



Nikhil George
@nikilgeorge.bsky.social
ABD - CMU. Technology and Work
Reposted by Nikhil George

Six months ago someone put a for-loop around GPT-4o and got 50% on the ARC-AGI test set and 72% on a held-out training set redwoodresearch.substack.com/p/getting-50... Just sample 8000 times with beam search.
o3 is probably a more principled search technique...
o3 is probably a more principled search technique...
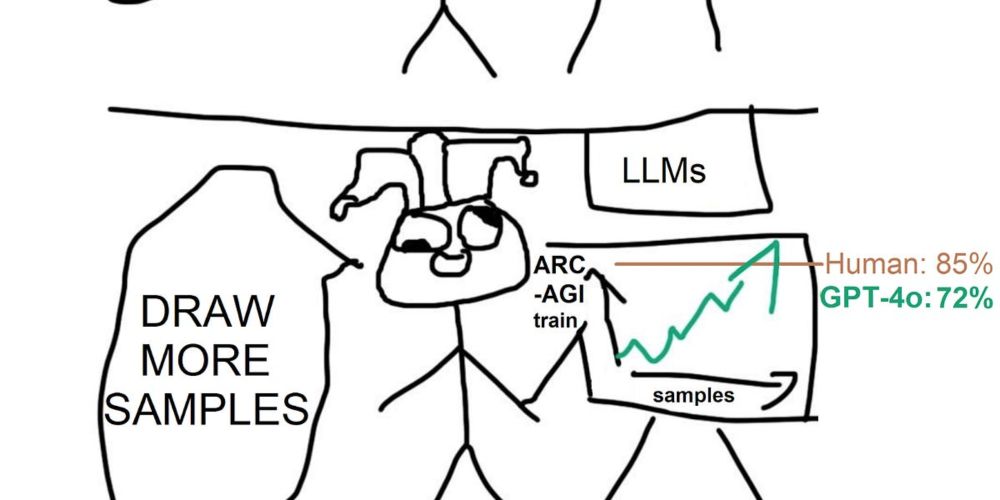
Getting 50% (SoTA) on ARC-AGI with GPT-4o
You can just draw more samples
redwoodresearch.substack.com
December 21, 2024 at 6:16 PM
Six months ago someone put a for-loop around GPT-4o and got 50% on the ARC-AGI test set and 72% on a held-out training set redwoodresearch.substack.com/p/getting-50... Just sample 8000 times with beam search.
o3 is probably a more principled search technique...
o3 is probably a more principled search technique...
o1 preview's reported advantage in "diagnostic subtasks" is v. high that clinical decision making supported by models is now a problem worth serious attention. next step would be to document if the diagnostic paths are faster? less expensive etc. -- arxiv.org/pdf/2412.10849

December 17, 2024 at 7:37 PM
o1 preview's reported advantage in "diagnostic subtasks" is v. high that clinical decision making supported by models is now a problem worth serious attention. next step would be to document if the diagnostic paths are faster? less expensive etc. -- arxiv.org/pdf/2412.10849
Reposted by Nikhil George

Serial acquisitions of anesthesia practices led to price increases of 30 percent with no quality improvements, from Aslihan Asil, Paulo Ramos, Amanda Starc, and Thomas G. Wollmann https://www.nber.org/papers/w33217

December 8, 2024 at 10:00 PM
Serial acquisitions of anesthesia practices led to price increases of 30 percent with no quality improvements, from Aslihan Asil, Paulo Ramos, Amanda Starc, and Thomas G. Wollmann https://www.nber.org/papers/w33217
When foundation models scale new benchmarks, it expands possibilities, re-calibrating benchmarks on internal tasks is no evidence of being AI savy.

A test of how seriously your firm is taking AI: when o-1 (& the new Gemini model) came out this week, were there assigned folks who immediately ran the model through your internal, validated, firm-specific benchmarks to see how useful it as? Did you update any plans or goals as a result?
December 7, 2024 at 9:29 PM
When foundation models scale new benchmarks, it expands possibilities, re-calibrating benchmarks on internal tasks is no evidence of being AI savy.