


Paul Krzakala
@paulkrz.bsky.social
We train GRALE on a massive molecular dataset (84M molecules).
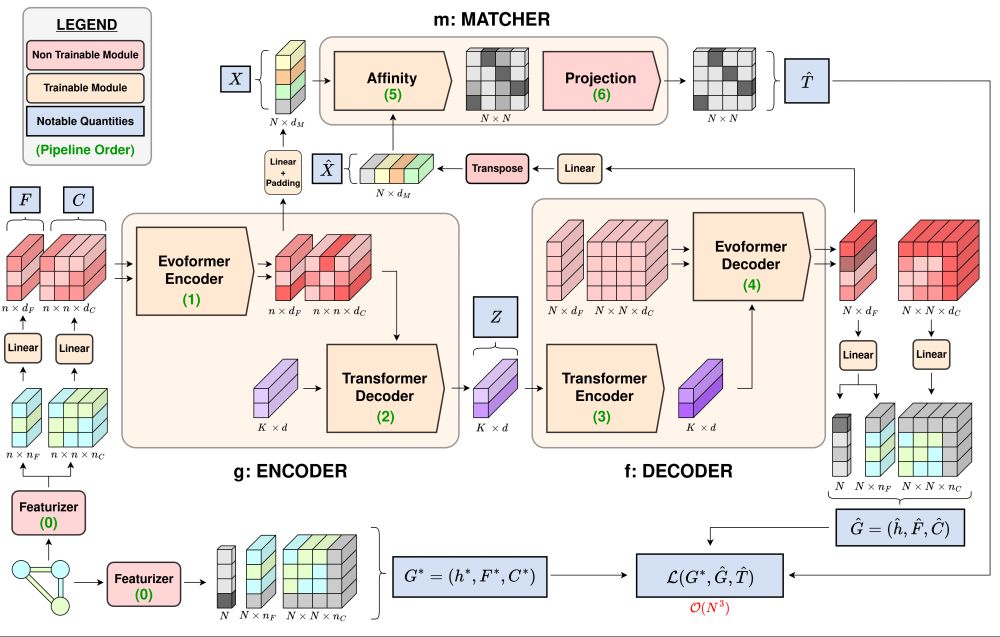
To handle this scale, we introduce a highly expressive architecture that leverages the Evoformer (from AlphaFold) as the encoder, and a new Evoformer Decoder as the decoder 💪.
To handle this scale, we introduce a highly expressive architecture that leverages the Evoformer (from AlphaFold) as the encoder, and a new Evoformer Decoder as the decoder 💪.
October 16, 2025 at 1:11 PM
We train GRALE on a massive molecular dataset (84M molecules).
To handle this scale, we introduce a highly expressive architecture that leverages the Evoformer (from AlphaFold) as the encoder, and a new Evoformer Decoder as the decoder 💪.
To handle this scale, we introduce a highly expressive architecture that leverages the Evoformer (from AlphaFold) as the encoder, and a new Evoformer Decoder as the decoder 💪.
The representations learned by 🏆 GRALE 🏆 achieve SOTA performance across a wide variety of downstream tasks.
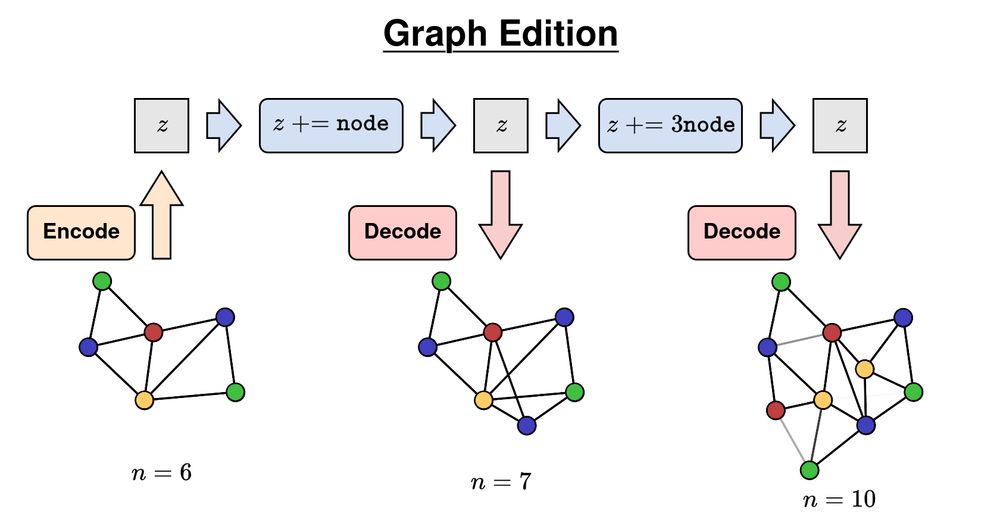
More importantly, it enable complex graph manipulations (interpolation, editing, etc.) as simple vector operations in the latent space!
More importantly, it enable complex graph manipulations (interpolation, editing, etc.) as simple vector operations in the latent space!

October 16, 2025 at 1:11 PM
The representations learned by 🏆 GRALE 🏆 achieve SOTA performance across a wide variety of downstream tasks.
More importantly, it enable complex graph manipulations (interpolation, editing, etc.) as simple vector operations in the latent space!
More importantly, it enable complex graph manipulations (interpolation, editing, etc.) as simple vector operations in the latent space!
Instead of relying on software 🤖 to solve the general graph matching problem (NP-hard),
we train an additional module 🧠 that specializes in aligning the input and its reconstruction.
With this data-driven approach, the NP-hardness barrier effectively disappears!
we train an additional module 🧠 that specializes in aligning the input and its reconstruction.
With this data-driven approach, the NP-hardness barrier effectively disappears!

October 16, 2025 at 1:11 PM
Instead of relying on software 🤖 to solve the general graph matching problem (NP-hard),
we train an additional module 🧠 that specializes in aligning the input and its reconstruction.
With this data-driven approach, the NP-hardness barrier effectively disappears!
we train an additional module 🧠 that specializes in aligning the input and its reconstruction.
With this data-driven approach, the NP-hardness barrier effectively disappears!