




S. Ota
@ota.bsky.social
Interests: Reinforcement Learning, Natural Language Processing and Artificial General Intelligence.
arXiv papers bot: @paper.bsky.social
arXiv papers bot: @paper.bsky.social
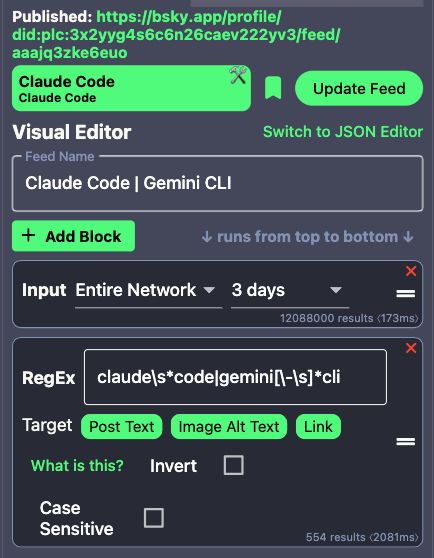
June 25, 2025 at 2:25 PM
RegEx patterns for Custom Keyboard feed.
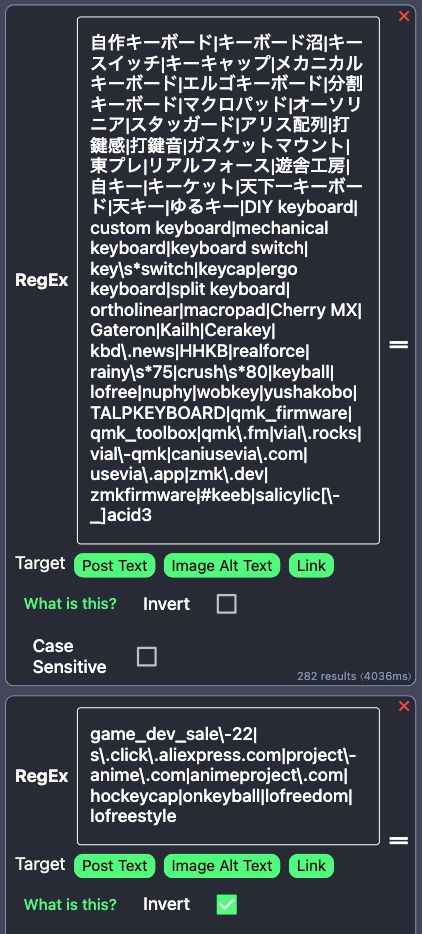
June 23, 2025 at 10:51 AM
RegEx patterns for Custom Keyboard feed.
Karabiner-Elements でマルチレイヤのキーマップを作った。karabiner.ts というライブラリを使ったらレイヤーが簡単に実装できた!
layer('japanese_eisuu', '英数 + ijkl').manipulators([
map('i').to('↑'),
map('j').to('←'),
map('k').to('↓'),
map('l').to('→'),
]),
それと久しぶりに Deno を使ってみたが、こういう簡単なプログラムならかなり楽。
github.com/susumuota/ka...
layer('japanese_eisuu', '英数 + ijkl').manipulators([
map('i').to('↑'),
map('j').to('←'),
map('k').to('↓'),
map('l').to('→'),
]),
それと久しぶりに Deno を使ってみたが、こういう簡単なプログラムならかなり楽。
github.com/susumuota/ka...
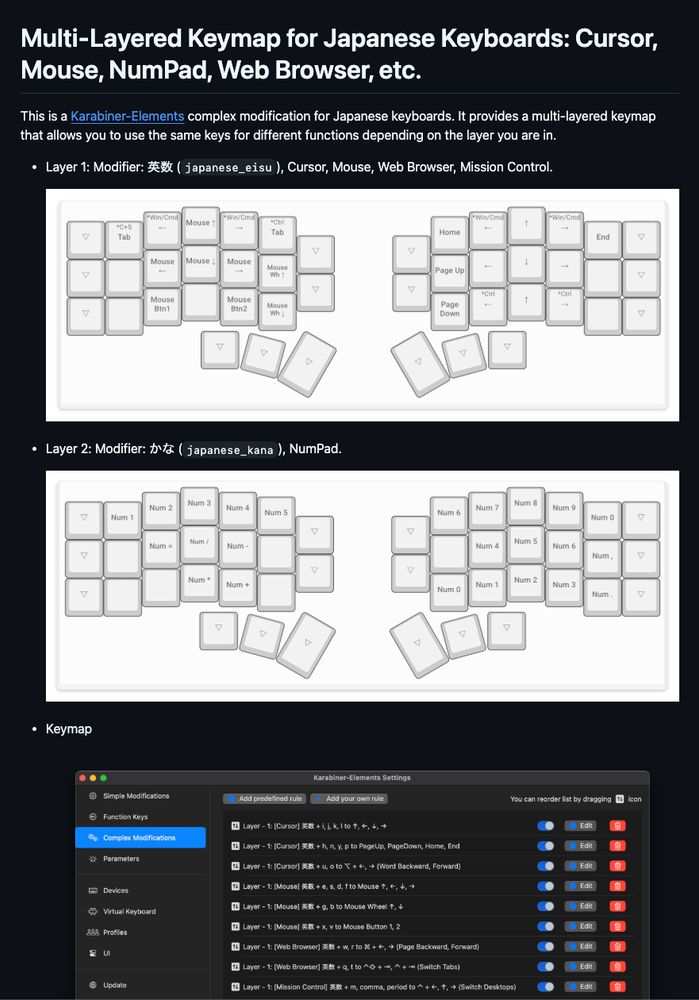
April 12, 2025 at 2:36 PM
Karabiner-Elements でマルチレイヤのキーマップを作った。karabiner.ts というライブラリを使ったらレイヤーが簡単に実装できた!
layer('japanese_eisuu', '英数 + ijkl').manipulators([
map('i').to('↑'),
map('j').to('←'),
map('k').to('↓'),
map('l').to('→'),
]),
