




Ramon
@noctrog.bsky.social
PhD ML student in Switzerland
Prev intern at NVIDIA, Sony
Prev intern at NVIDIA, Sony
Last but not least, this is the performance of different levels of LP with varying sequence lengths and batch_size=1. All our experiments were done on 2x A100 SXM4 80Gb
(9/N)
(9/N)

February 14, 2025 at 4:17 PM
Last but not least, this is the performance of different levels of LP with varying sequence lengths and batch_size=1. All our experiments were done on 2x A100 SXM4 80Gb
(9/N)
(9/N)
Additionally, we show that some of the performance can be recovered through some very light fine-tuning of the parallel layers!
(8/N)
(8/N)

February 14, 2025 at 4:17 PM
Additionally, we show that some of the performance can be recovered through some very light fine-tuning of the parallel layers!
(8/N)
(8/N)
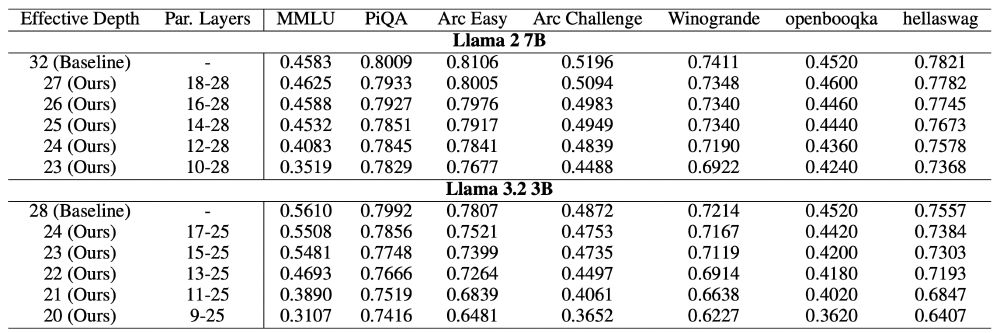
... and evaluate the best models on well-known benchmarks. We find that Llama 2 7B can have its effective depth reduced from 32->25 and Llama 3.2 3B from 28->23 without major accuracy losses.
(6/N)
(6/N)
February 14, 2025 at 4:17 PM
... and evaluate the best models on well-known benchmarks. We find that Llama 2 7B can have its effective depth reduced from 32->25 and Llama 3.2 3B from 28->23 without major accuracy losses.
(6/N)
(6/N)
We ablate the perplexity of Llama 2 7B and 3.2 3B on a subset of RedPajama wrt. the position and length (Δ) of LP...
(5/N)
(5/N)

February 14, 2025 at 4:17 PM
We ablate the perplexity of Llama 2 7B and 3.2 3B on a subset of RedPajama wrt. the position and length (Δ) of LP...
(5/N)
(5/N)
Enter Tensor Parallelism (TP). By combining TP and LP, we can shard the original model across different devices, and the effective depth on each shard will be decreased thanks to LP.
(4/N)
(4/N)

February 14, 2025 at 4:17 PM
Enter Tensor Parallelism (TP). By combining TP and LP, we can shard the original model across different devices, and the effective depth on each shard will be decreased thanks to LP.
(4/N)
(4/N)
We introduce Layer Parallelism (LP), a method that modifies the sequential computational graph of 2 consecutive layers to run them in parallel as shown in the picture. But naively running the new computational graph on a single GPU will not result in any speed-up.
(3/N)
(3/N)

February 14, 2025 at 4:17 PM
We introduce Layer Parallelism (LP), a method that modifies the sequential computational graph of 2 consecutive layers to run them in parallel as shown in the picture. But naively running the new computational graph on a single GPU will not result in any speed-up.
(3/N)
(3/N)
We try to modify the computational graph of a trained Llama 2 7B using different transformations, and find that running pairs of layers in parallel does not result in a catastrophic perplexity increase, especially on later layers.
(2/N)
(2/N)

February 14, 2025 at 4:17 PM
We try to modify the computational graph of a trained Llama 2 7B using different transformations, and find that running pairs of layers in parallel does not result in a catastrophic perplexity increase, especially on later layers.
(2/N)
(2/N)
What is the true depth of an LLM?
Together with @danielepal.bsky.social , @matpagliardini.bsky.social, M. Jaggi and @francois.fleuret.org we show that LLMs have a smaller effective depth that can be exploited to increase inference speeds on multi-GPU settings!
arxiv.org/abs/2502.02790
(1/N)
Together with @danielepal.bsky.social , @matpagliardini.bsky.social, M. Jaggi and @francois.fleuret.org we show that LLMs have a smaller effective depth that can be exploited to increase inference speeds on multi-GPU settings!
arxiv.org/abs/2502.02790
(1/N)

February 14, 2025 at 4:17 PM
What is the true depth of an LLM?
Together with @danielepal.bsky.social , @matpagliardini.bsky.social, M. Jaggi and @francois.fleuret.org we show that LLMs have a smaller effective depth that can be exploited to increase inference speeds on multi-GPU settings!
arxiv.org/abs/2502.02790
(1/N)
Together with @danielepal.bsky.social , @matpagliardini.bsky.social, M. Jaggi and @francois.fleuret.org we show that LLMs have a smaller effective depth that can be exploited to increase inference speeds on multi-GPU settings!
arxiv.org/abs/2502.02790
(1/N)