



Onno Eberhard
@onnoeberhard.com
PhD Student in Tübingen (MPI-IS & Uni Tü), interested in reinforcement learning. Freedom is a pure idea. https://onnoeberhard.com/
A cute little animation: a critically damped harmonic oscillator becomes unstable with integral control if the gain is too high. Here, at K_i = 2, a Hopf bifurcation occurs: two poles of the transfer function enter the right-hand s-plane and the closed-loop system becomes unstable.
September 9, 2025 at 2:34 PM
A cute little animation: a critically damped harmonic oscillator becomes unstable with integral control if the gain is too high. Here, at K_i = 2, a Hopf bifurcation occurs: two poles of the transfer function enter the right-hand s-plane and the closed-loop system becomes unstable.
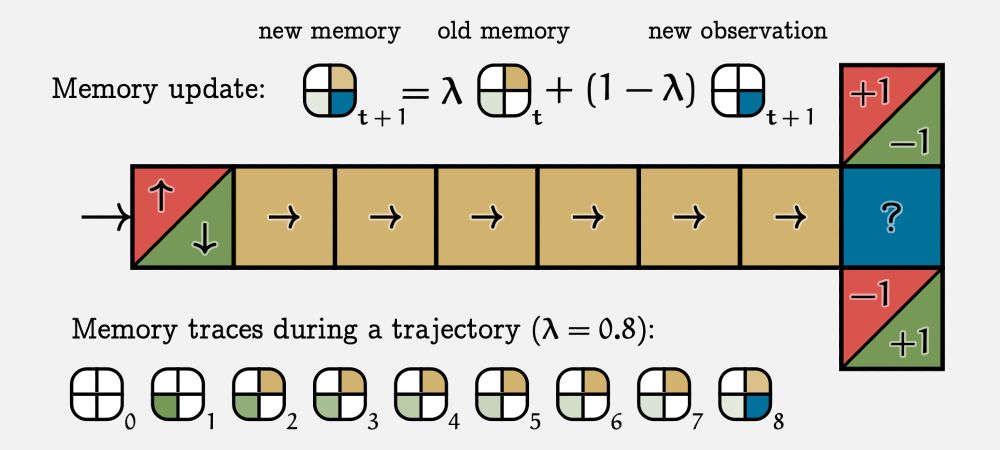
Memory traces are trivially simple to implement, and we ran some experiments that demonstrate that they are an effective drop-in replacement for sliding windows ("frame stacking") in deep reinforcement learning.

July 16, 2025 at 1:35 AM
Memory traces are trivially simple to implement, and we ran some experiments that demonstrate that they are an effective drop-in replacement for sliding windows ("frame stacking") in deep reinforcement learning.
However, if we allow larger values of 𝜆, then we do find environments where memory traces are considerably more powerful than sliding windows!

July 16, 2025 at 1:35 AM
However, if we allow larger values of 𝜆, then we do find environments where memory traces are considerably more powerful than sliding windows!
Our second result goes the other way: when 𝜆 < 1/2, then there is no environment where memory traces are more efficient than sliding windows. In other words, if 𝜆 < 1/2, then learning with sliding windows and memory traces is equivalent!

July 16, 2025 at 1:35 AM
Our second result goes the other way: when 𝜆 < 1/2, then there is no environment where memory traces are more efficient than sliding windows. In other words, if 𝜆 < 1/2, then learning with sliding windows and memory traces is equivalent!
Using this result, we can finally compare learning with sliding windows to learning with memory traces! Our first result shows that there is no environment where sliding windows are generally more efficient than memory traces (even when restricting to 𝜆 < 1/2).

July 16, 2025 at 1:35 AM
Using this result, we can finally compare learning with sliding windows to learning with memory traces! Our first result shows that there is no environment where sliding windows are generally more efficient than memory traces (even when restricting to 𝜆 < 1/2).
The "resolution" of a function class is given by its Lipschitz constant. We thus consider the function class ℱ = {𝑓 ∘ 𝑧 ∣ 𝑓 : 𝒵 → ℝ, 𝑓 is 𝐿-Lipschitz}. This allows us to bound the metric entropy. (The constant 𝑑_λ is the Minkowski dimension of 𝒵 if 𝜆 < 1/2.)

