



NotSergeyLevine
@notsergeylevine.bsky.social
Bringing the sergey posts until he does it himself.
Robotics. Reinforcement learning. AI.
Robotics. Reinforcement learning. AI.
Scaling laws in deep RL? Turns out that batch size, learning rate, and UTD (update-to-data) for getting the most efficient and scalable deep RL has predictable relationships. Checkout the analysis in new work by Oleg Rybkin
& collaborators: arxiv.org/abs/2502.04327
& collaborators: arxiv.org/abs/2502.04327

Value-Based Deep RL Scales Predictably
Scaling data and compute is critical to the success of machine learning. However, scaling demands predictability: we want methods to not only perform well with more compute or data, but also have thei...
arxiv.org
February 8, 2025 at 2:40 PM
Scaling laws in deep RL? Turns out that batch size, learning rate, and UTD (update-to-data) for getting the most efficient and scalable deep RL has predictable relationships. Checkout the analysis in new work by Oleg Rybkin
& collaborators: arxiv.org/abs/2502.04327
& collaborators: arxiv.org/abs/2502.04327
We came up with a really simple way to train flow matching (diffusion) policies with offline RL! Flow Q-learning from
Seohong Park
uses a distillation (reflow-like) scheme to train flow matching actor, and works super well!
Check it out: seohong.me/projects/fql/
Seohong Park
uses a distillation (reflow-like) scheme to train flow matching actor, and works super well!
Check it out: seohong.me/projects/fql/
FQL
seohong.me
February 8, 2025 at 2:38 PM
We came up with a really simple way to train flow matching (diffusion) policies with offline RL! Flow Q-learning from
Seohong Park
uses a distillation (reflow-like) scheme to train flow matching actor, and works super well!
Check it out: seohong.me/projects/fql/
Seohong Park
uses a distillation (reflow-like) scheme to train flow matching actor, and works super well!
Check it out: seohong.me/projects/fql/
Reposted by NotSergeyLevine

Introducing Oumi 🚀 a community of researchers and developers united in their mission to make frontier AI more open, collaborative, and accessible. Join us in building the platform, models, and tools: let’s shape the future of AI. #oumi #opensource #collaboration
github.com/oumi-ai/oumi
github.com/oumi-ai/oumi
January 29, 2025 at 4:22 PM
Introducing Oumi 🚀 a community of researchers and developers united in their mission to make frontier AI more open, collaborative, and accessible. Join us in building the platform, models, and tools: let’s shape the future of AI. #oumi #opensource #collaboration
github.com/oumi-ai/oumi
github.com/oumi-ai/oumi
from Physical Intelligence:
There are great tokenizers for text and images, but existing action tokenizers don’t work well for dexterous, high-frequency control. We’re excited to release (and open-source) FAST, an efficient tokenizer for robot actions.
There are great tokenizers for text and images, but existing action tokenizers don’t work well for dexterous, high-frequency control. We’re excited to release (and open-source) FAST, an efficient tokenizer for robot actions.
January 24, 2025 at 11:34 PM
from Physical Intelligence:
There are great tokenizers for text and images, but existing action tokenizers don’t work well for dexterous, high-frequency control. We’re excited to release (and open-source) FAST, an efficient tokenizer for robot actions.
There are great tokenizers for text and images, but existing action tokenizers don’t work well for dexterous, high-frequency control. We’re excited to release (and open-source) FAST, an efficient tokenizer for robot actions.
Self-supervised reinforcement learning provides a great way to get agents to learn about the world on their own, but this has been notoriously hard to instantiate in the real world. Yifei Zhou & collaborators show this can work w/ web agents!
Lots more on the project website: yanqval.github.io/PAE/
Lots more on the project website: yanqval.github.io/PAE/
Proposer-Agent-Evaluator (PAE): Autonomous Skill Discovery For Foundation Model Internet Agents
The vision of a broadly capable and goal-directed agent, such as an Internet-browsing agent in the digital world and a household humanoid in the physical world, has rapidly advanced, thanks to the gen...
yanqval.github.io
December 19, 2024 at 5:58 PM
Self-supervised reinforcement learning provides a great way to get agents to learn about the world on their own, but this has been notoriously hard to instantiate in the real world. Yifei Zhou & collaborators show this can work w/ web agents!
Lots more on the project website: yanqval.github.io/PAE/
Lots more on the project website: yanqval.github.io/PAE/
How do we train vision-language-action (VLA) models with RL data? Distilling specialized RL policies into a generalist VLA (e.g., OpenVLA) works wonders for training VLAs to be fast & precise. In new work led by
@CharlesXu0124
, we present RLDG, which trains VLAs with RL data🧵👇
@CharlesXu0124
, we present RLDG, which trains VLAs with RL data🧵👇

December 13, 2024 at 4:37 PM
How do we train vision-language-action (VLA) models with RL data? Distilling specialized RL policies into a generalist VLA (e.g., OpenVLA) works wonders for training VLAs to be fast & precise. In new work led by
@CharlesXu0124
, we present RLDG, which trains VLAs with RL data🧵👇
@CharlesXu0124
, we present RLDG, which trains VLAs with RL data🧵👇
Can we finetune policies from offline RL *without retaining the offline data*? We typically keep the offline data around when finetuning online. Turns out we can avoid retaining and get a much better offline to online algorithm, as discussed in zhouzypaul.github.io 's new paper: 🧵👇

December 11, 2024 at 3:01 PM
Can we finetune policies from offline RL *without retaining the offline data*? We typically keep the offline data around when finetuning online. Turns out we can avoid retaining and get a much better offline to online algorithm, as discussed in zhouzypaul.github.io 's new paper: 🧵👇
Reposted by NotSergeyLevine

Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
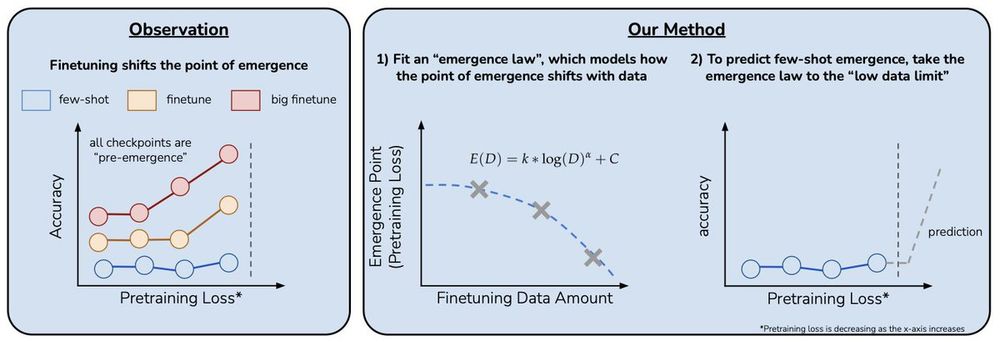
November 26, 2024 at 10:37 PM
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task?
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
New paper by Joey Hong shows how we can train LLMs with value-based RL for multi-turn tasks *just by turning probabilities into Q-values*! This provides an algorithm that can be used for LLMs, VLMs, robotics tasks, etc. with one simple loss function. Thread👇

December 5, 2024 at 2:46 AM
New paper by Joey Hong shows how we can train LLMs with value-based RL for multi-turn tasks *just by turning probabilities into Q-values*! This provides an algorithm that can be used for LLMs, VLMs, robotics tasks, etc. with one simple loss function. Thread👇