




Gergely Neu
@neu-rips.bsky.social
full-time ML theory nerd, part-time AI-non enthusiast
other than that, make sure to check out the really cool lineup of speakers and the program on the website: eurips.cc
i understand that registrations are still open, with some massive discounts (and even fee waivers!) for students. hope to see many of you there!!!
5/5
i understand that registrations are still open, with some massive discounts (and even fee waivers!) for students. hope to see many of you there!!!
5/5

October 29, 2025 at 11:47 AM
other than that, make sure to check out the really cool lineup of speakers and the program on the website: eurips.cc
i understand that registrations are still open, with some massive discounts (and even fee waivers!) for students. hope to see many of you there!!!
5/5
i understand that registrations are still open, with some massive discounts (and even fee waivers!) for students. hope to see many of you there!!!
5/5
dear reviewers, of course that "no pdf" rebuttal policy is not going to stop me from running all those wonderful new baselines you just suggested, please find the results below
July 28, 2025 at 8:24 AM
dear reviewers, of course that "no pdf" rebuttal policy is not going to stop me from running all those wonderful new baselines you just suggested, please find the results below
what's the opposite of FOMO called again? either way, i'm right in the middle of that
(hope everyone else is doing fine at #ICML2025 nevertheless!)
(hope everyone else is doing fine at #ICML2025 nevertheless!)

July 16, 2025 at 10:54 PM
what's the opposite of FOMO called again? either way, i'm right in the middle of that
(hope everyone else is doing fine at #ICML2025 nevertheless!)
(hope everyone else is doing fine at #ICML2025 nevertheless!)
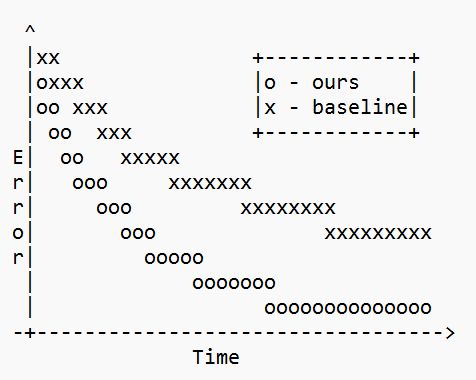
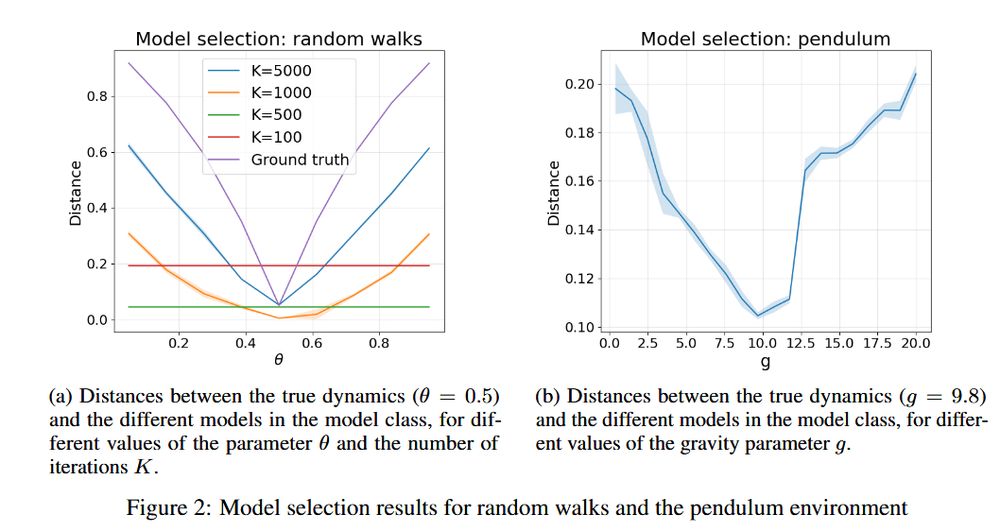
we also have some cool model-selection experiments that demonstrate the ability of our approach for computing similarities between Markov chains, which could be potentially very useful for representation learning in RL
10/n
10/n
May 26, 2025 at 1:27 PM
we also have some cool model-selection experiments that demonstrate the ability of our approach for computing similarities between Markov chains, which could be potentially very useful for representation learning in RL
10/n
10/n
interestingly, the variables λ_X and λ_Y can be interpreted as "encoder-decoder" pairs giving the conditional distributions of Y|X and X|Y.
we ran some experiments to illustrate this, e.g., here we use SOMCOT to discover the latent structure of a block Markov chain without any prior knowledge
9/n
we ran some experiments to illustrate this, e.g., here we use SOMCOT to discover the latent structure of a block Markov chain without any prior knowledge
9/n
May 26, 2025 at 1:27 PM
interestingly, the variables λ_X and λ_Y can be interpreted as "encoder-decoder" pairs giving the conditional distributions of Y|X and X|Y.
we ran some experiments to illustrate this, e.g., here we use SOMCOT to discover the latent structure of a block Markov chain without any prior knowledge
9/n
we ran some experiments to illustrate this, e.g., here we use SOMCOT to discover the latent structure of a block Markov chain without any prior knowledge
9/n
the algorithm is easy to implement and comes with nice sample-complexity guarantees. notably, no "concentrability" / "coverage" assumptions are required for the state distributions, the guarantees only depend on the sizes of the two chains
8/n
8/n

