




Martin Fenner
@mfenner.bsky.social
Founder of Front Matter, software and services for scholarly infrastructure. Launched the Rogue Scholar science blog archive in 2023.



Reposted by Martin Fenner

For #OAWeek25, all @royalsocietypublishing.org content is freely available from 20-26 October. Explore our journals below: #OpenAccess #OAWeek

We are pleased to announce that throughout Open Access Week, from 20 – 26 October, all Royal Society journal content is freely available. Explore our journals here: royalsociety.org/Journals/ #OAWeek #OAWeek25

October 23, 2025 at 1:43 PM
For #OAWeek25, all @royalsocietypublishing.org content is freely available from 20-26 October. Explore our journals below: #OpenAccess #OAWeek
Reposted by Martin Fenner

25 years Chemistry Development Kit (CDK) and going strong! :) https://doi.org/10.59350/4ce2c-fxh02 https://chem-bla-ics.linkedchemistry.info/2025/09/28/25-years-of-the-chemistry-development-kit.html
Replying to this post will make it show up in my blog.
#openscience #chemistry #opensource
Replying to this post will make it show up in my blog.
#openscience #chemistry #opensource
25 years of the Chemistry Development Kit
Twenty five years ago the Chemistry Development Kit (CDK) was founded. The Chemistry and Internet (ChemInt2000) had just ended (it ran from 23 to 26 September) and my friend and I had taken the Amtrak night train from Washington to South Bend. At that time there were two leading Java applets for chemistry, JChemPaint and Jmol. I had hacked Chemical Markup Language support into both of them, and Dan Gezelter (Jmol and openscience.org), Christoph Steinbeck (JChemPaint), and me took the opportunity of being in North America to discuss if we could use a common code base. Chris’ _compchem_ had done something similar. Peter Murray-Rust, who had also attended ChemInt2000 like me and Chris did not attend.
I do not remember exactly, but I guess we must have met on the 28th and 29th? Maybe already on Wednesday. During this meeting we discussed a common data model (yes, Jmol used the CDK data model at some point) and somewhere during the meeting we wrote down a name for the project. There was the Java Development Kit, so this could be the Chemistry Development Kit. The name stuck.
A quick post like this cannot do credit to the history of the CDK, nor of everyone involved in the past or still is. You can browse some of the history of the CDK in my blog and in Chris’ blog. It has been an amazing journey and with a small grant just behind us (with Alyanne de Haan, René van der Ploeg, and Marc Teunis from Hogeschool Utrecht), and all the awesome things ongoing (new JChemPaint, various extensions, upgraded downstream tools), the CDK is alive and kicking.
A huge congrats and thanks to everyone (and every company and organization) who contributed code to the CDK with this huge milestone. There are a few people that I want to particularly thank (see the AUTHORS file for all names): Chris, who in the late nineties made a difference with open source in chemistry, Dan, for Jmol and hosting this memorable meeting at Notre Dame University, Rajarshi Guha, who operated _CDK Nightly_ for many years, well before Travis and Google Actions, Stefan, Miguel, Gilleain, and Christian, for many years of contributions to the CDK, and John Mayfield, the current CDK release manager.
github.com
September 28, 2025 at 8:42 AM
25 years Chemistry Development Kit (CDK) and going strong! :) https://doi.org/10.59350/4ce2c-fxh02 https://chem-bla-ics.linkedchemistry.info/2025/09/28/25-years-of-the-chemistry-development-kit.html
Replying to this post will make it show up in my blog.
#openscience #chemistry #opensource
Replying to this post will make it show up in my blog.
#openscience #chemistry #opensource
Reposted by Martin Fenner

Exemplary work by NWO in adopting @crossref.bsky.social Grant IDs!
We now need broader adoption of Grant IDs by funders, publishers and individual researchers.
@barcelonadori.bsky.social
We now need broader adoption of Grant IDs by funders, publishers and individual researchers.
@barcelonadori.bsky.social

A blog post celebrating one year Crossref Grant IDs at The Dutch Research Council NWO: highlighting the enormous potential of the GLS, along the observation that publishers could step up their efforts to include funding metadata in their publications: doi.org/10.64000/dvq...

Celebrating one year of Crossref Grant IDs at NWO - Crossref
This month marks one year since the Dutch Research Council (NWO) introduced grant IDs—an important milestone in our journey toward more transparent and trackable research funding. We created over 1,60...
doi.org
September 10, 2025 at 6:46 PM
Exemplary work by NWO in adopting @crossref.bsky.social Grant IDs!
We now need broader adoption of Grant IDs by funders, publishers and individual researchers.
@barcelonadori.bsky.social
We now need broader adoption of Grant IDs by funders, publishers and individual researchers.
@barcelonadori.bsky.social

Reposted by Martin Fenner

Oops, I got a bit carried away there and forgot to include the link to our analysis and dataset 🙈
doi.org/10.59350/sch...
doi.org/10.59350/sch...
September 4, 2025 at 1:50 PM
Oops, I got a bit carried away there and forgot to include the link to our analysis and dataset 🙈
doi.org/10.59350/sch...
doi.org/10.59350/sch...


