despite the aggregate trend toward fewer fragile findings."
June 10, 2025 at 9:23 PM
Another bit from the paper, perhaps consistent with your message: "there remain many studies publishing weak p values, suggesting that there have still been issues in eliminating the most problematic research. This deserves consideration despite the aggregate trend toward fewer fragile findings."
Averaging to 26% isn't "mission accomplished", but this 26% value (or, say, 20% per Peter's simulations) still seems like a meaningful reference. Considering it seems more informative than just expecting 0% (i.e., seeing 33 ➜ 26% as just eliminating only 7/33 of problematic studies)
June 10, 2025 at 9:18 PM
Averaging to 26% isn't "mission accomplished", but this 26% value (or, say, 20% per Peter's simulations) still seems like a meaningful reference. Considering it seems more informative than just expecting 0% (i.e., seeing 33 ➜ 26% as just eliminating only 7/33 of problematic studies)
I figure the most appropriate conclusion would be that there are many studies achieving >80% power along with numerous studies below this
June 10, 2025 at 9:14 PM
I figure the most appropriate conclusion would be that there are many studies achieving >80% power along with numerous studies below this
> But it should be obvious that the problem in psychology was not that 6% of the papers had p-values in a bad range.
I also talk about this 6% number in this other thread: bsky.app/profile/did:...
I also talk about this 6% number in this other thread: bsky.app/profile/did:...

Seeing the discussion on fragile p-values makes me feel that a fair chunk of people are signing on without thinking too deeply. The argument goes that fragile p-values were 32% of findings and are now 26% of findings, roughly the expected amount...
www.science.org/content/arti...
www.science.org/content/arti...

‘A big win’: Dubious statistical results are becoming less common in psychology
Fewer papers are reporting findings on the border of statistical significance, a potential marker of dodgy research practices
www.science.org
June 10, 2025 at 6:13 PM
> But it should be obvious that the problem in psychology was not that 6% of the papers had p-values in a bad range.
I also talk about this 6% number in this other thread: bsky.app/profile/did:...
I also talk about this 6% number in this other thread: bsky.app/profile/did:...
Although we certainly shouldn't conclude that the replication crisis is over, it seems fair to say that there has been productive progress
June 10, 2025 at 6:12 PM
Although we certainly shouldn't conclude that the replication crisis is over, it seems fair to say that there has been productive progress
Continuing on this response to "The replication crisis in psychology is over", it is also worth considering psychology's place relative to other fields. Looking at analogous p-value data from neuro or med journals, only psychology seems to make a meaningful push to increase the strength of results
June 10, 2025 at 6:11 PM
Continuing on this response to "The replication crisis in psychology is over", it is also worth considering psychology's place relative to other fields. Looking at analogous p-value data from neuro or med journals, only psychology seems to make a meaningful push to increase the strength of results
The replication crisis is certainly not over, and the paper always refers to it as ongoing. However, I wonder what is the online layperson's view of psychology replicability. The crisis entered public consciousness, but I doubt the public is as aware of the progress to increase replicability
June 10, 2025 at 6:09 PM
The replication crisis is certainly not over, and the paper always refers to it as ongoing. However, I wonder what is the online layperson's view of psychology replicability. The crisis entered public consciousness, but I doubt the public is as aware of the progress to increase replicability
Small take on your COVID vaccine example, a p-value of p = .01 based on a correlation seems intuitive? Flip a coin 10 times and you'll get heads 9 times 1% of the time. Yet, Pfizer and society should act strongly on that result given their priors on efficacy and given the importance of the topic
June 10, 2025 at 6:04 PM
