



Nicolas Keriven
@nicolaskeriven.bsky.social
CNRS researcher. Hates genAI with passion. Food and music 🎹 https://linktr.ee/bluecurlmusic

Horizon by Blue Curl
Stream and Save Horizon - Distributed by DistroKid
distrokid.com
August 6, 2025 at 11:39 AM
Colon, question mark, ticking all the boxes
May 23, 2025 at 8:32 AM
Colon, question mark, ticking all the boxes
Also note that we limit ourselves to vanilla GNNs: no skip connections, normalization, etc classical anti-oversmoothing strategies. That's for the future!
7/7
7/7
May 23, 2025 at 7:59 AM
Also note that we limit ourselves to vanilla GNNs: no skip connections, normalization, etc classical anti-oversmoothing strategies. That's for the future!
7/7
7/7
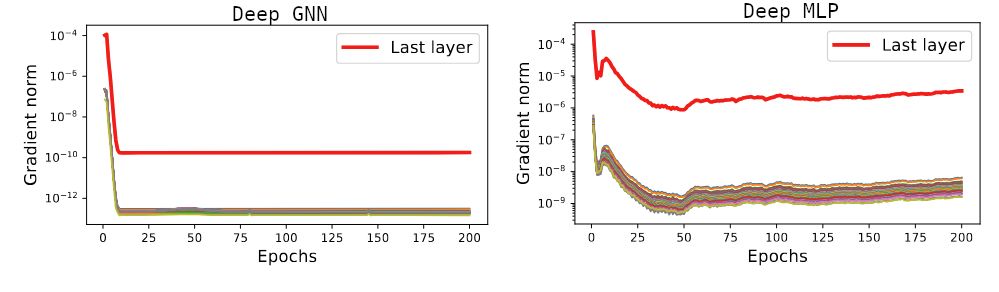
Note that, while many optimization results are adapted from MLP to GNNs, here this is *specific* to GNNs: we show that this does not happen for MLPs.
6/7
6/7
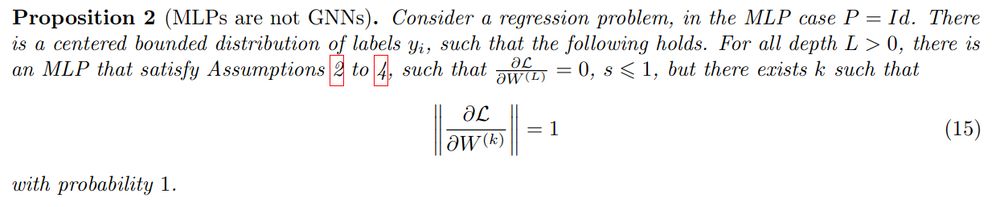
May 23, 2025 at 7:59 AM
Note that, while many optimization results are adapted from MLP to GNNs, here this is *specific* to GNNs: we show that this does not happen for MLPs.
6/7
6/7
...and that's bad! As soon as the last layer is trained (that happens immediately!), this average vanishes. The entire GNN is quickly stuck in a terrible near-critical point!
(*at every layers*, due to further mechanisms).
That's the main result of this paper.
5/7
(*at every layers*, due to further mechanisms).
That's the main result of this paper.
5/7

May 23, 2025 at 7:59 AM
...and that's bad! As soon as the last layer is trained (that happens immediately!), this average vanishes. The entire GNN is quickly stuck in a terrible near-critical point!
(*at every layers*, due to further mechanisms).
That's the main result of this paper.
5/7
(*at every layers*, due to further mechanisms).
That's the main result of this paper.
5/7
...the "oversmoothing" of the backward signal is very particular: *when the forward is oversmoothed*, the updates to the backward are almost "linear-GNN" with no non-linearity.
So we *can* compute its oversmoothed limit! It is the **average** of the prediction error...
4/7
So we *can* compute its oversmoothed limit! It is the **average** of the prediction error...
4/7
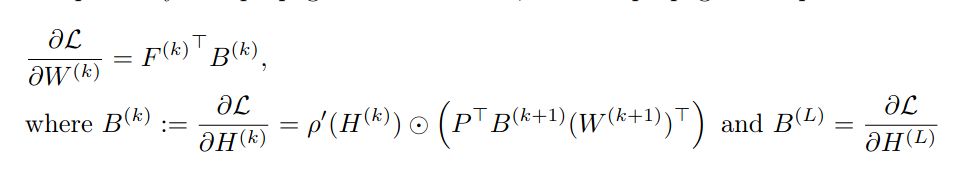
May 23, 2025 at 7:59 AM
...the "oversmoothing" of the backward signal is very particular: *when the forward is oversmoothed*, the updates to the backward are almost "linear-GNN" with no non-linearity.
So we *can* compute its oversmoothed limit! It is the **average** of the prediction error...
4/7
So we *can* compute its oversmoothed limit! It is the **average** of the prediction error...
4/7
... but at the *middle* layers! Due to the non-linearity, it oversmoothes *when the forward is also oversmoothed* 😲
Why is it bad for training? Well...
3/7
Why is it bad for training? Well...
3/7
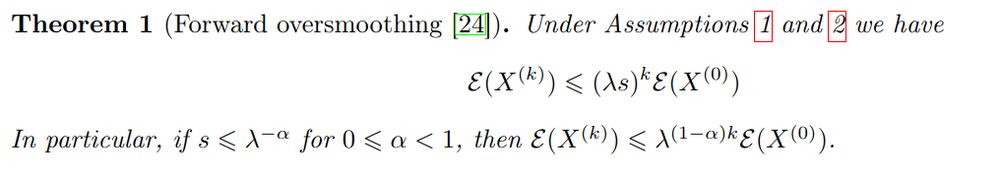
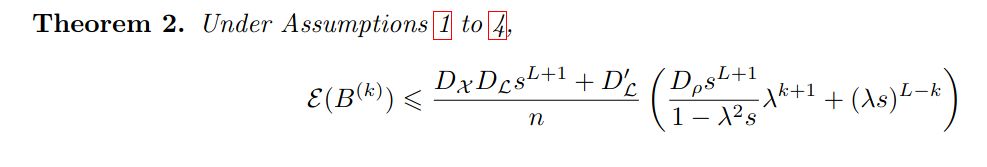
May 23, 2025 at 7:59 AM
... but at the *middle* layers! Due to the non-linearity, it oversmoothes *when the forward is also oversmoothed* 😲
Why is it bad for training? Well...
3/7
Why is it bad for training? Well...
3/7
The gradients are formed of two parts: the forward signal, and the backward "signal", initialized at the prediction error at the output then backpropagated.
Like the forward, the backward is multiplied by the graph matrix, so it will oversmooth...
2/7
Like the forward, the backward is multiplied by the graph matrix, so it will oversmooth...
2/7

May 23, 2025 at 7:59 AM
The gradients are formed of two parts: the forward signal, and the backward "signal", initialized at the prediction error at the output then backpropagated.
Like the forward, the backward is multiplied by the graph matrix, so it will oversmooth...
2/7
Like the forward, the backward is multiplied by the graph matrix, so it will oversmooth...
2/7