それと久しぶりに Deno を使ってみたが、こういう簡単なプログラムならかなり楽。
github.com/susumuota/ka...
layer('japanese_eisuu', '英数 + ijkl').manipulators([
map('i').to('↑'),
map('j').to('←'),
map('k').to('↓'),
map('l').to('→'),
]),
それと久しぶりに Deno を使ってみたが、こういう簡単なプログラムならかなり楽。
github.com/susumuota/ka...
April 7, 2025 at 8:55 AM
I just realised that image alt text can be 2000 characters long.
I have fixed @paper.bsky.social to allow 2000 chars.
I have fixed @paper.bsky.social to allow 2000 chars.
April 5, 2025 at 3:58 AM
I just realised that image alt text can be 2000 characters long.
I have fixed @paper.bsky.social to allow 2000 chars.
I have fixed @paper.bsky.social to allow 2000 chars.
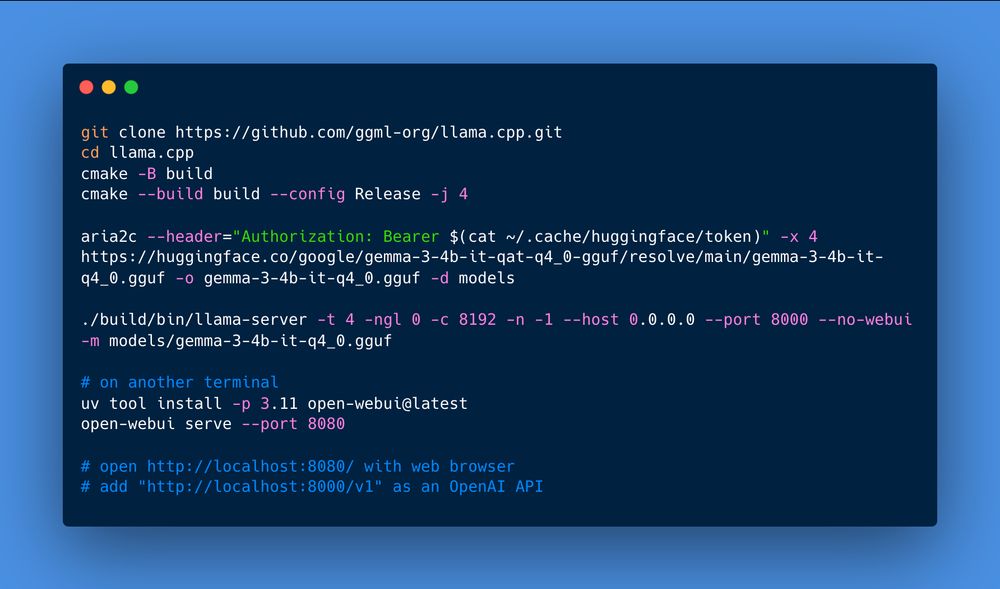
gemma-3-4b-it-qat-q4_0-gguf runs on Raspberry Pi 5 8GB at 2.8 tokens / sec.
huggingface.co/google/gemma...
huggingface.co/google/gemma...
April 4, 2025 at 2:57 PM
gemma-3-4b-it-qat-q4_0-gguf runs on Raspberry Pi 5 8GB at 2.8 tokens / sec.
huggingface.co/google/gemma...
huggingface.co/google/gemma...
It includes 3 color variants.
default: selenized-white
invert: selenized-dark
light: selenized-light
default: selenized-white
invert: selenized-dark
light: selenized-light

