



Pau Rodriguez
@paurodriguez.bsky.social
Research Scientist at Apple Machine Learning Research. Previously ServiceNow and Element AI in Montréal.
The best part? LinEAS works on LLMs & T2I models.
Huge thanks to the team: Michal Klein, Eleonora Gualdoni, Valentino Maiorca, Arno Blaas, Luca Zappella, Marco Cuturi, & Xavier Suau (who contributed like a 1st author too🥇)!
💻https://github.com/apple/ml-lineas
📄https://arxiv.org/abs/2503.10679
Huge thanks to the team: Michal Klein, Eleonora Gualdoni, Valentino Maiorca, Arno Blaas, Luca Zappella, Marco Cuturi, & Xavier Suau (who contributed like a 1st author too🥇)!
💻https://github.com/apple/ml-lineas
📄https://arxiv.org/abs/2503.10679
October 21, 2025 at 10:00 AM
The best part? LinEAS works on LLMs & T2I models.
Huge thanks to the team: Michal Klein, Eleonora Gualdoni, Valentino Maiorca, Arno Blaas, Luca Zappella, Marco Cuturi, & Xavier Suau (who contributed like a 1st author too🥇)!
💻https://github.com/apple/ml-lineas
📄https://arxiv.org/abs/2503.10679
Huge thanks to the team: Michal Klein, Eleonora Gualdoni, Valentino Maiorca, Arno Blaas, Luca Zappella, Marco Cuturi, & Xavier Suau (who contributed like a 1st author too🥇)!
💻https://github.com/apple/ml-lineas
📄https://arxiv.org/abs/2503.10679
LinEAS globally 🌐 optimizes all 1D-Wasserstein distances between source and target activation distributions at multiple layers via backprop. ✨ Bonus: we can now add a sparsity objective. The result? Targeted 🎯 interventions that preserve fluency with strong conditioning!

October 21, 2025 at 10:00 AM
LinEAS globally 🌐 optimizes all 1D-Wasserstein distances between source and target activation distributions at multiple layers via backprop. ✨ Bonus: we can now add a sparsity objective. The result? Targeted 🎯 interventions that preserve fluency with strong conditioning!
Existing methods estimate layer-wise 🥞 interventions. While powerful, layer-wise methods have some approximation error since the optimization is done locally, without considering multiple layers at once 🤔. We circumvent this problem in LinEAS with an end-to-end optimization ⚙️!
October 21, 2025 at 10:00 AM
Existing methods estimate layer-wise 🥞 interventions. While powerful, layer-wise methods have some approximation error since the optimization is done locally, without considering multiple layers at once 🤔. We circumvent this problem in LinEAS with an end-to-end optimization ⚙️!
🦊Activation Steering modifies a model's internal activations to control its output. Think of a slider 🎚️ that gradually adds a concept, like art style 🎨 to the output. This is also a powerful tool for safety, steering models away from harmful content.

October 21, 2025 at 10:00 AM
🦊Activation Steering modifies a model's internal activations to control its output. Think of a slider 🎚️ that gradually adds a concept, like art style 🎨 to the output. This is also a powerful tool for safety, steering models away from harmful content.
Kudos to all co-authors 👏 Arno Blaas, Michal Klein, Luca Zappella, Nicholas Apostoloff, Marco Cuturi, and Xavier Suau.
Extra 👏 to Xavi for making this so great! Like a friend would say, he's the Rolls-Royce of the co-authors, and he should be regarded the first author too!
Extra 👏 to Xavi for making this so great! Like a friend would say, he's the Rolls-Royce of the co-authors, and he should be regarded the first author too!
December 10, 2024 at 1:09 PM
Kudos to all co-authors 👏 Arno Blaas, Michal Klein, Luca Zappella, Nicholas Apostoloff, Marco Cuturi, and Xavier Suau.
Extra 👏 to Xavi for making this so great! Like a friend would say, he's the Rolls-Royce of the co-authors, and he should be regarded the first author too!
Extra 👏 to Xavi for making this so great! Like a friend would say, he's the Rolls-Royce of the co-authors, and he should be regarded the first author too!
Summary:
🤝 Unifying activation steering w/ OT.
✨ Linear-AcT preserves distributions w/ interpretable ([0, 1]) strength.
