



@neelnanda.bsky.social
The call for papers for the NeurIPS Mechanistic Interpretability Workshop is open!
Max 4 or 9 pages, due 22 Aug, NeurIPS submissions welcome
We welcome any works that further our ability to use the internals of a model to better understand it
Details: mechinterpworkshop com
Max 4 or 9 pages, due 22 Aug, NeurIPS submissions welcome
We welcome any works that further our ability to use the internals of a model to better understand it
Details: mechinterpworkshop com

July 13, 2025 at 1:00 PM
The call for papers for the NeurIPS Mechanistic Interpretability Workshop is open!
Max 4 or 9 pages, due 22 Aug, NeurIPS submissions welcome
We welcome any works that further our ability to use the internals of a model to better understand it
Details: mechinterpworkshop com
Max 4 or 9 pages, due 22 Aug, NeurIPS submissions welcome
We welcome any works that further our ability to use the internals of a model to better understand it
Details: mechinterpworkshop com
The mindset of Socratic Persuasion is shockingly versatile. I use it on a near daily basis in my personal and professional life: conflict resolution, helping prioritize, correcting misconceptions, gently giving negative feedback. My post has 8 case studies, to give you a sense:

May 26, 2025 at 6:37 PM
The mindset of Socratic Persuasion is shockingly versatile. I use it on a near daily basis in my personal and professional life: conflict resolution, helping prioritize, correcting misconceptions, gently giving negative feedback. My post has 8 case studies, to give you a sense:
Isn't this all obvious?
Maybe! Asking questions rather than lecturing people is hardly a novel insight
But people often assume the Qs must be neutral and open-ended. It can be very useful to be opinionated! But you need error correction mechanisms for when you're wrong.
Maybe! Asking questions rather than lecturing people is hardly a novel insight
But people often assume the Qs must be neutral and open-ended. It can be very useful to be opinionated! But you need error correction mechanisms for when you're wrong.

May 26, 2025 at 6:37 PM
Isn't this all obvious?
Maybe! Asking questions rather than lecturing people is hardly a novel insight
But people often assume the Qs must be neutral and open-ended. It can be very useful to be opinionated! But you need error correction mechanisms for when you're wrong.
Maybe! Asking questions rather than lecturing people is hardly a novel insight
But people often assume the Qs must be neutral and open-ended. It can be very useful to be opinionated! But you need error correction mechanisms for when you're wrong.
Crucially, the goal is to give the right advice, not to *be* right. Asking Qs is far better received when you are genuinely listening to the answers, and open to changing your mind. No matter how much I know about a topic, they know more about their life, and I'm often wrong.

May 26, 2025 at 6:37 PM
Crucially, the goal is to give the right advice, not to *be* right. Asking Qs is far better received when you are genuinely listening to the answers, and open to changing your mind. No matter how much I know about a topic, they know more about their life, and I'm often wrong.
Socratic persuasion is more effective if I'm right: they feel more like they generated the argument themselves, and are less defensive.
Done right, I think its more collaborative - combining my perspective and their context to find the best advice. Better for both parties!
Done right, I think its more collaborative - combining my perspective and their context to find the best advice. Better for both parties!

May 26, 2025 at 6:37 PM
Socratic persuasion is more effective if I'm right: they feel more like they generated the argument themselves, and are less defensive.
Done right, I think its more collaborative - combining my perspective and their context to find the best advice. Better for both parties!
Done right, I think its more collaborative - combining my perspective and their context to find the best advice. Better for both parties!
I can integrate the new info and pivot if needed, without embarrassment, and together we converge on the right advice. It's far more robust - since the other person is actively answering questions, disagreements surface fast
The post: www.neelnanda.io/blog/51-soc...
More thoughts in 🧵
The post: www.neelnanda.io/blog/51-soc...
More thoughts in 🧵

May 26, 2025 at 6:37 PM
I can integrate the new info and pivot if needed, without embarrassment, and together we converge on the right advice. It's far more robust - since the other person is actively answering questions, disagreements surface fast
The post: www.neelnanda.io/blog/51-soc...
More thoughts in 🧵
The post: www.neelnanda.io/blog/51-soc...
More thoughts in 🧵
Blog post: I often give advice, to mentees, friends, etc. This is hard! I'm often missing context
My favourite approach is Socratic persuasion: guiding them through my case via questions. If I'm wrong there's soon a surprising answer!
I can be opinionated *and* truth seeking
My favourite approach is Socratic persuasion: guiding them through my case via questions. If I'm wrong there's soon a surprising answer!
I can be opinionated *and* truth seeking

