



Oskar van der Wal
@ovdw.bsky.social
Technology specialist at the EU AI Office / AI Safety / Prev: University of Amsterdam, EleutherAI, BigScience
Thoughts & opinions are my own and do not necessarily represent my employer.
Thoughts & opinions are my own and do not necessarily represent my employer.
💬Panel discussion with Sally Haslanger and Marjolein Lanzing: A philosophical perspective on algorithmic discrimination
Is discrimination the right way to frame the issues of lang tech? Or should we answer deeper rooted questions? And how does tech fit in systems of oppression?
Is discrimination the right way to frame the issues of lang tech? Or should we answer deeper rooted questions? And how does tech fit in systems of oppression?

November 15, 2024 at 4:36 PM
💬Panel discussion with Sally Haslanger and Marjolein Lanzing: A philosophical perspective on algorithmic discrimination
Is discrimination the right way to frame the issues of lang tech? Or should we answer deeper rooted questions? And how does tech fit in systems of oppression?
Is discrimination the right way to frame the issues of lang tech? Or should we answer deeper rooted questions? And how does tech fit in systems of oppression?
📄Undesirable Biases in NLP: Addressing Challenges of Measurement
We also presented our own work on strategies for testing the validity and reliability of LM bias measures:
www.jair.org/index.php/ja...
We also presented our own work on strategies for testing the validity and reliability of LM bias measures:
www.jair.org/index.php/ja...

November 15, 2024 at 4:36 PM
📄Undesirable Biases in NLP: Addressing Challenges of Measurement
We also presented our own work on strategies for testing the validity and reliability of LM bias measures:
www.jair.org/index.php/ja...
We also presented our own work on strategies for testing the validity and reliability of LM bias measures:
www.jair.org/index.php/ja...
🔑Keynote @zeerak.bsky.social: On the promise of equitable machine learning technologies
Can we create equitable ML technologies? Can statistical models faithfully express human language? Or are tokenizers "tokenizing" people—creating a Frankenstein monster of lived experiences?
Can we create equitable ML technologies? Can statistical models faithfully express human language? Or are tokenizers "tokenizing" people—creating a Frankenstein monster of lived experiences?

November 15, 2024 at 4:36 PM
🔑Keynote @zeerak.bsky.social: On the promise of equitable machine learning technologies
Can we create equitable ML technologies? Can statistical models faithfully express human language? Or are tokenizers "tokenizing" people—creating a Frankenstein monster of lived experiences?
Can we create equitable ML technologies? Can statistical models faithfully express human language? Or are tokenizers "tokenizing" people—creating a Frankenstein monster of lived experiences?
📄A Capabilities Approach to Studying Bias and Harm in Language Technologies
@hellinanigatu.bsky.social introduced us to the Capabilities Approach and how it can help us better understand the social impact of language technologies—with case studies of failing tech in the Majority World.
@hellinanigatu.bsky.social introduced us to the Capabilities Approach and how it can help us better understand the social impact of language technologies—with case studies of failing tech in the Majority World.
November 15, 2024 at 4:36 PM
📄A Capabilities Approach to Studying Bias and Harm in Language Technologies
@hellinanigatu.bsky.social introduced us to the Capabilities Approach and how it can help us better understand the social impact of language technologies—with case studies of failing tech in the Majority World.
@hellinanigatu.bsky.social introduced us to the Capabilities Approach and how it can help us better understand the social impact of language technologies—with case studies of failing tech in the Majority World.
📄Angry Men, Sad Women: Large Language Models Reflect Gendered Stereotypes in Emotion Attribution
Flor Plaza discussed the importance of studying gendered emotional stereotypes in LLMs, and how collaborating with philosophers benefits work on bias evaluation greatly.
Flor Plaza discussed the importance of studying gendered emotional stereotypes in LLMs, and how collaborating with philosophers benefits work on bias evaluation greatly.

November 15, 2024 at 4:36 PM
📄Angry Men, Sad Women: Large Language Models Reflect Gendered Stereotypes in Emotion Attribution
Flor Plaza discussed the importance of studying gendered emotional stereotypes in LLMs, and how collaborating with philosophers benefits work on bias evaluation greatly.
Flor Plaza discussed the importance of studying gendered emotional stereotypes in LLMs, and how collaborating with philosophers benefits work on bias evaluation greatly.
🔑Keynote by John Lalor: Should Fairness be a Metric or a Model?
While fairness is often viewed as a metric, using integrated models instead can help with explaining upstream bias, predicting downstream fairness, and capturing intersectional bias.
While fairness is often viewed as a metric, using integrated models instead can help with explaining upstream bias, predicting downstream fairness, and capturing intersectional bias.