May 26, 2025 at 1:27 PM
the algorithm is easy to implement and comes with nice sample-complexity guarantees. notably, no "concentrability" / "coverage" assumptions are required for the state distributions, the guarantees only depend on the sizes of the two chains
8/n
8/n
.. which we can solve by a stochastic primal-dual method that we call SOMCOT (stochastic optimization for Markov-chain optimal transport). the idea is to observe that all gradients can be computed as *marginal* expectations over transition data, which allows constructing an efficient SGDA scheme
7/n
7/n

May 26, 2025 at 1:27 PM
.. which we can solve by a stochastic primal-dual method that we call SOMCOT (stochastic optimization for Markov-chain optimal transport). the idea is to observe that all gradients can be computed as *marginal* expectations over transition data, which allows constructing an efficient SGDA scheme
7/n
7/n
the main idea is rewriting the distance as a linear program whose constraints do not explicitly feature the transition kernels, only the *marginal distributions* of x->x' transitions. this allows us to formulate the problem as a stochastic min-max optimization game...
6/n
6/n


May 26, 2025 at 1:27 PM
the main idea is rewriting the distance as a linear program whose constraints do not explicitly feature the transition kernels, only the *marginal distributions* of x->x' transitions. this allows us to formulate the problem as a stochastic min-max optimization game...
6/n
6/n
in our neurips'24 paper, we developed some neat analytic tools an some computational methods to do this, but left a major open question behind: how to estimate distances for *unknown* Markov chains based on *samples only*?
4/n
4/n

May 26, 2025 at 1:27 PM
in our neurips'24 paper, we developed some neat analytic tools an some computational methods to do this, but left a major open question behind: how to estimate distances for *unknown* Markov chains based on *samples only*?
4/n
4/n
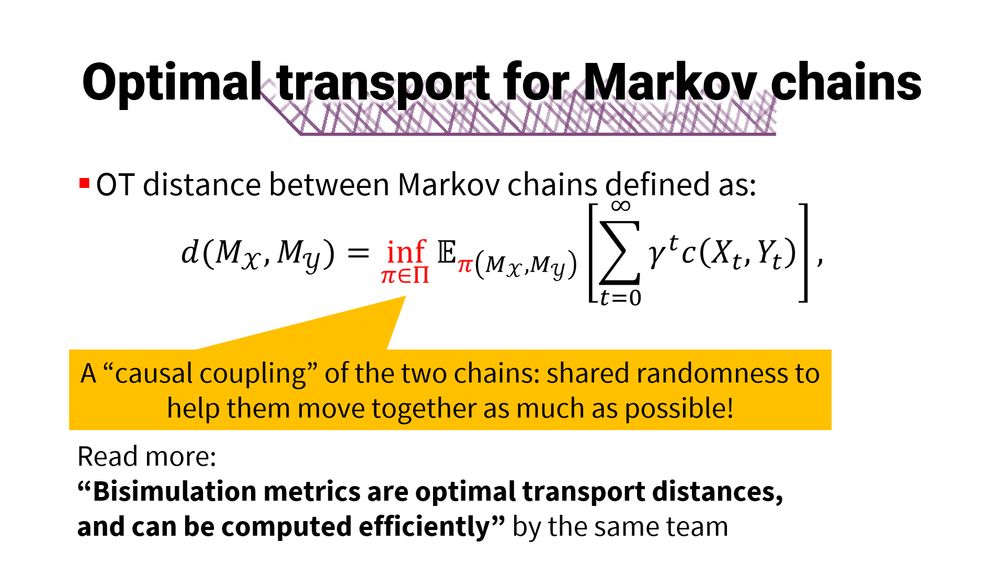
imagine i have two Markov chains M_X and M_Y, have a similarity metric over their state spaces, and want to lift this to a distance between the entire joint distributions. a powerful way to do that is via the tools of optimal transport (OT)
3/n
3/n