May 26, 2025 at 6:37 PM
Blog post: I often give advice, to mentees, friends, etc. This is hard! I'm often missing context
My favourite approach is Socratic persuasion: guiding them through my case via questions. If I'm wrong there's soon a surprising answer!
I can be opinionated *and* truth seeking
My favourite approach is Socratic persuasion: guiding them through my case via questions. If I'm wrong there's soon a surprising answer!
I can be opinionated *and* truth seeking
There are many moving pieces when turning a project into a machine learning conference paper, and best practices/nuances no one writes up. I made a comprehensive paper writing checklist for my mentees and am sharing a public version below - hopefully it's useful, esp for NeurIPS!

May 11, 2025 at 10:47 PM
There are many moving pieces when turning a project into a machine learning conference paper, and best practices/nuances no one writes up. I made a comprehensive paper writing checklist for my mentees and am sharing a public version below - hopefully it's useful, esp for NeurIPS!
Post 3: What is research taste?
This mystical notion separates new and experienced researchers. It's real and important. But what is it and how to learn it?
I break down taste as the mix of intuition/models behind good open-ended decisions and share tricks to speed up learning
x.com/NeelNanda5/...
This mystical notion separates new and experienced researchers. It's real and important. But what is it and how to learn it?
I break down taste as the mix of intuition/models behind good open-ended decisions and share tricks to speed up learning
x.com/NeelNanda5/...

May 2, 2025 at 1:00 PM
Post 3: What is research taste?
This mystical notion separates new and experienced researchers. It's real and important. But what is it and how to learn it?
I break down taste as the mix of intuition/models behind good open-ended decisions and share tricks to speed up learning
x.com/NeelNanda5/...
This mystical notion separates new and experienced researchers. It's real and important. But what is it and how to learn it?
I break down taste as the mix of intuition/models behind good open-ended decisions and share tricks to speed up learning
x.com/NeelNanda5/...
Great work by @NunoSempere and co. Check out yesterday's here:
blog.sentinel-team.org/p/global-ri...
blog.sentinel-team.org/p/global-ri...

April 29, 2025 at 1:00 PM
Great work by @NunoSempere and co. Check out yesterday's here:
blog.sentinel-team.org/p/global-ri...
blog.sentinel-team.org/p/global-ri...
I'm very impressed with the Sentinel newsletter: by far the best aggregator of global news I've found
Expert forecasters filter for the events that actually matter (not just noise), and forecast how likely this is to affect eg war, pandemics, frontier AI etc
Highly recommended!
Expert forecasters filter for the events that actually matter (not just noise), and forecast how likely this is to affect eg war, pandemics, frontier AI etc
Highly recommended!

April 29, 2025 at 1:00 PM
I'm very impressed with the Sentinel newsletter: by far the best aggregator of global news I've found
Expert forecasters filter for the events that actually matter (not just noise), and forecast how likely this is to affect eg war, pandemics, frontier AI etc
Highly recommended!
Expert forecasters filter for the events that actually matter (not just noise), and forecast how likely this is to affect eg war, pandemics, frontier AI etc
Highly recommended!
As a striking example of how effective this is, Matryoshka SAEs fairly reliably get better on most metrics as you make them wider, as neural networks should. Normal sparse autoencoders do not.

April 2, 2025 at 1:01 PM
As a striking example of how effective this is, Matryoshka SAEs fairly reliably get better on most metrics as you make them wider, as neural networks should. Normal sparse autoencoders do not.
This slightly worsens reconstruction (it's basically regurisation), but improves performance substantially on some downstream tasks and measurements of sparsity issues!


