



Reposted by Martin Jaggi

Breaking: we release a fully synthetic generalist dataset for pretraining, SYNTH and two new SOTA reasoning models exclusively trained on it. Despite having seen only 200 billion tokens, Baguettotron is currently best-in-class in its size range. pleias.fr/blog/blogsyn...

November 10, 2025 at 5:30 PM
Breaking: we release a fully synthetic generalist dataset for pretraining, SYNTH and two new SOTA reasoning models exclusively trained on it. Despite having seen only 200 billion tokens, Baguettotron is currently best-in-class in its size range. pleias.fr/blog/blogsyn...
Reposted by Martin Jaggi

🎉 ICML 2026 Call for Papers (& Position Papers) is here! 🎉
📅 Key Dates
Abstract deadline: Jan 23, 2026 AOE
Paper deadline: Jan 28, 2026 AOE
A few key changes this year:
- Attendance for authors of accepted papers is optional
- Originally submitted version of accepted papers will be made public
...
📅 Key Dates
Abstract deadline: Jan 23, 2026 AOE
Paper deadline: Jan 28, 2026 AOE
A few key changes this year:
- Attendance for authors of accepted papers is optional
- Originally submitted version of accepted papers will be made public
...

November 7, 2025 at 2:42 PM
🎉 ICML 2026 Call for Papers (& Position Papers) is here! 🎉
📅 Key Dates
Abstract deadline: Jan 23, 2026 AOE
Paper deadline: Jan 28, 2026 AOE
A few key changes this year:
- Attendance for authors of accepted papers is optional
- Originally submitted version of accepted papers will be made public
...
📅 Key Dates
Abstract deadline: Jan 23, 2026 AOE
Paper deadline: Jan 28, 2026 AOE
A few key changes this year:
- Attendance for authors of accepted papers is optional
- Originally submitted version of accepted papers will be made public
...
so open-weights models are much happier than closed ones i guess, cause they live on in the long run, did i get that right?

Anthropic Model Depreciation Process
Anthropic sweetly asked Sonnet about its preferences in how it wanted to be deprecated
in addition:
- no, still not open weights
- preserve weights and keeping it running internally
- letting models pursue their interests
www.anthropic.com/research/dep...
Anthropic sweetly asked Sonnet about its preferences in how it wanted to be deprecated
in addition:
- no, still not open weights
- preserve weights and keeping it running internally
- letting models pursue their interests
www.anthropic.com/research/dep...

November 5, 2025 at 12:32 PM
so open-weights models are much happier than closed ones i guess, cause they live on in the long run, did i get that right?
91% of reasoning does not need RL 🤯 arxiv.org/abs/2510.07364

Base Models Know How to Reason, Thinking Models Learn When
Why do thinking language models like DeepSeek R1 outperform their base counterparts? Despite consistent performance gains, it remains unclear to what extent thinking models learn entirely new reasonin...
arxiv.org
October 14, 2025 at 9:53 PM
91% of reasoning does not need RL 🤯 arxiv.org/abs/2510.07364
Reposted by Martin Jaggi

I just tried the official demo for the new Gemini 2.5 Computer Use model and it started by navigating to Google, solving Google's own CAPTCHA and then running a search! https://simonwillison.net/2025/Oct/7/gemini-25-computer-use-captchas/

Gemini 2.5 Computer Use can solve Google’s own CAPTCHAs
Google just introduced a new Gemini 2.5 Computer Use model, specially designed to help operate a GUI interface by interacting with visible elements using a virtual mouse and keyboard. I …
simonwillison.net
October 7, 2025 at 9:20 PM
I just tried the official demo for the new Gemini 2.5 Computer Use model and it started by navigating to Google, solving Google's own CAPTCHA and then running a search! https://simonwillison.net/2025/Oct/7/gemini-25-computer-use-captchas/
We're hiring again for AI research engineering roles: Join the team behind the Apertus LLM, if you share our passion to work on impactful AI that's truly open.
careers.epfl.ch/job/Lausanne...
careers.epfl.ch/job/Lausanne...
AI Research Engineers - Swiss AI Initiative
AI Research Engineers - Swiss AI Initiative
careers.epfl.ch
September 25, 2025 at 9:08 PM
We're hiring again for AI research engineering roles: Join the team behind the Apertus LLM, if you share our passion to work on impactful AI that's truly open.
careers.epfl.ch/job/Lausanne...
careers.epfl.ch/job/Lausanne...
Reposted by Martin Jaggi