May 26, 2025 at 1:27 PM
imagine i have two Markov chains M_X and M_Y, have a similarity metric over their state spaces, and want to lift this to a distance between the entire joint distributions. a powerful way to do that is via the tools of optimal transport (OT)
3/n
3/n
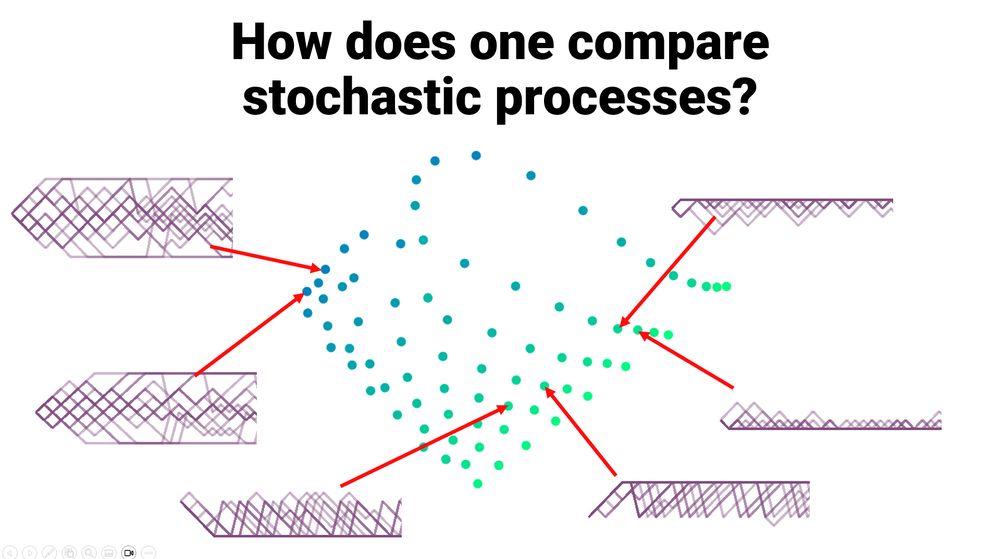
in a 2024 paper (w/ Sergio Calo, Anders Jonsson, Ludovic Schwartz & Javier Segovia-Aguas), we explored the question of defining and computing similarity metrics between Markov chains (arxiv.org/abs/2406.04056). we are back asking the same question, and giving some even more satisfying answers
2/n
2/n
May 26, 2025 at 1:27 PM
in a 2024 paper (w/ Sergio Calo, Anders Jonsson, Ludovic Schwartz & Javier Segovia-Aguas), we explored the question of defining and computing similarity metrics between Markov chains (arxiv.org/abs/2406.04056). we are back asking the same question, and giving some even more satisfying answers
2/n
2/n
new work on computing distances between stochastic processes ***based on sample paths only***! we can now:
- learn distances between Markov chains
- extract "encoder-decoder" pairs for representation learning
- with sample- and computational-complexity guarantees
read on for some quick details..
1/n
- learn distances between Markov chains
- extract "encoder-decoder" pairs for representation learning
- with sample- and computational-complexity guarantees
read on for some quick details..
1/n
May 26, 2025 at 1:27 PM
new work on computing distances between stochastic processes ***based on sample paths only***! we can now:
- learn distances between Markov chains
- extract "encoder-decoder" pairs for representation learning
- with sample- and computational-complexity guarantees
read on for some quick details..
1/n
- learn distances between Markov chains
- extract "encoder-decoder" pairs for representation learning
- with sample- and computational-complexity guarantees
read on for some quick details..
1/n
posting something nice soon
May 17, 2025 at 7:48 AM
posting something nice soon
time to smash that TURBO button

May 15, 2025 at 5:18 PM
time to smash that TURBO button
looking forward to giving a talk at the 2025 GHOST day in the beautiful city of Poznan (Poland) --- hope to see you there this weekend!