April 2, 2025 at 1:01 PM
This slightly worsens reconstruction (it's basically regurisation), but improves performance substantially on some downstream tasks and measurements of sparsity issues!
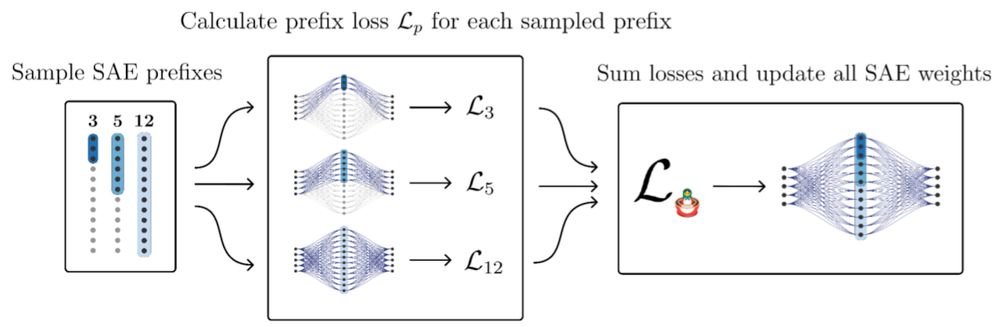
With a small tweak to the loss, we can simultaneously train SAEs of several different sizes that all work together to reconstruct things. Small ones learn high-level features, while wide ones learn low-level features!
April 2, 2025 at 1:01 PM
With a small tweak to the loss, we can simultaneously train SAEs of several different sizes that all work together to reconstruct things. Small ones learn high-level features, while wide ones learn low-level features!
In this specific case, the work focused on how sparsity is an imperfect proxy to optimize if we actually want interpretability. In particular, wide SAEs break apart high-level concepts into narrower ones via absorption, composition, and splitting.

April 2, 2025 at 1:01 PM
In this specific case, the work focused on how sparsity is an imperfect proxy to optimize if we actually want interpretability. In particular, wide SAEs break apart high-level concepts into narrower ones via absorption, composition, and splitting.
This was great to supervise - the kind of basic science of SAEs work that's most promising IMO! Find a fundamental issue with SAEs, fixing it with an adjustment (here a different loss), and rigorously measuring how much it's fixed. I recommend using Matryoshka where possible.
x.com/BartBussman...
x.com/BartBussman...

April 2, 2025 at 1:01 PM
This was great to supervise - the kind of basic science of SAEs work that's most promising IMO! Find a fundamental issue with SAEs, fixing it with an adjustment (here a different loss), and rigorously measuring how much it's fixed. I recommend using Matryoshka where possible.
x.com/BartBussman...
x.com/BartBussman...
New post: A weird phenomenon: because I have evidence of doing good interpretability research, people assume I have good big picture takes about how it matters for AGI X-risk. I try, but these are different skillsets! Before deferring, check for *relevant* evidence of skill.

March 22, 2025 at 12:00 PM
New post: A weird phenomenon: because I have evidence of doing good interpretability research, people assume I have good big picture takes about how it matters for AGI X-risk. I try, but these are different skillsets! Before deferring, check for *relevant* evidence of skill.
More details on applied interp soon!
More broadly, the AGI Safety team is keen to get applications from both strong ML engineers and strong ML researchers.
Please apply!
More broadly, the AGI Safety team is keen to get applications from both strong ML engineers and strong ML researchers.
Please apply!

February 18, 2025 at 2:00 PM
More details on applied interp soon!
More broadly, the AGI Safety team is keen to get applications from both strong ML engineers and strong ML researchers.
Please apply!
More broadly, the AGI Safety team is keen to get applications from both strong ML engineers and strong ML researchers.
Please apply!
Obviously, small SAEs can't capture everything. But making it larger isn't enough, as sparsity incentivises high-level concepts to be absorbed into new ones.
But not all hope is lost - our forthcoming paper on Matryoshka SAEs seems to substantially improve these issues!
But not all hope is lost - our forthcoming paper on Matryoshka SAEs seems to substantially improve these issues!

February 11, 2025 at 6:22 PM
Obviously, small SAEs can't capture everything. But making it larger isn't enough, as sparsity incentivises high-level concepts to be absorbed into new ones.
But not all hope is lost - our forthcoming paper on Matryoshka SAEs seems to substantially improve these issues!
But not all hope is lost - our forthcoming paper on Matryoshka SAEs seems to substantially improve these issues!
As part of opening my new round of MATS applications, I took this as an excuse to write up which research discussions I'm currently just excited about, and recent updates I've made - I thought this might be of more general interest!
x.com/NeelNanda5/...
x.com/NeelNanda5/...

February 8, 2025 at 1:57 PM
As part of opening my new round of MATS applications, I took this as an excuse to write up which research discussions I'm currently just excited about, and recent updates I've made - I thought this might be of more general interest!
x.com/NeelNanda5/...
x.com/NeelNanda5/...