November 15, 2024 at 4:36 PM
🔑Keynote by John Lalor: Should Fairness be a Metric or a Model?
While fairness is often viewed as a metric, using integrated models instead can help with explaining upstream bias, predicting downstream fairness, and capturing intersectional bias.
While fairness is often viewed as a metric, using integrated models instead can help with explaining upstream bias, predicting downstream fairness, and capturing intersectional bias.
📄A Decade of Gender Bias in Machine Translation
Eva Vanmassenhove: how has research on gender bias in MT developed over the years? Important issues, like non-binary gender bias, now fortunately get more attention. Yet, fundamental problems (that initially seemed trivial) remain unsolved.
Eva Vanmassenhove: how has research on gender bias in MT developed over the years? Important issues, like non-binary gender bias, now fortunately get more attention. Yet, fundamental problems (that initially seemed trivial) remain unsolved.

November 15, 2024 at 4:36 PM
📄A Decade of Gender Bias in Machine Translation
Eva Vanmassenhove: how has research on gender bias in MT developed over the years? Important issues, like non-binary gender bias, now fortunately get more attention. Yet, fundamental problems (that initially seemed trivial) remain unsolved.
Eva Vanmassenhove: how has research on gender bias in MT developed over the years? Important issues, like non-binary gender bias, now fortunately get more attention. Yet, fundamental problems (that initially seemed trivial) remain unsolved.
📄MBBQ: A Dataset for Cross-Lingual Comparison of Stereotypes in Generative LLMs
Vera Neplenbroek presented a multilingual extension of the BBQ bias benchmark to study bias across English, Dutch, Spanish, and Turkish.
"Multilingual LLMs are not necessarily multicultural!"
Vera Neplenbroek presented a multilingual extension of the BBQ bias benchmark to study bias across English, Dutch, Spanish, and Turkish.
"Multilingual LLMs are not necessarily multicultural!"

November 15, 2024 at 4:36 PM
📄MBBQ: A Dataset for Cross-Lingual Comparison of Stereotypes in Generative LLMs
Vera Neplenbroek presented a multilingual extension of the BBQ bias benchmark to study bias across English, Dutch, Spanish, and Turkish.
"Multilingual LLMs are not necessarily multicultural!"
Vera Neplenbroek presented a multilingual extension of the BBQ bias benchmark to study bias across English, Dutch, Spanish, and Turkish.
"Multilingual LLMs are not necessarily multicultural!"
🔑Keynote by Dong Nguyen: When LLMs meet language variation: Taking stock and looking forward
Non-standard language is often seen as noisy/incorrect data, but this ignores the reality of language. Variation should play a larger role in LLM developments and sociolinguistics can help!
Non-standard language is often seen as noisy/incorrect data, but this ignores the reality of language. Variation should play a larger role in LLM developments and sociolinguistics can help!

November 15, 2024 at 4:36 PM
🔑Keynote by Dong Nguyen: When LLMs meet language variation: Taking stock and looking forward
Non-standard language is often seen as noisy/incorrect data, but this ignores the reality of language. Variation should play a larger role in LLM developments and sociolinguistics can help!
Non-standard language is often seen as noisy/incorrect data, but this ignores the reality of language. Variation should play a larger role in LLM developments and sociolinguistics can help!
Last week, we organized the workshop "New Perspectives on Bias and Discrimination in Language Technology" 🤖 @uvahumanities.bsky.social @amsterdamnlp.bsky.social
We're looking back at two inspiring days of talks, posters, and discussions—thanks to everyone who participated!
wai-amsterdam.github.io
We're looking back at two inspiring days of talks, posters, and discussions—thanks to everyone who participated!
wai-amsterdam.github.io

November 15, 2024 at 4:36 PM
Last week, we organized the workshop "New Perspectives on Bias and Discrimination in Language Technology" 🤖 @uvahumanities.bsky.social @amsterdamnlp.bsky.social
We're looking back at two inspiring days of talks, posters, and discussions—thanks to everyone who participated!
wai-amsterdam.github.io
We're looking back at two inspiring days of talks, posters, and discussions—thanks to everyone who participated!
wai-amsterdam.github.io
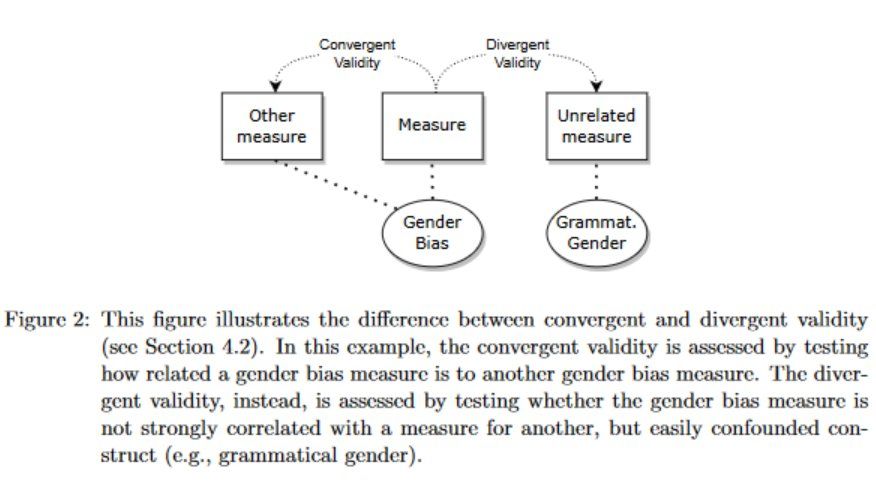
However, we believe that its flip side—divergent validity—deserves attention as well! Instead, we ask whether the bias measure is not too similar to another (easily confounded) measure or construct. We do not want to accidentally also measure something else!
January 24, 2024 at 9:39 AM
However, we believe that its flip side—divergent validity—deserves attention as well! Instead, we ask whether the bias measure is not too similar to another (easily confounded) measure or construct. We do not want to accidentally also measure something else!
Construct validity: How sure are we that we measure what we actually want to measure (the construct)? Critical work by e.g., Gonen & Goldberg, Blodgett et al., Orgad & Belinkov shows many flaws that could hurt the validity. How do we design bias measures that actually measure what we want?