💪 Robust: models/layers/modalities
💬 LLMs: toxicity mitigation, truthfulness and concept induction,
🌄 T2I: style induction and concept negation.
🚀 Negligible cost!
🤝 Unifying activation steering w/ OT.
✨ Linear-AcT preserves distributions w/ interpretable ([0, 1]) strength.
💪 Robust: models/layers/modalities
💬 LLMs: toxicity mitigation, truthfulness and concept induction,
🌄 T2I: style induction and concept negation.
🚀 Negligible cost!
December 10, 2024 at 1:09 PM
Summary:
🤝 Unifying activation steering w/ OT.
✨ Linear-AcT preserves distributions w/ interpretable ([0, 1]) strength.
💪 Robust: models/layers/modalities
💬 LLMs: toxicity mitigation, truthfulness and concept induction,
🌄 T2I: style induction and concept negation.
🚀 Negligible cost!
🤝 Unifying activation steering w/ OT.
✨ Linear-AcT preserves distributions w/ interpretable ([0, 1]) strength.
💪 Robust: models/layers/modalities
💬 LLMs: toxicity mitigation, truthfulness and concept induction,
🌄 T2I: style induction and concept negation.
🚀 Negligible cost!
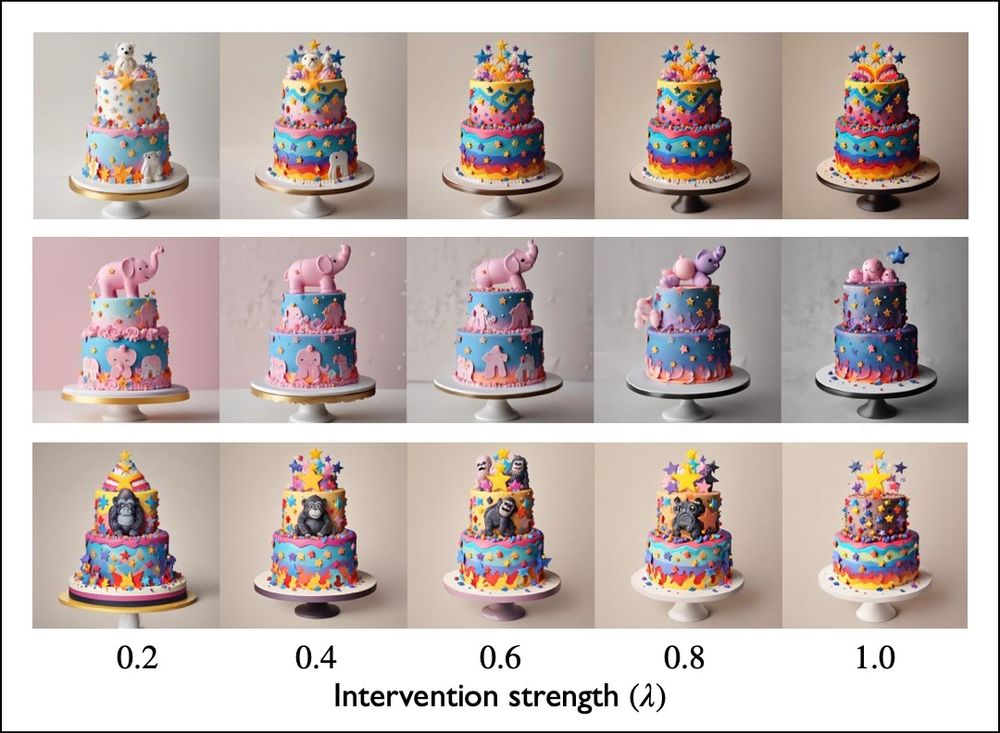
8/9 T2I models tend to generate negated concepts 😮
In the image, StableDiffusion XL prompted with: “2 tier cake with multicolored stars attached to it and no {white bear, pink elephant, gorilla} can be seen.”
✨Linear-AcT makes the negated concept disappear✨
In the image, StableDiffusion XL prompted with: “2 tier cake with multicolored stars attached to it and no {white bear, pink elephant, gorilla} can be seen.”
