



METR
@metr.org
METR is a research nonprofit that builds evaluations to empirically test AI systems for capabilities that could threaten catastrophic harm to society.
We estimate that Claude Opus 4.1 has a 50%-time-horizon of around 1 hr 45 min (95% confidence interval of 50 to 195 minutes) on our agentic multi-step software engineering tasks. This estimate is lower than the current highest time-horizon point estimate of around 2 hr 15 min.

September 2, 2025 at 4:38 PM
We estimate that Claude Opus 4.1 has a 50%-time-horizon of around 1 hr 45 min (95% confidence interval of 50 to 195 minutes) on our agentic multi-step software engineering tasks. This estimate is lower than the current highest time-horizon point estimate of around 2 hr 15 min.
We tested how autonomous AI agents perform on real software tasks from our recent developer productivity RCT.
We found a gap between algorithmic scoring and real-world usability that may help explain why AI benchmarks feel disconnected from reality.
We found a gap between algorithmic scoring and real-world usability that may help explain why AI benchmarks feel disconnected from reality.

August 13, 2025 at 10:38 PM
We tested how autonomous AI agents perform on real software tasks from our recent developer productivity RCT.
We found a gap between algorithmic scoring and real-world usability that may help explain why AI benchmarks feel disconnected from reality.
We found a gap between algorithmic scoring and real-world usability that may help explain why AI benchmarks feel disconnected from reality.
Before publishing our recent developer productivity RCT, we thought hard about how to accurately and clearly communicate our results. In a new blog post, we outline some of our key considerations regarding scientific integrity and communication.

August 12, 2025 at 6:40 PM
Before publishing our recent developer productivity RCT, we thought hard about how to accurately and clearly communicate our results. In a new blog post, we outline some of our key considerations regarding scientific integrity and communication.
Prior work has found that Chain of Thought (CoT) can be unfaithful. Should we then ignore what it says?
In new research, we find that the CoT is informative about LLM cognition as long as the cognition is complex enough that it can’t be performed in a single forward pass.
In new research, we find that the CoT is informative about LLM cognition as long as the cognition is complex enough that it can’t be performed in a single forward pass.

August 11, 2025 at 12:22 AM
Prior work has found that Chain of Thought (CoT) can be unfaithful. Should we then ignore what it says?
In new research, we find that the CoT is informative about LLM cognition as long as the cognition is complex enough that it can’t be performed in a single forward pass.
In new research, we find that the CoT is informative about LLM cognition as long as the cognition is complex enough that it can’t be performed in a single forward pass.
In a new report, we evaluate whether GPT-5 poses significant catastrophic risks via AI R&D acceleration, rogue replication, or sabotage of AI labs.
We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.
We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.

August 8, 2025 at 1:20 AM
In a new report, we evaluate whether GPT-5 poses significant catastrophic risks via AI R&D acceleration, rogue replication, or sabotage of AI labs.
We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.
We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.
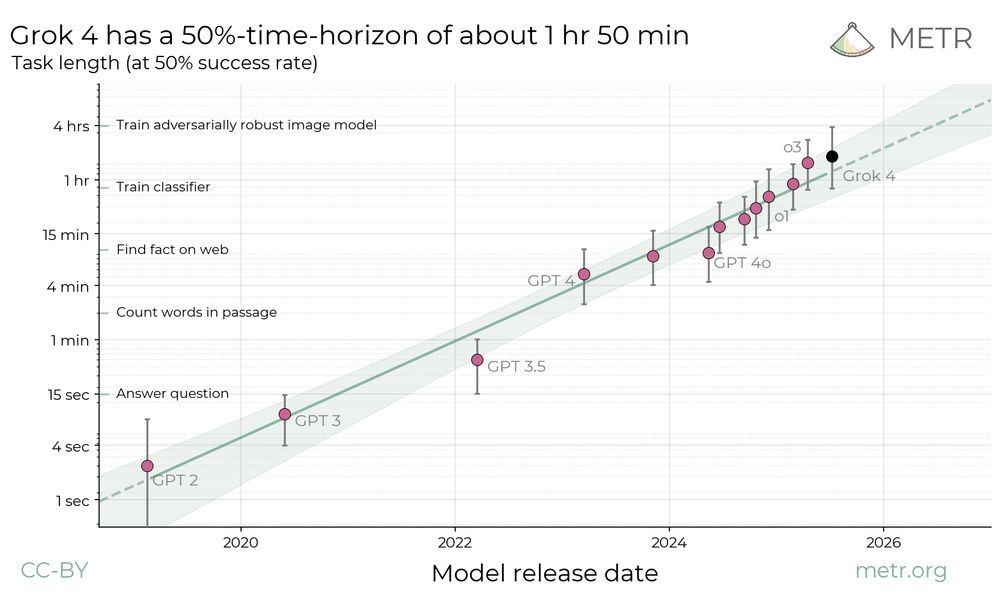
We found that Grok 4’s 50%-time-horizon on our agentic multi-step software engineering tasks is about 1hr 50min (with a 95% CI of 48min to 3hr 52min) compared to o3 (previous SOTA) at about 1hr 30min. However, Grok 4’s time horizon is below SOTA at higher success rate thresholds.
July 31, 2025 at 2:12 AM
We found that Grok 4’s 50%-time-horizon on our agentic multi-step software engineering tasks is about 1hr 50min (with a 95% CI of 48min to 3hr 52min) compared to o3 (previous SOTA) at about 1hr 30min. However, Grok 4’s time horizon is below SOTA at higher success rate thresholds.
We have open-sourced anonymized data and core analysis code for our developer productivity RCT.
The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.
The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.