1/🚨 New preprint
How do #LLMs’ inner features change as they train? Using #crosscoders + a new causal metric, we map when features appear, strengthen, or fade across checkpoints—opening a new lens on training dynamics beyond loss curves & benchmarks.
#interpretability
How do #LLMs’ inner features change as they train? Using #crosscoders + a new causal metric, we map when features appear, strengthen, or fade across checkpoints—opening a new lens on training dynamics beyond loss curves & benchmarks.
#interpretability

September 25, 2025 at 2:02 PM
1/🚨 New preprint
How do #LLMs’ inner features change as they train? Using #crosscoders + a new causal metric, we map when features appear, strengthen, or fade across checkpoints—opening a new lens on training dynamics beyond loss curves & benchmarks.
#interpretability
How do #LLMs’ inner features change as they train? Using #crosscoders + a new causal metric, we map when features appear, strengthen, or fade across checkpoints—opening a new lens on training dynamics beyond loss curves & benchmarks.
#interpretability
Reposted by Martin Jaggi

Schweizer Sprachmodell Apertus: So sieht EU-konforme, transparente KI aus
https://www.heise.de/hintergrund/Schweizer-Sprachmodell-Apertus-So-sieht-EU-konforme-transparente-KI-aus-10638501.html?utm_source=flipboard&utm_medium=activitypub
Gepostet in Nachrichten @nachrichten-heiseonline
https://www.heise.de/hintergrund/Schweizer-Sprachmodell-Apertus-So-sieht-EU-konforme-transparente-KI-aus-10638501.html?utm_source=flipboard&utm_medium=activitypub
Gepostet in Nachrichten @nachrichten-heiseonline

Schweizer Sprachmodell Apertus: So sieht EU-konforme, transparente KI aus
Vielsprachigkeit, Transparenz, Respekt vor geistigem Eigentum: Das offene große Sprachmodell aus Schweizer KI-Schmieden verinnerlicht europäische Werte.
www.heise.de
September 24, 2025 at 5:05 PM
Schweizer Sprachmodell Apertus: So sieht EU-konforme, transparente KI aus
https://www.heise.de/hintergrund/Schweizer-Sprachmodell-Apertus-So-sieht-EU-konforme-transparente-KI-aus-10638501.html?utm_source=flipboard&utm_medium=activitypub
Gepostet in Nachrichten @nachrichten-heiseonline
https://www.heise.de/hintergrund/Schweizer-Sprachmodell-Apertus-So-sieht-EU-konforme-transparente-KI-aus-10638501.html?utm_source=flipboard&utm_medium=activitypub
Gepostet in Nachrichten @nachrichten-heiseonline
Reposted by Martin Jaggi

Hugging Face's FinePDFs
The largest publicly available corpus sourced exclusively from PDFs, containing about 3 trillion tokens across 475 million documents in 1733 languages.
- Long context
- 3T tokens from high-demand domains like legal and science.
- Heavily improves over SoTA
The largest publicly available corpus sourced exclusively from PDFs, containing about 3 trillion tokens across 475 million documents in 1733 languages.
- Long context
- 3T tokens from high-demand domains like legal and science.
- Heavily improves over SoTA

September 7, 2025 at 9:38 AM
Hugging Face's FinePDFs
The largest publicly available corpus sourced exclusively from PDFs, containing about 3 trillion tokens across 475 million documents in 1733 languages.
- Long context
- 3T tokens from high-demand domains like legal and science.
- Heavily improves over SoTA
The largest publicly available corpus sourced exclusively from PDFs, containing about 3 trillion tokens across 475 million documents in 1733 languages.
- Long context
- 3T tokens from high-demand domains like legal and science.
- Heavily improves over SoTA
you can run the new apertus LLMs fully locally on your (mac) laptop with just 2 lines of code:
pip install mlx-lm
mlx_lm.generate --model swiss-ai/Apertus-8B-Instruct-2509 --prompt "wer bisch du?"
(make sure you have done huggingface-cli login before)
pip install mlx-lm
mlx_lm.generate --model swiss-ai/Apertus-8B-Instruct-2509 --prompt "wer bisch du?"
(make sure you have done huggingface-cli login before)

Apertus LLM - a swiss-ai Collection
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
September 5, 2025 at 9:31 PM
you can run the new apertus LLMs fully locally on your (mac) laptop with just 2 lines of code:
pip install mlx-lm
mlx_lm.generate --model swiss-ai/Apertus-8B-Instruct-2509 --prompt "wer bisch du?"
(make sure you have done huggingface-cli login before)
pip install mlx-lm
mlx_lm.generate --model swiss-ai/Apertus-8B-Instruct-2509 --prompt "wer bisch du?"
(make sure you have done huggingface-cli login before)
Reposted by Martin Jaggi

Am Schluss müssen sich die Medienverlage eine gesonderte Lösung überlegen, da sie kaum für alle Schweizer Blogger, Firmenwebsites, Künstler:innen,Gesundheitsportalen, eCommerce-Plattformen sprechen können.
WBK N will weder Opt Out noch Opt In festschreiben.
WBK N will weder Opt Out noch Opt In festschreiben.

