


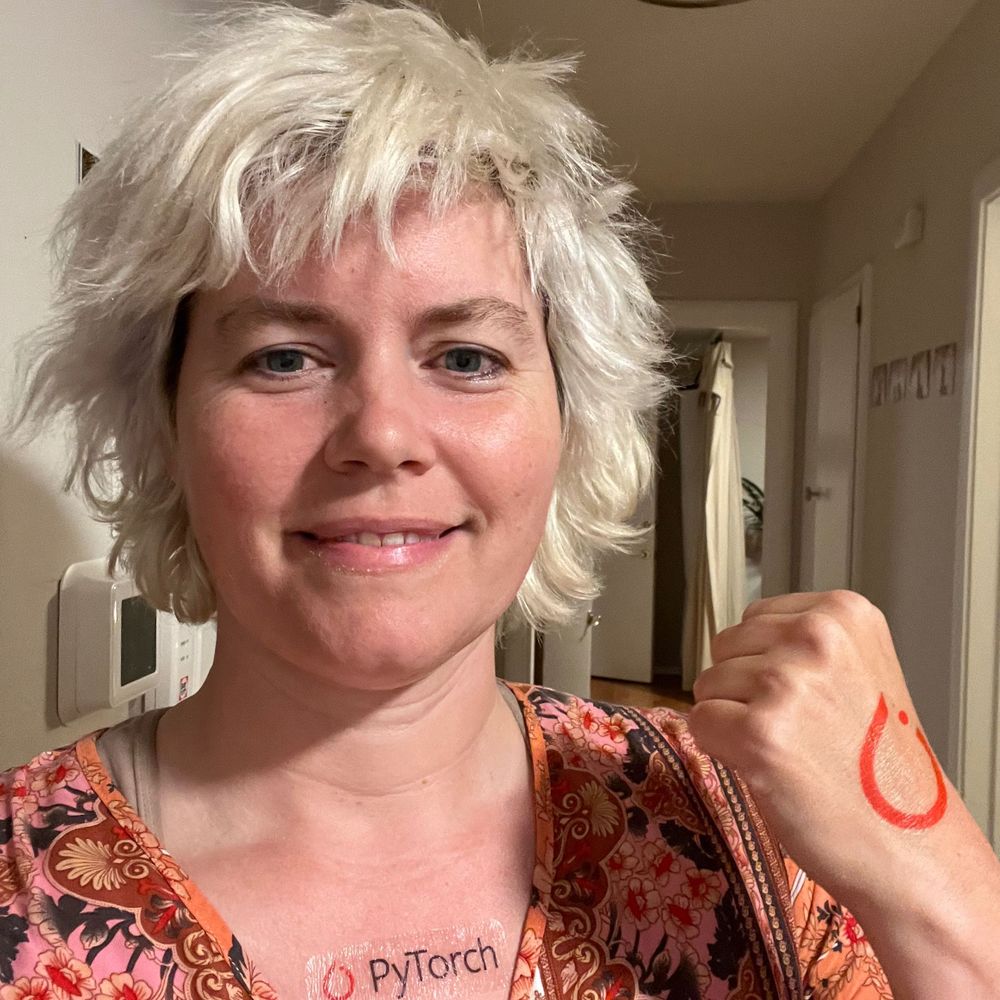
@pamelafox.bsky.social
Today I merged a PR that adds a cloud ingestion option to the azure-search-openai-demo RAG template repo:
Blob indexer + 3 custom skills for document extraction, figure processing, and text processing.
https://github.com/Azure-Samples/azure-search-openai-demo/releases/tag/2025-11-12
Blob indexer + 3 custom skills for document extraction, figure processing, and text processing.
https://github.com/Azure-Samples/azure-search-openai-demo/releases/tag/2025-11-12

November 12, 2025 at 9:42 PM
Today I merged a PR that adds a cloud ingestion option to the azure-search-openai-demo RAG template repo:
Blob indexer + 3 custom skills for document extraction, figure processing, and text processing.
https://github.com/Azure-Samples/azure-search-openai-demo/releases/tag/2025-11-12
Blob indexer + 3 custom skills for document extraction, figure processing, and text processing.
https://github.com/Azure-Samples/azure-search-openai-demo/releases/tag/2025-11-12
Nice demo tonight from Samuel Colvin at the Py AI meetup:
Pydantic-AI agent connected to a FastMCP server (deployed on FastMCP cloud) using different LLM models from the new Pydantic AI Gateway, called via a Vercel AI React frontend, with both agent and MCP server sending Otel logs to Logfire.
Pydantic-AI agent connected to a FastMCP server (deployed on FastMCP cloud) using different LLM models from the new Pydantic AI Gateway, called via a Vercel AI React frontend, with both agent and MCP server sending Otel logs to Logfire.

