



Nora Harhen
@noraharhen.bsky.social
Postdoc at NYU studying learning, memory, and decision making across development
https://noraharhen.github.io/
https://noraharhen.github.io/
I’m really jazzed to continue this line of work so feedback is much appreciated! Lastly, this work would not have been possible without my advisor @aaronbornstein.bsky.social and the Conte Center at UCI, whose empirical work greatly informed our approach towards modeling adversity. (10/10)
October 23, 2023 at 7:04 PM
I’m really jazzed to continue this line of work so feedback is much appreciated! Lastly, this work would not have been possible without my advisor @aaronbornstein.bsky.social and the Conte Center at UCI, whose empirical work greatly informed our approach towards modeling adversity. (10/10)
In this paper, we show that these maladaptive behaviors can emerge from adaptive developmental processes. There’s other analyses that I haven’t mentioned in this thread — including how different dimensions of adversity interact in non-additive ways. Check out the paper to read about those! (9/10)
October 23, 2023 at 7:03 PM
In this paper, we show that these maladaptive behaviors can emerge from adaptive developmental processes. There’s other analyses that I haven’t mentioned in this thread — including how different dimensions of adversity interact in non-additive ways. Check out the paper to read about those! (9/10)
It also produces a negativity bias, another feature of anhedonia. To simulate adulthood, we “froze” agents’ temporal representations and then placed them in an environment with predictably timed rewards. ELU agents’ showed larger prediction errors when reward was omitted than when received. (8/10)

October 23, 2023 at 7:03 PM
It also produces a negativity bias, another feature of anhedonia. To simulate adulthood, we “froze” agents’ temporal representations and then placed them in an environment with predictably timed rewards. ELU agents’ showed larger prediction errors when reward was omitted than when received. (8/10)
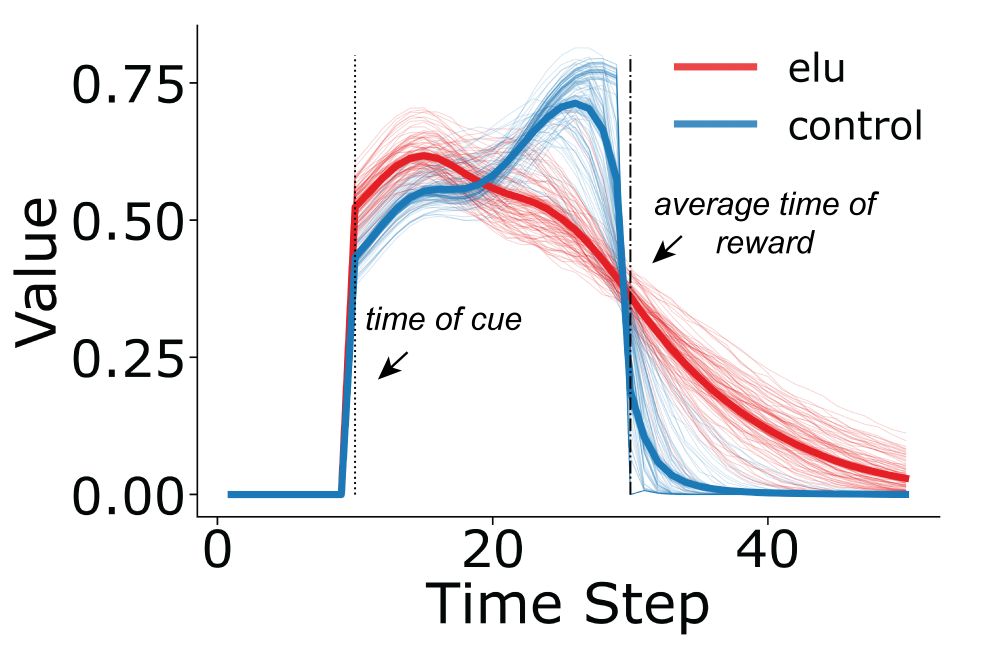
It diminishes reward expectations at the time points just before reward is most likely to occur. Let’s say these Pavlovian values were transferred to instrumental actions — this would produce reduced motivation to pursue rewards, one characterizing feature of anhedonia. (7/10)
October 23, 2023 at 7:03 PM
It diminishes reward expectations at the time points just before reward is most likely to occur. Let’s say these Pavlovian values were transferred to instrumental actions — this would produce reduced motivation to pursue rewards, one characterizing feature of anhedonia. (7/10)
Agents developed temporal representations that mimicked the statistics of their environment. Early Life Unpredictability agents (ELU) ended up relying on less precise representations, which temporally “smeared” their reward expectations. This temporal smearing has important consequences. (6/10)
October 23, 2023 at 7:02 PM
Agents developed temporal representations that mimicked the statistics of their environment. Early Life Unpredictability agents (ELU) ended up relying on less precise representations, which temporally “smeared” their reward expectations. This temporal smearing has important consequences. (6/10)
We had two groups of agents who experienced different degrees of unpredictability in reward timing. By manipulating unpredictability in the *timing* rather than *presence* of reward, we could isolate the impact of unpredictability from environment richness. (5/10)

October 23, 2023 at 6:58 PM
We had two groups of agents who experienced different degrees of unpredictability in reward timing. By manipulating unpredictability in the *timing* rather than *presence* of reward, we could isolate the impact of unpredictability from environment richness. (5/10)
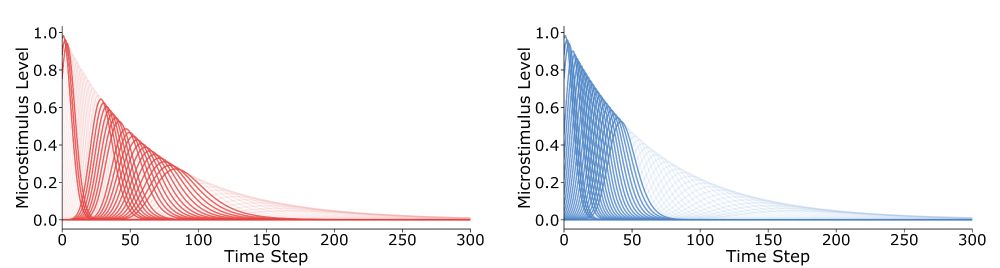
Under this variant of the TD model, time intervals are represented with a weighted set of temporal receptive fields, microstimuli, that vary in their precision or “spread.” The weights are adjusted with experience to make better predictions of if and when reward will occur following the cue. (4/10)

October 23, 2023 at 6:58 PM
Under this variant of the TD model, time intervals are represented with a weighted set of temporal receptive fields, microstimuli, that vary in their precision or “spread.” The weights are adjusted with experience to make better predictions of if and when reward will occur following the cue. (4/10)
As a first approach to this question, we simulated a temporal difference (TD) learning model undergoing Pavlovian conditioning. Importantly, the model had a non-standard representation of time, using microstimuli. (3/10)
October 23, 2023 at 6:57 PM
As a first approach to this question, we simulated a temporal difference (TD) learning model undergoing Pavlovian conditioning. Importantly, the model had a non-standard representation of time, using microstimuli. (3/10)
Lots of work has shown that reinforcement learning computations differ in adults with mood and anxiety disorders. We asked: could these “computational phenotypes” be a reflection of individuals’ developmental environments? (2/10)
October 23, 2023 at 6:57 PM
Lots of work has shown that reinforcement learning computations differ in adults with mood and anxiety disorders. We asked: could these “computational phenotypes” be a reflection of individuals’ developmental environments? (2/10)