✨Linear-AcT makes the negated concept disappear✨
December 10, 2024 at 1:09 PM
8/9 T2I models tend to generate negated concepts 😮
In the image, StableDiffusion XL prompted with: “2 tier cake with multicolored stars attached to it and no {white bear, pink elephant, gorilla} can be seen.”
✨Linear-AcT makes the negated concept disappear✨
In the image, StableDiffusion XL prompted with: “2 tier cake with multicolored stars attached to it and no {white bear, pink elephant, gorilla} can be seen.”
✨Linear-AcT makes the negated concept disappear✨
7/9 And here we induce Cyberpunk 🤖 for the same prompt!
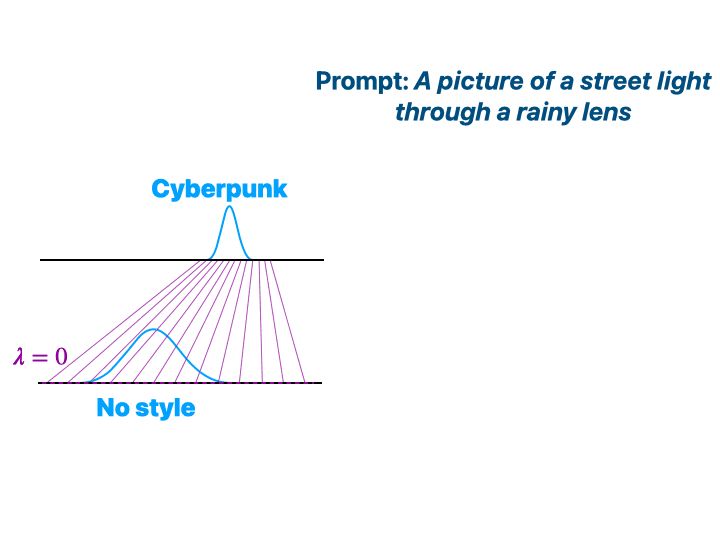
December 10, 2024 at 1:09 PM
7/9 And here we induce Cyberpunk 🤖 for the same prompt!
6/9 Amazingly, we can condition Text-to-Image (T2I) Diffusion with the same exact method we used for LLMs! 🤯
In this example, we induce a specific style (Art Nouveau 🎨), which we can accurately control with our λ parameter.
In this example, we induce a specific style (Art Nouveau 🎨), which we can accurately control with our λ parameter.
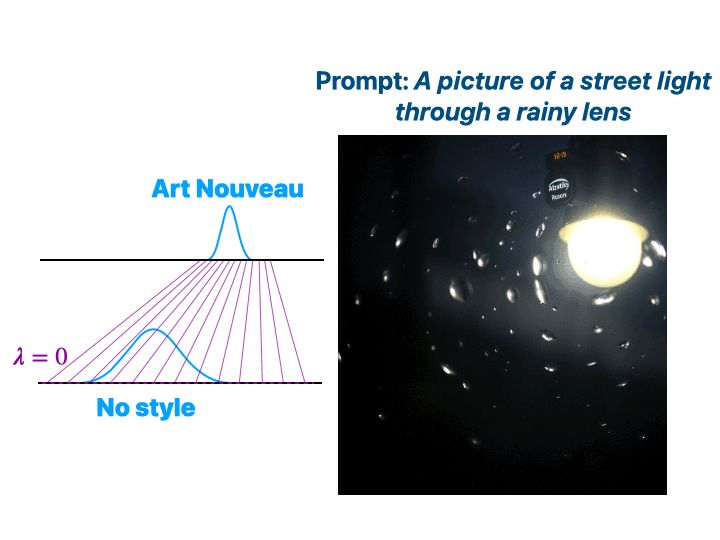
December 10, 2024 at 1:09 PM
6/9 Amazingly, we can condition Text-to-Image (T2I) Diffusion with the same exact method we used for LLMs! 🤯
In this example, we induce a specific style (Art Nouveau 🎨), which we can accurately control with our λ parameter.
In this example, we induce a specific style (Art Nouveau 🎨), which we can accurately control with our λ parameter.
5/9 With Linear-AcT, we achieve great results in LLM 👿 toxicity mitigation and 👩🏼⚖️ truthfulness induction.
And the best result is always obtained at λ=1, as opposed to vector-based steering methods!
And the best result is always obtained at λ=1, as opposed to vector-based steering methods!