Reposted by Martin Fenner

Martin Fenner (@mfenner) has been on a mission to capture and preserve science blogs at Rogue Scholar.
https://rogue-scholar.org/
I'm very happy to announce that he's now captured my old blog, Open Access News -- more than 16.3k posts, 2002-2010 […]
https://rogue-scholar.org/
I'm very happy to announce that he's now captured my old blog, Open Access News -- more than 16.3k posts, 2002-2010 […]
Original post on fediscience.org
fediscience.org
July 29, 2025 at 6:55 PM
Martin Fenner (@mfenner) has been on a mission to capture and preserve science blogs at Rogue Scholar.
https://rogue-scholar.org/
I'm very happy to announce that he's now captured my old blog, Open Access News -- more than 16.3k posts, 2002-2010 […]
https://rogue-scholar.org/
I'm very happy to announce that he's now captured my old blog, Open Access News -- more than 16.3k posts, 2002-2010 […]
Reposted by Martin Fenner

🎉 BREAKING: InvenioRDM v13.0 has been released! Thanks to the entire open source team for their contributions to this major release. Learn all about the latest new and updated features at inveniosoftware.org/blog/2025-07... #OpenScience #OpenSource #Repositories #Zenodo
InvenioRDM v13.0 released — inveniosoftware.org
inveniosoftware.org
July 29, 2025 at 1:55 PM
🎉 BREAKING: InvenioRDM v13.0 has been released! Thanks to the entire open source team for their contributions to this major release. Learn all about the latest new and updated features at inveniosoftware.org/blog/2025-07... #OpenScience #OpenSource #Repositories #Zenodo

Reposted by Martin Fenner

Nice post from @crossref.bsky.social on DOIs and scholarly blogs www.crossref.org/blog/scholar... I am obviously a fan, thanks to @mfenner.bsky.social Rogue Scjolar project adding DOIs to my blog iphylo.blogspot.com

Scholarly blogs and their place in the research nexus - Crossref
If you are reading this blog on our website, you may have noticed that alongside each post we now list a Crossref DOI link, which was not the case a few months ago (though we have retroactively added ...
www.crossref.org
July 1, 2025 at 8:04 AM
Nice post from @crossref.bsky.social on DOIs and scholarly blogs www.crossref.org/blog/scholar... I am obviously a fan, thanks to @mfenner.bsky.social Rogue Scjolar project adding DOIs to my blog iphylo.blogspot.com
Reposted by Martin Fenner

In more tales of strange governance, Knowledge Unlatched moves BACK to not-for-profit status, living with Annual Reviews.
My hot take: this is good. But now AR should cement a constitution that ensures NFP operation and community governance cc @samuelmoore.org
www.annualreviews.org/pb-assets/as...
My hot take: this is good. But now AR should cement a constitution that ensures NFP operation and community governance cc @samuelmoore.org
www.annualreviews.org/pb-assets/as...
www.annualreviews.org
June 27, 2025 at 7:20 AM
In more tales of strange governance, Knowledge Unlatched moves BACK to not-for-profit status, living with Annual Reviews.
My hot take: this is good. But now AR should cement a constitution that ensures NFP operation and community governance cc @samuelmoore.org
www.annualreviews.org/pb-assets/as...
My hot take: this is good. But now AR should cement a constitution that ensures NFP operation and community governance cc @samuelmoore.org
www.annualreviews.org/pb-assets/as...





Reposted by Martin Fenner

As part of the Infra Wiss Blogs project, we will host the webinar “Blog archiving with Rogue Scholar using the example of WordPress Blogs” on June 11.
Registration: hu.berlin/infrawissblogs
More information can be found here: hu.berlin/infrawissblo...
@pampel.bsky.social @mfenner.bsky.social
Registration: hu.berlin/infrawissblogs
More information can be found here: hu.berlin/infrawissblo...
@pampel.bsky.social @mfenner.bsky.social
May 19, 2025 at 4:52 PM
As part of the Infra Wiss Blogs project, we will host the webinar “Blog archiving with Rogue Scholar using the example of WordPress Blogs” on June 11.
Registration: hu.berlin/infrawissblogs
More information can be found here: hu.berlin/infrawissblo...
@pampel.bsky.social @mfenner.bsky.social
Registration: hu.berlin/infrawissblogs
More information can be found here: hu.berlin/infrawissblo...
@pampel.bsky.social @mfenner.bsky.social

Reposted by Martin Fenner

This is so exciting! The German National Library of Medicine @zbmed.bsky.social just had its first open meeting on the plan for an open & independent PubMed safety net. Here's my write-up @plos.org on the meeting & how institutions & others can help absolutelymaybe.plos.org/2025/05/14/g...
#MedLibs
#MedLibs