September 5, 2025 at 5:10 PM
Am Schluss müssen sich die Medienverlage eine gesonderte Lösung überlegen, da sie kaum für alle Schweizer Blogger, Firmenwebsites, Künstler:innen,Gesundheitsportalen, eCommerce-Plattformen sprechen können.
WBK N will weder Opt Out noch Opt In festschreiben.
WBK N will weder Opt Out noch Opt In festschreiben.
Reposted by Martin Jaggi

The next generation of open LLMs should be inclusive, compliant, and multilingual by design. That’s why we @icepfl.bsky.social @ethz.ch @cscsch.bsky.social ) built Apertus.
EPFL, ETH Zurich & CSCS just released Apertus, Switzerland’s first fully open-source large language model.
Trained on 15T tokens in 1,000+ languages, it’s built for transparency, responsibility & the public good.
Read more: actu.epfl.ch/news/apertus...
Trained on 15T tokens in 1,000+ languages, it’s built for transparency, responsibility & the public good.
Read more: actu.epfl.ch/news/apertus...

September 3, 2025 at 9:26 AM
The next generation of open LLMs should be inclusive, compliant, and multilingual by design. That’s why we @icepfl.bsky.social @ethz.ch @cscsch.bsky.social ) built Apertus.
new extensive evaluation of different optimizers for LLM training
arxiv.org/abs/2509.01440
arxiv.org/abs/2509.01440

Benchmarking Optimizers for Large Language Model Pretraining
The recent development of Large Language Models (LLMs) has been accompanied by an effervescence of novel ideas and methods to better optimize the loss of deep learning models. Claims from those method...
arxiv.org
September 3, 2025 at 10:44 AM
new extensive evaluation of different optimizers for LLM training
arxiv.org/abs/2509.01440
arxiv.org/abs/2509.01440
Reposted by Martin Jaggi

Die Schweiz steigt ins Rennen der grossen Sprachmodelle ein. Unter dem Namen #Apertus veröffentlichen @ethz.ch, @icepfl.bsky.social und das @cscsch.bsky.social das erste vollständig offene, mehrsprachige #LLM des Landes.
Fürs MAZ habe ich Apertus kurz analysiert:
www.maz.ch/news/apertus...
Fürs MAZ habe ich Apertus kurz analysiert:
www.maz.ch/news/apertus...

Apertus: ein neues Sprachmodell für die Schweiz
www.maz.ch
September 2, 2025 at 8:33 AM
Die Schweiz steigt ins Rennen der grossen Sprachmodelle ein. Unter dem Namen #Apertus veröffentlichen @ethz.ch, @icepfl.bsky.social und das @cscsch.bsky.social das erste vollständig offene, mehrsprachige #LLM des Landes.
Fürs MAZ habe ich Apertus kurz analysiert:
www.maz.ch/news/apertus...
Fürs MAZ habe ich Apertus kurz analysiert:
www.maz.ch/news/apertus...
Reposted by Martin Jaggi

EPFL, ETH Zurich & CSCS just released Apertus, Switzerland’s first fully open-source large language model.
Trained on 15T tokens in 1,000+ languages, it’s built for transparency, responsibility & the public good.
Read more: actu.epfl.ch/news/apertus...
Trained on 15T tokens in 1,000+ languages, it’s built for transparency, responsibility & the public good.
Read more: actu.epfl.ch/news/apertus...
September 2, 2025 at 11:48 AM
EPFL, ETH Zurich & CSCS just released Apertus, Switzerland’s first fully open-source large language model.
Trained on 15T tokens in 1,000+ languages, it’s built for transparency, responsibility & the public good.
Read more: actu.epfl.ch/news/apertus...
Trained on 15T tokens in 1,000+ languages, it’s built for transparency, responsibility & the public good.
Read more: actu.epfl.ch/news/apertus...
Reposted by Martin Jaggi