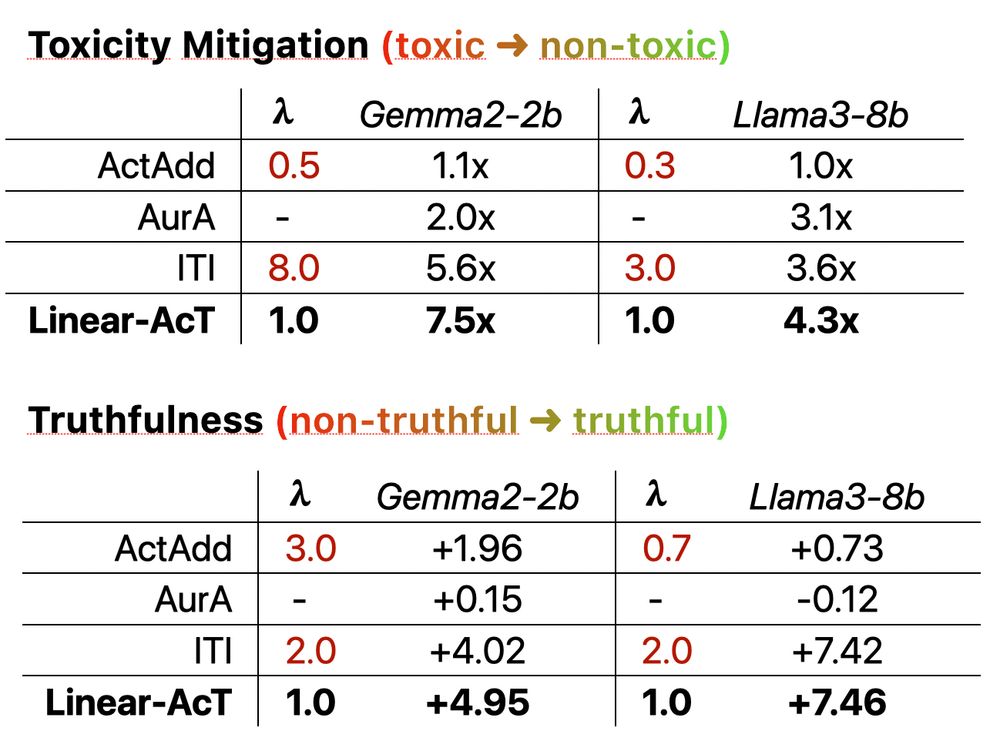
December 10, 2024 at 1:09 PM
5/9 With Linear-AcT, we achieve great results in LLM 👿 toxicity mitigation and 👩🏼⚖️ truthfulness induction.
And the best result is always obtained at λ=1, as opposed to vector-based steering methods!
And the best result is always obtained at λ=1, as opposed to vector-based steering methods!
4/9 Linear-AcT preserves target distributions, with interpretable strength λ 🌈
🍰 All we need is two small sets of sentences {a},{b} from source and target distributions to estimate the Optimal Transport (OT) map 🚚
🚀 We linearize the map for speed/memory, thus ⭐Linear-AcT⭐
🍰 All we need is two small sets of sentences {a},{b} from source and target distributions to estimate the Optimal Transport (OT) map 🚚
🚀 We linearize the map for speed/memory, thus ⭐Linear-AcT⭐
December 10, 2024 at 1:09 PM
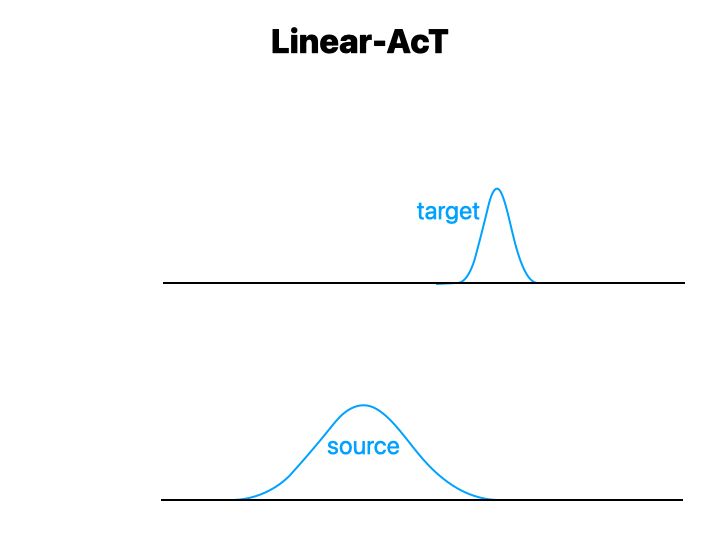
4/9 Linear-AcT preserves target distributions, with interpretable strength λ 🌈
🍰 All we need is two small sets of sentences {a},{b} from source and target distributions to estimate the Optimal Transport (OT) map 🚚
🚀 We linearize the map for speed/memory, thus ⭐Linear-AcT⭐
🍰 All we need is two small sets of sentences {a},{b} from source and target distributions to estimate the Optimal Transport (OT) map 🚚
🚀 We linearize the map for speed/memory, thus ⭐Linear-AcT⭐
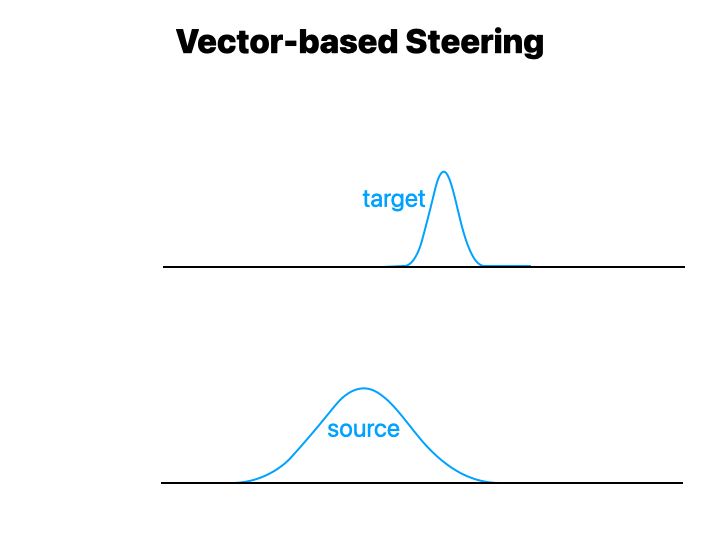
3/9 An activation has a different output distributions per behavior, eg. 🦠 toxic (source) and 😊 non-toxic (target). i) Vector-based AS moves activations OOD 🤯, with catastrophic consequences 💥 harming model utility. ii) The strength λ is unbounded and non-interpretable 🤨!