Germany's Plan for an Open and Independent PubMed Safety Net - Absolutely Maybe
A few months ago, I wrote about reasons to be concerned about the reliability of PubMed under the new regime at the…
absolutelymaybe.plos.org
May 14, 2025 at 3:41 PM
This is so exciting! The German National Library of Medicine @zbmed.bsky.social just had its first open meeting on the plan for an open & independent PubMed safety net. Here's my write-up @plos.org on the meeting & how institutions & others can help absolutelymaybe.plos.org/2025/05/14/g...
#MedLibs
#MedLibs
Reposted by Martin Fenner

How does open science hold up in times of crisis?
@jeroenbosman.bsky.social & @jeroenson.bsky.social explore this in a sharp post on Upstream: doi.org/10.54900/pqr...
They outline threats, map types of resilience, and remind us: open science isn’t just at risk…it’s also part of the solution.
@jeroenbosman.bsky.social & @jeroenson.bsky.social explore this in a sharp post on Upstream: doi.org/10.54900/pqr...
They outline threats, map types of resilience, and remind us: open science isn’t just at risk…it’s also part of the solution.
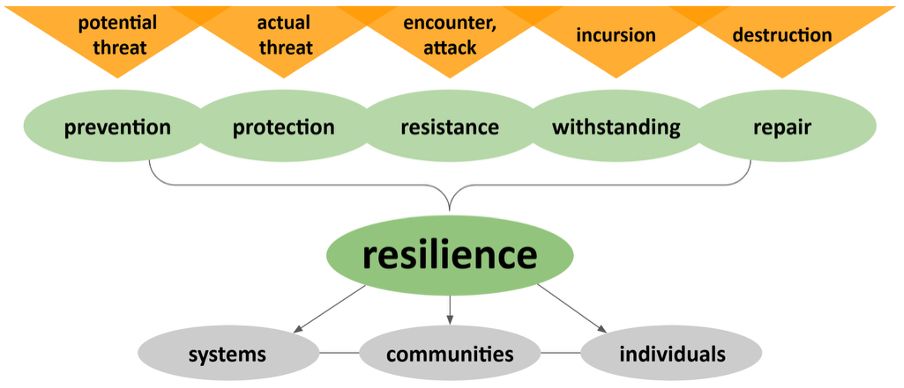
The resilience of open science in times of crisis
The increasingly hostile attitude of the new U.S. government towards science and academia leaves many of us deeply concerned— if not outright alarmed. In an effort to better understand the unfolding s...
doi.org
May 13, 2025 at 5:20 PM
How does open science hold up in times of crisis?
@jeroenbosman.bsky.social & @jeroenson.bsky.social explore this in a sharp post on Upstream: doi.org/10.54900/pqr...
They outline threats, map types of resilience, and remind us: open science isn’t just at risk…it’s also part of the solution.
@jeroenbosman.bsky.social & @jeroenson.bsky.social explore this in a sharp post on Upstream: doi.org/10.54900/pqr...
They outline threats, map types of resilience, and remind us: open science isn’t just at risk…it’s also part of the solution.
Reposted by Martin Fenner

Preprint peer evaluation already happens here. In posts and in replies.
But it’s disconnected from the scholarly record and how science gets credited.
With support from NLnet, Sciety is working to recognise the crucial act of community curation
📝 blog.sciety.org/sciety-secur...
But it’s disconnected from the scholarly record and how science gets credited.
With support from NLnet, Sciety is working to recognise the crucial act of community curation
📝 blog.sciety.org/sciety-secur...

Sciety secures funding from NLNet Foundation to help build discourse around preprints
At Sciety we're pioneering a new layer of open scholarly communication, one that captures informal conversations around preprints and makes them discoverable and reusable. Sciety has secured new…
blog.sciety.org
May 13, 2025 at 3:00 PM
Preprint peer evaluation already happens here. In posts and in replies.
But it’s disconnected from the scholarly record and how science gets credited.
With support from NLnet, Sciety is working to recognise the crucial act of community curation
📝 blog.sciety.org/sciety-secur...
But it’s disconnected from the scholarly record and how science gets credited.
With support from NLnet, Sciety is working to recognise the crucial act of community curation
📝 blog.sciety.org/sciety-secur...
Reposted by Martin Fenner
There are very few artefacts that can't or shouldn't be cited.
The one that annoys me most is being told I can't cite an unpublished PhD thesis. These are often really good!
With Wikipedia, you should probably cite the original source.
The one that annoys me most is being told I can't cite an unpublished PhD thesis. These are often really good!
With Wikipedia, you should probably cite the original source.

So the tired "preprints shouldn't be cited because they're not peer reviewed" meme is back. Reminder these frequently cited items aren't peer reviewed either:
Editorials
Books
Reviews [some not all]
News reports
Data
Code
Websites
Social media posts
Citations are just links...intent varies 1/2
Editorials
Books
Reviews [some not all]
News reports
Data
Code
Websites
Social media posts
Citations are just links...intent varies 1/2
May 13, 2025 at 12:13 PM
There are very few artefacts that can't or shouldn't be cited.
The one that annoys me most is being told I can't cite an unpublished PhD thesis. These are often really good!
With Wikipedia, you should probably cite the original source.
The one that annoys me most is being told I can't cite an unpublished PhD thesis. These are often really good!
With Wikipedia, you should probably cite the original source.