EPFL and ETH Zürich are building together a Swiss made LLM from scratch.
Fully open and multilingual, the model is trained on CSCS's supercomputer "Alps" and supports sovereign, transparent, and responsible AI in Switzerland and beyond.
Read more here: ai.epfl.ch/a-language-m...
#ResponsibleAI
Fully open and multilingual, the model is trained on CSCS's supercomputer "Alps" and supports sovereign, transparent, and responsible AI in Switzerland and beyond.
Read more here: ai.epfl.ch/a-language-m...
#ResponsibleAI

A language model built for the public good - EPFL AI Center
ETH Zurich and EPFL will release a large language model (LLM) developed on public infrastructure. Trained on the “Alps” supercomputer at the Swiss National Supercomputing Centre (CSCS), the new LLM ma...
ai.epfl.ch
July 9, 2025 at 7:26 AM
EPFL and ETH Zürich are building together a Swiss made LLM from scratch.
Fully open and multilingual, the model is trained on CSCS's supercomputer "Alps" and supports sovereign, transparent, and responsible AI in Switzerland and beyond.
Read more here: ai.epfl.ch/a-language-m...
#ResponsibleAI
Fully open and multilingual, the model is trained on CSCS's supercomputer "Alps" and supports sovereign, transparent, and responsible AI in Switzerland and beyond.
Read more here: ai.epfl.ch/a-language-m...
#ResponsibleAI

Reposted by Martin Jaggi

Why did Grok suddenly start talking about “white genocide in South Africa” even if asked about baseball or cute dogs?
Because someone at Musk’s xAi deliberately did this, and we only found out because they were clumsy.
My piece on the real dangers of AI.
Gift link:
www.nytimes.com/2025/05/17/o...
Because someone at Musk’s xAi deliberately did this, and we only found out because they were clumsy.
My piece on the real dangers of AI.
Gift link:
www.nytimes.com/2025/05/17/o...

May 17, 2025 at 11:31 AM
Why did Grok suddenly start talking about “white genocide in South Africa” even if asked about baseball or cute dogs?
Because someone at Musk’s xAi deliberately did this, and we only found out because they were clumsy.
My piece on the real dangers of AI.
Gift link:
www.nytimes.com/2025/05/17/o...
Because someone at Musk’s xAi deliberately did this, and we only found out because they were clumsy.
My piece on the real dangers of AI.
Gift link:
www.nytimes.com/2025/05/17/o...
Reposted by Martin Jaggi

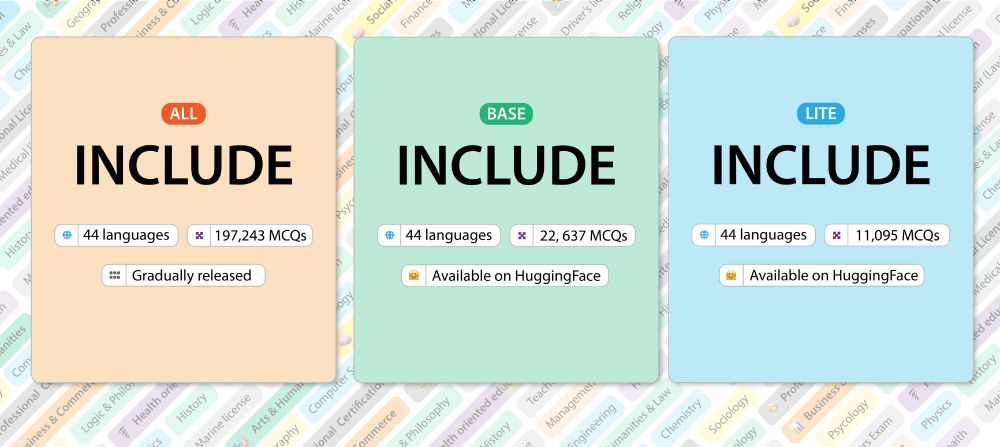
If you’re at @iclr-conf.bsky.social this week, come check out our spotlight poster INCLUDE during the Thursday 3:00–5:30pm session!
I will be there to chat about all things multilingual & multicultural evaluation.
Feel free to reach out anytime during the conference. I’d love to connect!
I will be there to chat about all things multilingual & multicultural evaluation.
Feel free to reach out anytime during the conference. I’d love to connect!
🚀 Introducing INCLUDE 🌍: A multilingual LLM evaluation benchmark spanning 44 languages!
Contains *newly-collected* data, prioritizing *regional knowledge*.
Setting the stage for truly global AI evaluation.
Ready to see how your model measures up?
#AI #Multilingual #LLM #NLProc
Contains *newly-collected* data, prioritizing *regional knowledge*.
Setting the stage for truly global AI evaluation.
Ready to see how your model measures up?
#AI #Multilingual #LLM #NLProc
April 23, 2025 at 1:07 AM
If you’re at @iclr-conf.bsky.social this week, come check out our spotlight poster INCLUDE during the Thursday 3:00–5:30pm session!
I will be there to chat about all things multilingual & multicultural evaluation.
Feel free to reach out anytime during the conference. I’d love to connect!
I will be there to chat about all things multilingual & multicultural evaluation.
Feel free to reach out anytime during the conference. I’d love to connect!
Using the 'right' data can hugely speed up LLM training, but how to find the best training data in the vast sea of a whole web crawl?
We propose a simple classifier-based selection, enabling multilingual LLMs 🧵
We propose a simple classifier-based selection, enabling multilingual LLMs 🧵