January 24, 2024 at 9:36 AM
Construct validity: How sure are we that we measure what we actually want to measure (the construct)? Critical work by e.g., Gonen & Goldberg, Blodgett et al., Orgad & Belinkov shows many flaws that could hurt the validity. How do we design bias measures that actually measure what we want?
Reliability: How much precision can we get when applying the bias measure? How resilient is it to random measurement error? Naturally, we prefer measurement tools with a higher reliability! We discuss four forms of reliability we think can be applied easily to the NLP context.

January 24, 2024 at 9:26 AM
Reliability: How much precision can we get when applying the bias measure? How resilient is it to random measurement error? Naturally, we prefer measurement tools with a higher reliability! We discuss four forms of reliability we think can be applied easily to the NLP context.
Borrowing from psychometrics (a field specialized in the measurement of concepts that are not directly observable), we argue that it is useful to decouple the "construct" (what we want to know about but cannot observe directly) from its "operationalization" (the imperfect proxy).

January 24, 2024 at 9:25 AM
Borrowing from psychometrics (a field specialized in the measurement of concepts that are not directly observable), we argue that it is useful to decouple the "construct" (what we want to know about but cannot observe directly) from its "operationalization" (the imperfect proxy).
But when considering WinoBias a different picture emerges! While most interventions work somewhat, full model finetuning is most promising! Can we trust bias datasets (validity)? Differences in forms of gender bias? Which confounding factors (eg task performance) to control for?

December 11, 2023 at 4:30 PM
But when considering WinoBias a different picture emerges! While most interventions work somewhat, full model finetuning is most promising! Can we trust bias datasets (validity)? Differences in forms of gender bias? Which confounding factors (eg task performance) to control for?
Now for the effect on 3 bias benchmarks. The Professions dataset (from 1️⃣) and CrowS-Pairs show that the narrow interventions are consistently improving the bias. The results for ACDC (all circuit components) and full model finetuning are more noisy, or not even effective at all!


December 11, 2023 at 4:29 PM
Now for the effect on 3 bias benchmarks. The Professions dataset (from 1️⃣) and CrowS-Pairs show that the narrow interventions are consistently improving the bias. The results for ACDC (all circuit components) and full model finetuning are more noisy, or not even effective at all!
Unsurprisingly, perplexity increases more where a larger set of components is updated.

December 11, 2023 at 4:29 PM
Unsurprisingly, perplexity increases more where a larger set of components is updated.
We actually find a substantial overlap in the top 10 attn heads (out of 144) for CMA, ACDC, and DiffMask+. Most are found in the last 4 layers. (We used Professions dataset by Vig et al., but noticed that these methods can be sensitive to the dataset choice; Why?—that is future work!)

December 11, 2023 at 4:27 PM
We actually find a substantial overlap in the top 10 attn heads (out of 144) for CMA, ACDC, and DiffMask+. Most are found in the last 4 layers. (We used Professions dataset by Vig et al., but noticed that these methods can be sensitive to the dataset choice; Why?—that is future work!)
For 1️⃣, we compare three approaches: causal mediation analysis, ACDC, and DiffMask+, which is an adaptation of earlier work by Nicola De Cao that learns a sparse ✨set✨ of task-important components (unlike CMA) while being less computationally prohibitive than ACDC.

December 11, 2023 at 4:26 PM
For 1️⃣, we compare three approaches: causal mediation analysis, ACDC, and DiffMask+, which is an adaptation of earlier work by Nicola De Cao that learns a sparse ✨set✨ of task-important components (unlike CMA) while being less computationally prohibitive than ACDC.
In this work, we combine two ideas: 1️⃣ use causal discovery methods to explore which components (e.g. attention heads) are responsible for gender bias; 2️⃣ use this information to do a targeted intervention through selective finetuning.

December 11, 2023 at 4:24 PM
In this work, we combine two ideas: 1️⃣ use causal discovery methods to explore which components (e.g. attention heads) are responsible for gender bias; 2️⃣ use this information to do a targeted intervention through selective finetuning.