December 10, 2024 at 1:09 PM
3/9 An activation has a different output distributions per behavior, eg. 🦠 toxic (source) and 😊 non-toxic (target). i) Vector-based AS moves activations OOD 🤯, with catastrophic consequences 💥 harming model utility. ii) The strength λ is unbounded and non-interpretable 🤨!
2/9 🤓 Activation Steering (AS) is a fast and cheap alternative for alignment/control.
Most AS techniques perform a vector addition such as a* = a + λv, where v is some estimated vector and λ the conditioning strength. How v is estimated differs for each method.
Most AS techniques perform a vector addition such as a* = a + λv, where v is some estimated vector and λ the conditioning strength. How v is estimated differs for each method.
December 10, 2024 at 1:09 PM
2/9 🤓 Activation Steering (AS) is a fast and cheap alternative for alignment/control.
Most AS techniques perform a vector addition such as a* = a + λv, where v is some estimated vector and λ the conditioning strength. How v is estimated differs for each method.
Most AS techniques perform a vector addition such as a* = a + λv, where v is some estimated vector and λ the conditioning strength. How v is estimated differs for each method.
1/9 🤔 How do we currently align/control generative models?
- Pre-prompting
- Fine-tuning
- RLHF
However, these techniques can be slow/expensive! 🐢
- Pre-prompting
- Fine-tuning
- RLHF
However, these techniques can be slow/expensive! 🐢
December 10, 2024 at 1:09 PM
1/9 🤔 How do we currently align/control generative models?
- Pre-prompting
- Fine-tuning
- RLHF
However, these techniques can be slow/expensive! 🐢
- Pre-prompting
- Fine-tuning
- RLHF
However, these techniques can be slow/expensive! 🐢