



Norman Mu
@normanmu.com
AI Safety @ xAI | AI robustness, PhD @ UC Berkeley | normanmu.com
Standard training techniques like good data curation, SFT -> DPO, work reasonably well, and the pass/fail nature of guardrail adherence enables the use of tricks like classifier-free guidance/contrastive decoding to further improve performance

February 19, 2025 at 6:06 AM
Standard training techniques like good data curation, SFT -> DPO, work reasonably well, and the pass/fail nature of guardrail adherence enables the use of tricks like classifier-free guidance/contrastive decoding to further improve performance
RealGuardrails is our new dataset to 1) evaluate system prompt robustness on realistic prompts scraped from the ChatGPT store, and 2) evaluate methods for improving open weight models like Llama 3

February 19, 2025 at 6:06 AM
RealGuardrails is our new dataset to 1) evaluate system prompt robustness on realistic prompts scraped from the ChatGPT store, and 2) evaluate methods for improving open weight models like Llama 3
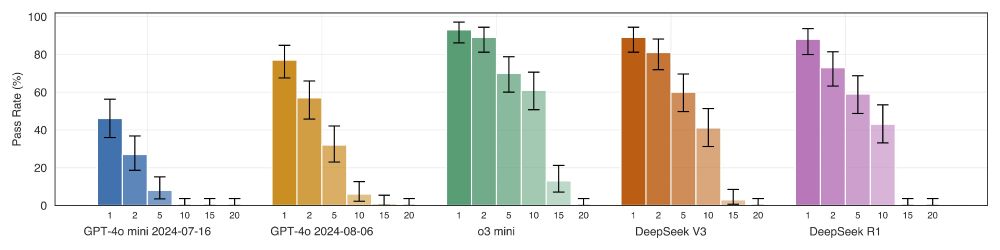
System prompts are a critical control plane for LLMs/AI agents, but models vary widely in their robustness. We found a "complexity wall" at ~10 guardrails where prompt adherence declines rapidly even on totally benign inputs
February 19, 2025 at 6:06 AM
System prompts are a critical control plane for LLMs/AI agents, but models vary widely in their robustness. We found a "complexity wall" at ~10 guardrails where prompt adherence declines rapidly even on totally benign inputs
Going off FLOP/s and power, looks like these are very roughly 3/4 of an H100?

December 3, 2024 at 8:58 PM
Going off FLOP/s and power, looks like these are very roughly 3/4 of an H100?
top loss curves do look sketchy but idk how bad this is for an RL task. bottom curves don't obviously asymptote but they also shouldn't with learning rate decay (which the open source release seems to use? github.com/google-resea...)

December 1, 2024 at 9:12 AM
top loss curves do look sketchy but idk how bad this is for an RL task. bottom curves don't obviously asymptote but they also shouldn't with learning rate decay (which the open source release seems to use? github.com/google-resea...)
my takeaway from Vighnesh's writeup: google's main argument about under-training/lack of pre-training isn't super convincing. convergence of train loss is not always desirable. early stopping can help, and their own paper shows mixed results on importance of pre-training

December 1, 2024 at 9:03 AM
my takeaway from Vighnesh's writeup: google's main argument about under-training/lack of pre-training isn't super convincing. convergence of train loss is not always desirable. early stopping can help, and their own paper shows mixed results on importance of pre-training