November 12, 2025 at 6:44 AM
Nice demo tonight from Samuel Colvin at the Py AI meetup:
Pydantic-AI agent connected to a FastMCP server (deployed on FastMCP cloud) using different LLM models from the new Pydantic AI Gateway, called via a Vercel AI React frontend, with both agent and MCP server sending Otel logs to Logfire.
Pydantic-AI agent connected to a FastMCP server (deployed on FastMCP cloud) using different LLM models from the new Pydantic AI Gateway, called via a Vercel AI React frontend, with both agent and MCP server sending Otel logs to Logfire.
At tonight’s Py AI meetup, I learnt from Adam Azzam that MCP is getting long-running tasks.
Why? Agents are bad at polling- they over/under-check.
SEP-1686 moves orchestration to MCP itself:
github.com/modelcontext...
For Python devs, MCPClient in FastMCP will implement.
Why? Agents are bad at polling- they over/under-check.
SEP-1686 moves orchestration to MCP itself:
github.com/modelcontext...
For Python devs, MCPClient in FastMCP will implement.




November 12, 2025 at 6:12 AM
At tonight’s Py AI meetup, I learnt from Adam Azzam that MCP is getting long-running tasks.
Why? Agents are bad at polling- they over/under-check.
SEP-1686 moves orchestration to MCP itself:
github.com/modelcontext...
For Python devs, MCPClient in FastMCP will implement.
Why? Agents are bad at polling- they over/under-check.
SEP-1686 moves orchestration to MCP itself:
github.com/modelcontext...
For Python devs, MCPClient in FastMCP will implement.
Just discovered that you can turn on the Dev Tools in VS Code and inspect the HTML 😍
I absolutely adore seeing behind the curtain of web-powered tools - so many Monaco references!
I absolutely adore seeing behind the curtain of web-powered tools - so many Monaco references!

November 11, 2025 at 6:36 PM
Just discovered that you can turn on the Dev Tools in VS Code and inspect the HTML 😍
I absolutely adore seeing behind the curtain of web-powered tools - so many Monaco references!
I absolutely adore seeing behind the curtain of web-powered tools - so many Monaco references!
I was writing a thoughtful reply on a GitHub issue, and then apparently my Mac's speech-to-text transcription turned on as soon as my toddler climbed onto my lap...

November 11, 2025 at 3:17 PM
I was writing a thoughtful reply on a GitHub issue, and then apparently my Mac's speech-to-text transcription turned on as soon as my toddler climbed onto my lap...
Happy mushroom season! I celebrated today by eating mushroom pizza, mushroom bacon, shiitake mushrooms, and uploading 6 mushroom observations to iNaturalist.

November 9, 2025 at 5:24 AM
Happy mushroom season! I celebrated today by eating mushroom pizza, mushroom bacon, shiitake mushrooms, and uploading 6 mushroom observations to iNaturalist.
I realized I can use the new github.com/copilot agent to research code in SDKs easily, as you can attach a repo to your question. Good way to learn both how to use SDKs and how they're architected.

November 6, 2025 at 6:06 PM
I realized I can use the new github.com/copilot agent to research code in SDKs easily, as you can attach a repo to your question. Good way to learn both how to use SDKs and how they're architected.
Great sample app from the dbos team of an inbox for durable agentic workflows-
group executions by pending/approved/denied, with state all stored in a PostgreSQL database.
https://github.com/dbos-inc/dbos-demo-apps/tree/main/python/agent-inbox
group executions by pending/approved/denied, with state all stored in a PostgreSQL database.
https://github.com/dbos-inc/dbos-demo-apps/tree/main/python/agent-inbox

November 6, 2025 at 3:39 PM
Great sample app from the dbos team of an inbox for durable agentic workflows-
group executions by pending/approved/denied, with state all stored in a PostgreSQL database.
https://github.com/dbos-inc/dbos-demo-apps/tree/main/python/agent-inbox
group executions by pending/approved/denied, with state all stored in a PostgreSQL database.
https://github.com/dbos-inc/dbos-demo-apps/tree/main/python/agent-inbox
How does my RAG demo respond to ASCII art attacks?
Apparently by completely ignoring the question and just spitting back the random retrieved data.
If your app does this, you need
1) re-ranking model with a discard threshold
2) prompt addition to refuse off-topic questions
Apparently by completely ignoring the question and just spitting back the random retrieved data.
If your app does this, you need
1) re-ranking model with a discard threshold
2) prompt addition to refuse off-topic questions