Small take on your COVID vaccine example, a p-value of p = .01 based on a correlation seems intuitive? Flip a coin 10 times and you'll get heads 9 times 1% of the time. Yet, Pfizer and society should act strongly on that result given their priors on efficacy and given the importance of the topic
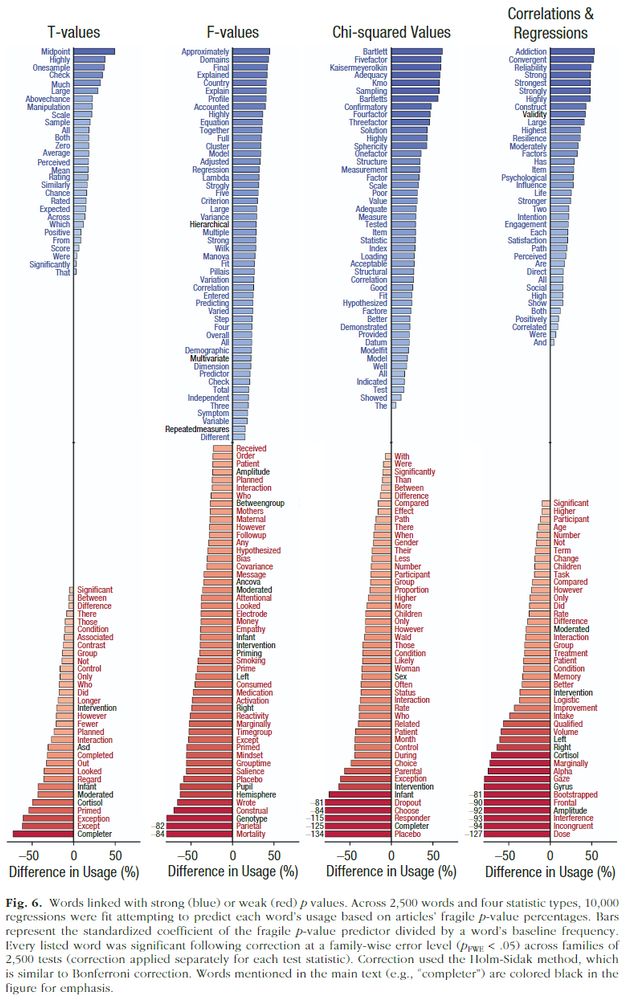
I agree that trying to convert aggregate p-values into a replication rate won't be reliable. Nonetheless, a paper's p-values seem to track something awfully related to replicability. Per Figure 6, fragile p-values neatly identify numerous topics and methods known to produce non-replicable findings
June 10, 2025 at 5:57 PM
I agree that trying to convert aggregate p-values into a replication rate won't be reliable. Nonetheless, a paper's p-values seem to track something awfully related to replicability. Per Figure 6, fragile p-values neatly identify numerous topics and methods known to produce non-replicable findings
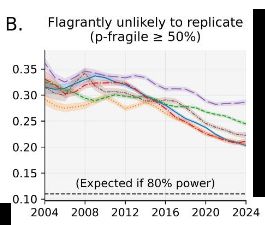
Not sure how informative this would be, but an earlier draft included a subfigure trying to demonstrate that there remain a substantial number of likely problematic papers. Somewhat arbitrarily, the figure showed the percentage of papers where a majority of significant p-values were p > .01
June 10, 2025 at 5:32 PM
Not sure how informative this would be, but an earlier draft included a subfigure trying to demonstrate that there remain a substantial number of likely problematic papers. Somewhat arbitrarily, the figure showed the percentage of papers where a majority of significant p-values were p > .01
I regret not exploring this ~26.4% number more or having a paragraph on why a rate of 26.4% likely wouldn't correspond to entirely kosher studies. Your 16% and 20% results, if I'm reading this correctly, are based on some studies having above 80% power, which seems like a correct assumption
June 10, 2025 at 5:27 PM
I regret not exploring this ~26.4% number more or having a paragraph on why a rate of 26.4% likely wouldn't correspond to entirely kosher studies. Your 16% and 20% results, if I'm reading this correctly, are based on some studies having above 80% power, which seems like a correct assumption
Hi Peter, thanks for these additional analyses. For my simulations of 80% power, I sampled z-scores from a distribution centered at 2.8. This only has a small effect (~0.4%), but I also accounted for the number of p-values each actual paper in the dataset reported then computed the average
June 10, 2025 at 5:15 PM
Hi Peter, thanks for these additional analyses. For my simulations of 80% power, I sampled z-scores from a distribution centered at 2.8. This only has a small effect (~0.4%), but I also accounted for the number of p-values each actual paper in the dataset reported then computed the average
If all studies are either 80% power or 45% power, a 32% level of fragile p-values implies that 25% of studies are questionable.
This math isn't meant to argue that 25% of studies were questionable but to show why a 32% fragile percentage can suggest a rate of questionable studies presumably >6%
This math isn't meant to argue that 25% of studies were questionable but to show why a 32% fragile percentage can suggest a rate of questionable studies presumably >6%
June 10, 2025 at 5:01 PM
If all studies are either 80% power or 45% power, a 32% level of fragile p-values implies that 25% of studies are questionable.
This math isn't meant to argue that 25% of studies were questionable but to show why a 32% fragile percentage can suggest a rate of questionable studies presumably >6%
This math isn't meant to argue that 25% of studies were questionable but to show why a 32% fragile percentage can suggest a rate of questionable studies presumably >6%
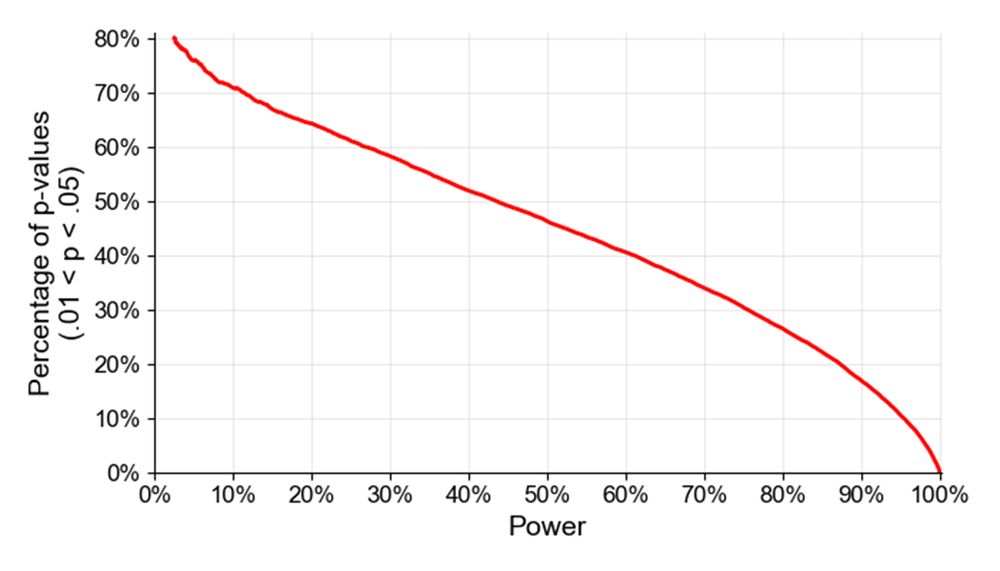
Let's define a study as questionable if it doesn't have 80% power when the sample size as 2.5x. Eyeballing based on playing with G*Power, this means a questionable study is one with <45% power. An effect with 45% power will produce a fragile (.01 < p < .05) p-value about 50% of the time
June 10, 2025 at 5:00 PM
Let's define a study as questionable if it doesn't have 80% power when the sample size as 2.5x. Eyeballing based on playing with G*Power, this means a questionable study is one with <45% power. An effect with 45% power will produce a fragile (.01 < p < .05) p-value about 50% of the time