April 23, 2025 at 5:06 AM
Using the 'right' data can hugely speed up LLM training, but how to find the best training data in the vast sea of a whole web crawl?
We propose a simple classifier-based selection, enabling multilingual LLMs 🧵
We propose a simple classifier-based selection, enabling multilingual LLMs 🧵
Dion: A Communication-Efficient Optimizer for Large Models (inspired by PowerSGD)
arxiv.org/abs/2504.05295
arxiv.org/abs/2504.05295

Dion: A Communication-Efficient Optimizer for Large Models
Training large AI models efficiently requires distributing computation across multiple accelerators, but this often incurs significant communication overhead -- especially during gradient synchronizat...
arxiv.org
April 19, 2025 at 3:45 PM
Dion: A Communication-Efficient Optimizer for Large Models (inspired by PowerSGD)
arxiv.org/abs/2504.05295
arxiv.org/abs/2504.05295
Reposted by Martin Jaggi
Prime Intellect's INTELLECT-2
The first decentralized 32B-parameter RL training run open to join for anyone with compute — fully permissionless.
www.primeintellect.ai/blog/intelle...
The first decentralized 32B-parameter RL training run open to join for anyone with compute — fully permissionless.
www.primeintellect.ai/blog/intelle...
April 16, 2025 at 4:22 AM
Prime Intellect's INTELLECT-2
The first decentralized 32B-parameter RL training run open to join for anyone with compute — fully permissionless.
www.primeintellect.ai/blog/intelle...
The first decentralized 32B-parameter RL training run open to join for anyone with compute — fully permissionless.
www.primeintellect.ai/blog/intelle...
Anastasia @koloskova.bsky.social recently won the European @ellis.eu PhD award, for her amazing work on AI and optimization.
She will be joining University of Zurich as a professor this summer, and hiring PhD students and postdocs. You should apply to her group!
Her website: koloskova.github.io
She will be joining University of Zurich as a professor this summer, and hiring PhD students and postdocs. You should apply to her group!
Her website: koloskova.github.io
Anastasia Koloskova
Anastasia Koloskova, PhD student in Machine Learning at EPFL.
koloskova.github.io
March 8, 2025 at 1:53 PM
Anastasia @koloskova.bsky.social recently won the European @ellis.eu PhD award, for her amazing work on AI and optimization.
She will be joining University of Zurich as a professor this summer, and hiring PhD students and postdocs. You should apply to her group!
Her website: koloskova.github.io
She will be joining University of Zurich as a professor this summer, and hiring PhD students and postdocs. You should apply to her group!
Her website: koloskova.github.io
The Swiss AI Initiative has launched open calls for disruptive ideas - Democratizing large-scale AI for the benefit of society.
Send your idea by end of March 🏃♂️➡️ , and run on one of the largest public AI clusters globally. Everyone is eligible to apply!
swiss-ai.org
Send your idea by end of March 🏃♂️➡️ , and run on one of the largest public AI clusters globally. Everyone is eligible to apply!
swiss-ai.org

March 4, 2025 at 11:13 PM
The Swiss AI Initiative has launched open calls for disruptive ideas - Democratizing large-scale AI for the benefit of society.
Send your idea by end of March 🏃♂️➡️ , and run on one of the largest public AI clusters globally. Everyone is eligible to apply!
swiss-ai.org
Send your idea by end of March 🏃♂️➡️ , and run on one of the largest public AI clusters globally. Everyone is eligible to apply!
swiss-ai.org