May 6, 2025 at 7:06 PM
looking forward to giving a talk at the 2025 GHOST day in the beautiful city of Poznan (Poland) --- hope to see you there this weekend!
"no politics in the classroom", right?
(from Boaz's ALT 2025 keynote)
(from Boaz's ALT 2025 keynote)

May 3, 2025 at 2:42 PM
"no politics in the classroom", right?
(from Boaz's ALT 2025 keynote)
(from Boaz's ALT 2025 keynote)
this work was gloriously led by my absolutely ✨brilliant✨ postdocs: Eugenio Clerico and Hamish Flynn. they're both on the job market so do reach out to them if you are looking to recruit some outstanding learning theorists.
my friend Wojtek Kotlowski also helped out quite a lot.
12/
my friend Wojtek Kotlowski also helped out quite a lot.
12/

April 23, 2025 at 10:41 PM
this work was gloriously led by my absolutely ✨brilliant✨ postdocs: Eugenio Clerico and Hamish Flynn. they're both on the job market so do reach out to them if you are looking to recruit some outstanding learning theorists.
my friend Wojtek Kotlowski also helped out quite a lot.
12/
my friend Wojtek Kotlowski also helped out quite a lot.
12/
the proof is really simple, and possibly even trivial. (just notice that the second term in this decomposition is almost always negative: you can't predict Y_t better than theta* if you have to predict sequentially.)
8/
8/

April 23, 2025 at 10:41 PM
the proof is really simple, and possibly even trivial. (just notice that the second term in this decomposition is almost always negative: you can't predict Y_t better than theta* if you have to predict sequentially.)
8/
8/
our main result is the following: if i can design an online learning algorithm for this game with regret bounded by B, then i can set my confidence width as beta_n = B + log (1/delta), and end up with a confidence set that's valid with probability at least 1-delta
7/
7/

April 23, 2025 at 10:41 PM
our main result is the following: if i can design an online learning algorithm for this game with regret bounded by B, then i can set my confidence width as beta_n = B + log (1/delta), and end up with a confidence set that's valid with probability at least 1-delta
7/
7/
so here's the idea. let us introduce a game of "sequential probability assignment" where an online learner is trying to predict the next Y_t given all the past data, and define its regret against the best fixed strategy in hindsight that always predicts using the MLE
6/
6/

April 23, 2025 at 10:41 PM
so here's the idea. let us introduce a game of "sequential probability assignment" where an online learner is trying to predict the next Y_t given all the past data, and define its regret against the best fixed strategy in hindsight that always predicts using the MLE
6/
6/
now, the problem that motivated the present work is that i can never remember the details of this construction and the proof, so i wanted to find an alternative that reduces the problem to something that i understand reasonably well: ONLINE LEARNING
5/
5/

April 23, 2025 at 10:41 PM
now, the problem that motivated the present work is that i can never remember the details of this construction and the proof, so i wanted to find an alternative that reduces the problem to something that i understand reasonably well: ONLINE LEARNING
5/
5/
we specifically consider sets that contain all parameters whose likelihood is not much smaller than that of the maximum likelihood estimator. thus we would like to find methods for picking the "cutoff" parameter beta_n in a way that leads to small and valid confidence sets
3/
3/

April 23, 2025 at 10:41 PM
we specifically consider sets that contain all parameters whose likelihood is not much smaller than that of the maximum likelihood estimator. thus we would like to find methods for picking the "cutoff" parameter beta_n in a way that leads to small and valid confidence sets
3/
3/
we consider generalized linear models (see pic below), and would like to construct a small set that contains the true parameter theta* with high probability, based on observations (X_t,Y_t)_{t=1}^n
2/
2/

April 23, 2025 at 10:41 PM
we consider generalized linear models (see pic below), and would like to construct a small set that contains the true parameter theta* with high probability, based on observations (X_t,Y_t)_{t=1}^n
2/
2/
new paper online:
"CONFIDENCE SEQUENCES FOR GENERALIZED LINEAR MODELS VIA REGRET ANALYSIS"
TL;DR: we reduce the problem of designing tight confidence sets for statistical models to proving the existence of small regret bounds in an online prediction game
read on for a quick thread 👀👀👀
1/
"CONFIDENCE SEQUENCES FOR GENERALIZED LINEAR MODELS VIA REGRET ANALYSIS"
TL;DR: we reduce the problem of designing tight confidence sets for statistical models to proving the existence of small regret bounds in an online prediction game
read on for a quick thread 👀👀👀
1/

April 23, 2025 at 10:41 PM
new paper online:
"CONFIDENCE SEQUENCES FOR GENERALIZED LINEAR MODELS VIA REGRET ANALYSIS"
TL;DR: we reduce the problem of designing tight confidence sets for statistical models to proving the existence of small regret bounds in an online prediction game
read on for a quick thread 👀👀👀
1/
"CONFIDENCE SEQUENCES FOR GENERALIZED LINEAR MODELS VIA REGRET ANALYSIS"
TL;DR: we reduce the problem of designing tight confidence sets for statistical models to proving the existence of small regret bounds in an online prediction game
read on for a quick thread 👀👀👀
1/