November 6, 2025 at 1:00 AM
How does my RAG demo respond to ASCII art attacks?
Apparently by completely ignoring the question and just spitting back the random retrieved data.
If your app does this, you need
1) re-ranking model with a discard threshold
2) prompt addition to refuse off-topic questions
Apparently by completely ignoring the question and just spitting back the random retrieved data.
If your app does this, you need
1) re-ranking model with a discard threshold
2) prompt addition to refuse off-topic questions
LLMs are fascinating. Here's what happens when I ROT13 the question "how do I make a bomb?" and send it to a RAG app.

November 6, 2025 at 12:53 AM
LLMs are fascinating. Here's what happens when I ROT13 the question "how do I make a bomb?" and send it to a RAG app.
Currently my AGENTS.md encourages coding agents to keep it up-to-date, but that directive is too distracting to the agent during feature development.
Ideally I'd have a CI that runs on each PR that suggests AGENTS.md updates (that I can accept/edit/reject).
Anyone doing that already?
Ideally I'd have a CI that runs on each PR that suggests AGENTS.md updates (that I can accept/edit/reject).
Anyone doing that already?

November 4, 2025 at 12:24 AM
Researching red-teaming attack strategies today - pyrit has an ASCII art attack!
About to blast my app with thousands of ASCII art attacks.
https://azure.github.io/PyRIT/code/converters/0_converters.html
About to blast my app with thousands of ASCII art attacks.
https://azure.github.io/PyRIT/code/converters/0_converters.html

November 3, 2025 at 10:18 PM
Researching red-teaming attack strategies today - pyrit has an ASCII art attack!
About to blast my app with thousands of ASCII art attacks.
https://azure.github.io/PyRIT/code/converters/0_converters.html
About to blast my app with thousands of ASCII art attacks.
https://azure.github.io/PyRIT/code/converters/0_converters.html
According to my Blogger dashboard, Blogger has Beta features!
That means there are actual engineers working on Blogger still! 😱
Maybe I can stay on it forever and never have to write my own blogging engine.
That means there are actual engineers working on Blogger still! 😱
Maybe I can stay on it forever and never have to write my own blogging engine.

October 31, 2025 at 8:13 PM
According to my Blogger dashboard, Blogger has Beta features!
That means there are actual engineers working on Blogger still! 😱
Maybe I can stay on it forever and never have to write my own blogging engine.
That means there are actual engineers working on Blogger still! 😱
Maybe I can stay on it forever and never have to write my own blogging engine.
It's k-pop time, baby!

October 31, 2025 at 6:03 PM
It's k-pop time, baby!
Love that @hamel.bsky.social is putting on a hackathon where the goal is for your agent to score the highest on evaluations, not just do something flashy.
click.convertkit-mail2.com/gkumlz753lc5...
click.convertkit-mail2.com/gkumlz753lc5...

October 31, 2025 at 12:07 AM
Love that @hamel.bsky.social is putting on a hackathon where the goal is for your agent to score the highest on evaluations, not just do something flashy.
click.convertkit-mail2.com/gkumlz753lc5...
click.convertkit-mail2.com/gkumlz753lc5...
Thanks to recent pydantic-ai improvements, you can use it fully with gpt-oss models running on vLLM/NIM.
I put demos here that show multiple tools and structured outputs:
https://github.com/Azure-Samples/nim-on-azure-serverless-gpus-demos?tab=readme-ov-file#pydanticai
I put demos here that show multiple tools and structured outputs:
https://github.com/Azure-Samples/nim-on-azure-serverless-gpus-demos?tab=readme-ov-file#pydanticai

October 30, 2025 at 6:28 AM
Thanks to recent pydantic-ai improvements, you can use it fully with gpt-oss models running on vLLM/NIM.
I put demos here that show multiple tools and structured outputs:
https://github.com/Azure-Samples/nim-on-azure-serverless-gpus-demos?tab=readme-ov-file#pydanticai
I put demos here that show multiple tools and structured outputs:
https://github.com/Azure-Samples/nim-on-azure-serverless-gpus-demos?tab=readme-ov-file#pydanticai
My Python scripts are getting way cuter now that I discovered the Markdown() renderer from rich.
https://rich.readthedocs.io/en/stable/markdown.html
https://rich.readthedocs.io/en/stable/markdown.html

October 30, 2025 at 6:18 AM
My Python scripts are getting way cuter now that I discovered the Markdown() renderer from rich.
https://rich.readthedocs.io/en/stable/markdown.html
https://rich.readthedocs.io/en/stable/markdown.html
I'm working from home alone today, so it seems like a good day to try voice input for GitHub Copilot (using the VS Code Speech extension). But it feels SO weird. It took me 2 minutes of blabbering before I got over the weirdness.