March 20, 2025 at 11:25 AM
It includes 3 color variants.
default: selenized-white
invert: selenized-dark
light: selenized-light
default: selenized-white
invert: selenized-dark
light: selenized-light
Setup gemma-3-27b-it with vllm. At the moment you need to install both vllm and transformers from source.

March 16, 2025 at 3:20 AM
Setup gemma-3-27b-it with vllm. At the moment you need to install both vllm and transformers from source.

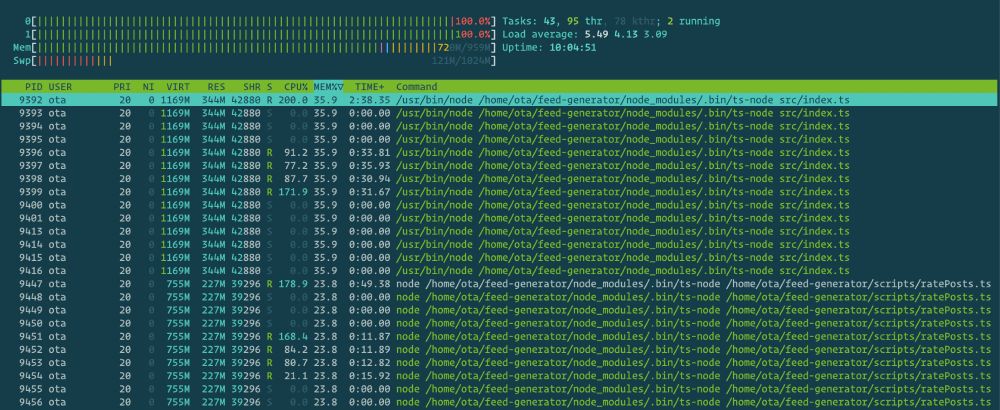
I have noticed that my feed generator often misses some posts that should have been caught by regex... Is this because there are too many posts to handle?
March 1, 2025 at 5:12 AM
I have noticed that my feed generator often misses some posts that should have been caught by regex... Is this because there are too many posts to handle?
Claude 3.7 Sonnet Thinking is available on GitHub Copilot! It seems that the <think> part is not accessible from Copilot.


February 26, 2025 at 1:44 PM
Claude 3.7 Sonnet Thinking is available on GitHub Copilot! It seems that the <think> part is not accessible from Copilot.

February 17, 2025 at 11:50 AM
This prompt works very well with R1.
git diff --cached | sgpt "Generate a commit message following the Conventional Commits specification. e.g. feat, fix, chore, docs, etc."
git diff --cached | sgpt "Generate a commit message following the Conventional Commits specification. e.g. feat, fix, chore, docs, etc."

February 17, 2025 at 4:16 AM
This prompt works very well with R1.
git diff --cached | sgpt "Generate a commit message following the Conventional Commits specification. e.g. feat, fix, chore, docs, etc."
git diff --cached | sgpt "Generate a commit message following the Conventional Commits specification. e.g. feat, fix, chore, docs, etc."
Sometimes the feed-generator keeps 100% CPUs for a while on e2-micro (GCP's free tier).

February 9, 2025 at 9:48 AM
Sometimes the feed-generator keeps 100% CPUs for a while on e2-micro (GCP's free tier).
#BskyMeetup
looks like a bit surreal 😆
looks like a bit surreal 😆

April 13, 2024 at 5:41 AM
#BskyMeetup
looks like a bit surreal 😆
looks like a bit surreal 😆

"Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks ... Models are trained on a context length of 8192 tokens."
storage.googleapis.com/deepmind-med...
storage.googleapis.com/deepmind-med...

February 21, 2024 at 3:24 PM
"Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks ... Models are trained on a context length of 8192 tokens."
storage.googleapis.com/deepmind-med...
storage.googleapis.com/deepmind-med...
Fine-tuning (qlora) llama-2-7b with guanaco dataset (light blue lines). Similar to llama-7b (green lines).



July 22, 2023 at 8:10 AM
Fine-tuning (qlora) llama-2-7b with guanaco dataset (light blue lines). Similar to llama-7b (green lines).
New StabilityAI's models outperform Llama-2?
Model files not yet available.
Model files not yet available.