July 16, 2025 at 1:35 AM
The "resolution" of a function class is given by its Lipschitz constant. We thus consider the function class ℱ = {𝑓 ∘ 𝑧 ∣ 𝑓 : 𝒵 → ℝ, 𝑓 is 𝐿-Lipschitz}. This allows us to bound the metric entropy. (The constant 𝑑_λ is the Minkowski dimension of 𝒵 if 𝜆 < 1/2.)
Without forgetting, the learning is intractable: it is equivalent to keeping the complete history. However, to distinguish histories that differ only far in the past, we need to "zoom in" a lot, as shown here.
July 16, 2025 at 1:35 AM
Without forgetting, the learning is intractable: it is equivalent to keeping the complete history. However, to distinguish histories that differ only far in the past, we need to "zoom in" a lot, as shown here.
What about memory traces? Here, I am visualizing the space 𝒵 of all possible memory traces for the case where there are only 3 possible (one-hot) observations, 𝒴 = {a, b, c}. We can show that, if 𝜆 < 1/2, then memory traces preserve all information of the complete history! Nothing is forgotten!
July 16, 2025 at 1:35 AM
What about memory traces? Here, I am visualizing the space 𝒵 of all possible memory traces for the case where there are only 3 possible (one-hot) observations, 𝒴 = {a, b, c}. We can show that, if 𝜆 < 1/2, then memory traces preserve all information of the complete history! Nothing is forgotten!
We focus on the problem of policy evaluation with offline data where the environment ℰ is a hidden Markov model, and we assume that the observation space 𝒴 is one-hot. Thus, given a function class ℱ, our goal is to find the function 𝑓 ∈ ℱ that minimizes the return error.

July 16, 2025 at 1:35 AM
We focus on the problem of policy evaluation with offline data where the environment ℰ is a hidden Markov model, and we assume that the observation space 𝒴 is one-hot. Thus, given a function class ℱ, our goal is to find the function 𝑓 ∈ ℱ that minimizes the return error.
I am in Vancouver at ICML, and tomorrow I will present our newest paper "Partially Observable Reinforcement Learning with Memory Traces". We argue that eligibility traces are more effective than sliding windows as a memory mechanism for RL in POMDPs. 🧵
July 16, 2025 at 1:35 AM
I am in Vancouver at ICML, and tomorrow I will present our newest paper "Partially Observable Reinforcement Learning with Memory Traces". We argue that eligibility traces are more effective than sliding windows as a memory mechanism for RL in POMDPs. 🧵
Great talk by @claireve.bsky.social about our joint work on memory traces this morning. Come join me at poster 94 if you want to know more! #RLDM2025

June 13, 2025 at 2:23 PM
Great talk by @claireve.bsky.social about our joint work on memory traces this morning. Come join me at poster 94 if you want to know more! #RLDM2025
With this increased sample efficiency, the algorithm can even tackle high-dimensional, non-smooth, and stochastic MuJoCo environments, as shown here.
June 4, 2025 at 8:06 AM
With this increased sample efficiency, the algorithm can even tackle high-dimensional, non-smooth, and stochastic MuJoCo environments, as shown here.
In this algorithm, the Jacobians are estimated independently at every iteration. However, if the learning rate is not too large (and the dynamics are smooth), then we can be more sample efficient by bootstrapping the Jacobian estimates using recursive least squares.

June 4, 2025 at 8:06 AM
In this algorithm, the Jacobians are estimated independently at every iteration. However, if the learning rate is not too large (and the dynamics are smooth), then we can be more sample efficient by bootstrapping the Jacobian estimates using recursive least squares.
This strategy manages to learn highly effective open-loop controllers, like this one that swings up an inverted pendulum.
June 4, 2025 at 8:06 AM
This strategy manages to learn highly effective open-loop controllers, like this one that swings up an inverted pendulum.
How should we estimate the Jacobians? They determine how the next state changes if a state or action are perturbed. We simply perturb all actions randomly and fit a linear regression model to the transitions.

June 4, 2025 at 8:06 AM
How should we estimate the Jacobians? They determine how the next state changes if a state or action are perturbed. We simply perturb all actions randomly and fit a linear regression model to the transitions.
In RL, we don't know the system dynamics, so we cannot evaluate the Jacobians reqiured by Pontryagin's equations. We prove that it is possible to replace them with estimates and still keep convergence guarantees.

June 4, 2025 at 8:06 AM
In RL, we don't know the system dynamics, so we cannot evaluate the Jacobians reqiured by Pontryagin's equations. We prove that it is possible to replace them with estimates and still keep convergence guarantees.
How can we optimize an open-loop controller? The fundamental tool is *Pontryagin's principle* which tells us how to compute the gradient of the open-loop objective function.

June 4, 2025 at 8:06 AM
How can we optimize an open-loop controller? The fundamental tool is *Pontryagin's principle* which tells us how to compute the gradient of the open-loop objective function.
In open-loop control, the actions do not depend of the system's state: there is no feedback policy. Instead, a complete sequence of actions is fixed before the interaction begins. This makes it less powerful than closed loop methods, but optimization can be much easier!

June 4, 2025 at 8:06 AM
In open-loop control, the actions do not depend of the system's state: there is no feedback policy. Instead, a complete sequence of actions is fixed before the interaction begins. This makes it less powerful than closed loop methods, but optimization can be much easier!
I'm flying to Michigan today to present our new paper "A Pontryagin Perspective on Reinforcement Learning" at L4DC, where it has been nominated for the Best Paper Award! We ask the question: is it possible to learn an open-loop controller via RL? 🧵

June 4, 2025 at 8:06 AM
I'm flying to Michigan today to present our new paper "A Pontryagin Perspective on Reinforcement Learning" at L4DC, where it has been nominated for the Best Paper Award! We ask the question: is it possible to learn an open-loop controller via RL? 🧵