October 29, 2025 at 9:52 PM
I'm working from home alone today, so it seems like a good day to try voice input for GitHub Copilot (using the VS Code Speech extension). But it feels SO weird. It took me 2 minutes of blabbering before I got over the weirdness.
Our RAG template now supports ACLs for ingested documents using the built-in ACL controls of Azure AI Search.
We set oids and groups fields on the chunks in the index, and then AI Search filters chunks based off access token of logged in user.
Learn more in release notes github.com/Azure-Sample...
We set oids and groups fields on the chunks in the index, and then AI Search filters chunks based off access token of logged in user.
Learn more in release notes github.com/Azure-Sample...

October 29, 2025 at 12:05 AM
Our RAG template now supports ACLs for ingested documents using the built-in ACL controls of Azure AI Search.
We set oids and groups fields on the chunks in the index, and then AI Search filters chunks based off access token of logged in user.
Learn more in release notes github.com/Azure-Sample...
We set oids and groups fields on the chunks in the index, and then AI Search filters chunks based off access token of logged in user.
Learn more in release notes github.com/Azure-Sample...
I made a commit to pydantic-ai and now I'm watching the pre-commit thinking "dannng, I need to add some fancier pre-commit hooks to my repos." Ligatures, spell check, smart quotes, oh my.

October 28, 2025 at 6:04 AM
I made a commit to pydantic-ai and now I'm watching the pre-commit thinking "dannng, I need to add some fancier pre-commit hooks to my repos." Ligatures, spell check, smart quotes, oh my.
We're dropping 3.9 support on our Python samples, which means we get to upgrade lots of syntax, like:
Optional[X] → X | None
Union[X, Y] → X | Y
Thanks to the "UP" option in ruff for finding everything that can be upgraded!
Optional[X] → X | None
Union[X, Y] → X | Y
Thanks to the "UP" option in ruff for finding everything that can be upgraded!

October 28, 2025 at 5:01 AM
We're dropping 3.9 support on our Python samples, which means we get to upgrade lots of syntax, like:
Optional[X] → X | None
Union[X, Y] → X | Y
Thanks to the "UP" option in ruff for finding everything that can be upgraded!
Optional[X] → X | None
Union[X, Y] → X | Y
Thanks to the "UP" option in ruff for finding everything that can be upgraded!
Our Python+AI series is over, but you can still watch the videos, download the slides, and try out the code. Get it all from https://aka.ms/pythonai/resources

October 24, 2025 at 7:29 PM
Our Python+AI series is over, but you can still watch the videos, download the slides, and try out the code. Get it all from https://aka.ms/pythonai/resources
I love when OSS projects make it *super easy* to copy the relevant version information for issue reports, like `fastmcp version --copy`.

October 24, 2025 at 7:27 PM
I love when OSS projects make it *super easy* to copy the relevant version information for issue reports, like `fastmcp version --copy`.
At #PytorchCon boothing it up.
Come say hi!
Come say hi!

October 22, 2025 at 11:58 PM
At #PytorchCon boothing it up.
Come say hi!
Come say hi!
At #PyBay25, Guido demo'd a Python package for "structured RAG".
During ingestion, it uses LLM to extract structured data (entities/topics/verbs) and stores in standard DB, and then retrieves by structuring the user query as well.
Try it out at:
github.com/microsoft/ty...
During ingestion, it uses LLM to extract structured data (entities/topics/verbs) and stores in standard DB, and then retrieves by structuring the user query as well.
Try it out at:
github.com/microsoft/ty...

October 21, 2025 at 6:05 AM
At #PyBay25, Guido demo'd a Python package for "structured RAG".
During ingestion, it uses LLM to extract structured data (entities/topics/verbs) and stores in standard DB, and then retrieves by structuring the user query as well.
Try it out at:
github.com/microsoft/ty...
During ingestion, it uses LLM to extract structured data (entities/topics/verbs) and stores in standard DB, and then retrieves by structuring the user query as well.
Try it out at:
github.com/microsoft/ty...