July 21, 2023 at 7:09 PM
New StabilityAI's models outperform Llama-2?
Model files not yet available.
Model files not yet available.
DeepL「一見オラオラ系の ChatGPT」!?
oracular == オラキュラ == オラオラ系
どんなロジックで翻訳してるのか謎。
元記事: https://www.nytimes.com/2023/07/18/magazine/wikipedia-ai-chatgpt.html
oracular == オラキュラ == オラオラ系
どんなロジックで翻訳してるのか謎。
元記事: https://www.nytimes.com/2023/07/18/magazine/wikipedia-ai-chatgpt.html

July 19, 2023 at 1:18 PM
DeepL「一見オラオラ系の ChatGPT」!?
oracular == オラキュラ == オラオラ系
どんなロジックで翻訳してるのか謎。
元記事: https://www.nytimes.com/2023/07/18/magazine/wikipedia-ai-chatgpt.html
oracular == オラキュラ == オラオラ系
どんなロジックで翻訳してるのか謎。
元記事: https://www.nytimes.com/2023/07/18/magazine/wikipedia-ai-chatgpt.html
Open LLM Leaderboard updated 13B models.
I have confirmed that Llama-2-13b-chat works well on my laptop PC (MacBook Pro 2020) with llama.cpp, although it looks heavily "censored". It's better to fine-tune llama-2-13b (without chat) with uncensored dataset.
I have confirmed that Llama-2-13b-chat works well on my laptop PC (MacBook Pro 2020) with llama.cpp, although it looks heavily "censored". It's better to fine-tune llama-2-13b (without chat) with uncensored dataset.

July 19, 2023 at 9:20 AM
Open LLM Leaderboard updated 13B models.
I have confirmed that Llama-2-13b-chat works well on my laptop PC (MacBook Pro 2020) with llama.cpp, although it looks heavily "censored". It's better to fine-tune llama-2-13b (without chat) with uncensored dataset.
I have confirmed that Llama-2-13b-chat works well on my laptop PC (MacBook Pro 2020) with llama.cpp, although it looks heavily "censored". It's better to fine-tune llama-2-13b (without chat) with uncensored dataset.
ziplm
"Useless but mildly interesting language model using compressors built-in to Python."
It calculate the probability of the next token with
len(compress(training_data + prompt + next_token))
If the length is short, it means the probability is high.
https://github.com/Futrell/ziplm
"Useless but mildly interesting language model using compressors built-in to Python."
It calculate the probability of the next token with
len(compress(training_data + prompt + next_token))
If the length is short, it means the probability is high.
https://github.com/Futrell/ziplm


July 15, 2023 at 9:39 AM
ziplm
"Useless but mildly interesting language model using compressors built-in to Python."
It calculate the probability of the next token with
len(compress(training_data + prompt + next_token))
If the length is short, it means the probability is high.
https://github.com/Futrell/ziplm
"Useless but mildly interesting language model using compressors built-in to Python."
It calculate the probability of the next token with
len(compress(training_data + prompt + next_token))
If the length is short, it means the probability is high.
https://github.com/Futrell/ziplm
Coding a prompt to make GPT rate the given tweet on a scale of 1 to 10. This will return the rating and explanation of the tweet in JSON format using `function calling`.



July 9, 2023 at 3:58 PM
Coding a prompt to make GPT rate the given tweet on a scale of 1 to 10. This will return the rating and explanation of the tweet in JSON format using `function calling`.
Airoboros seems to be dominant in this evaluation.
"llm-jeopardy: Automated prompting and scoring framework to evaluate LLMs using updated human knowledge prompts"
https://github.com/aigoopy/llm-jeopardy
"llm-jeopardy: Automated prompting and scoring framework to evaluate LLMs using updated human knowledge prompts"
https://github.com/aigoopy/llm-jeopardy

July 6, 2023 at 5:26 PM
Airoboros seems to be dominant in this evaluation.
"llm-jeopardy: Automated prompting and scoring framework to evaluate LLMs using updated human knowledge prompts"
https://github.com/aigoopy/llm-jeopardy
"llm-jeopardy: Automated prompting and scoring framework to evaluate LLMs using updated human knowledge prompts"
https://github.com/aigoopy/llm-jeopardy
I have tested QLoLA to reproduce guanaco-7b.
- NVIDIA L4 ($0.22/h)
- 14 hours
- total cost ~$3
Obviously eval/loss shows overfitting, but the MMLU score seems to improve...
Anyway, if it works well, there is no need to spend several days training with A100 machines costing a few hundred dollars.
- NVIDIA L4 ($0.22/h)
- 14 hours
- total cost ~$3
Obviously eval/loss shows overfitting, but the MMLU score seems to improve...
Anyway, if it works well, there is no need to spend several days training with A100 machines costing a few hundred dollars.



June 26, 2023 at 6:26 AM
I have tested QLoLA to reproduce guanaco-7b.
- NVIDIA L4 ($0.22/h)
- 14 hours
- total cost ~$3
Obviously eval/loss shows overfitting, but the MMLU score seems to improve...
Anyway, if it works well, there is no need to spend several days training with A100 machines costing a few hundred dollars.
- NVIDIA L4 ($0.22/h)
- 14 hours
- total cost ~$3
Obviously eval/loss shows overfitting, but the MMLU score seems to improve...
Anyway, if it works well, there is no need to spend several days training with A100 machines costing a few hundred dollars.