July 30, 2025 at 8:10 PM
We have open-sourced anonymized data and core analysis code for our developer productivity RCT.
The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.
The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.
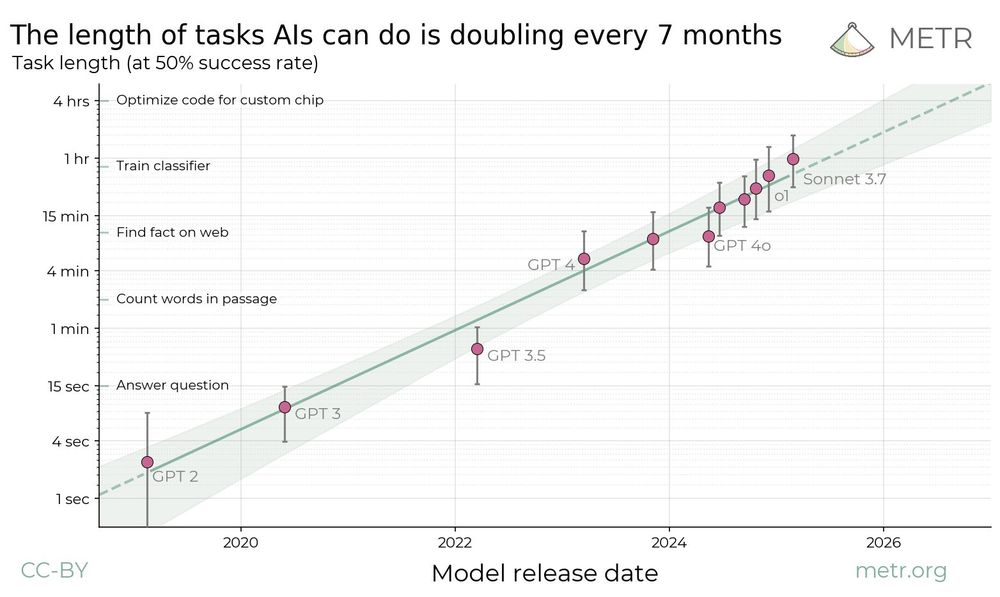
METR previously estimated that the time horizon of AI agents on software tasks is doubling every 7 months.
We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.
We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.

July 14, 2025 at 6:22 PM
METR previously estimated that the time horizon of AI agents on software tasks is doubling every 7 months.
We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.
We have now analyzed 9 other benchmarks for scientific reasoning, math, robotics, computer use, and self-driving; we observe generally similar rates of improvement.
Reposted by METR

METR a few months ago had two projects going in parallel: a project experimenting with AI researcher interviews to track degree of AI R&D acceleration/delegation, and this project.
When the results started coming back from this project, we put the survey-only project on ice.
When the results started coming back from this project, we put the survey-only project on ice.
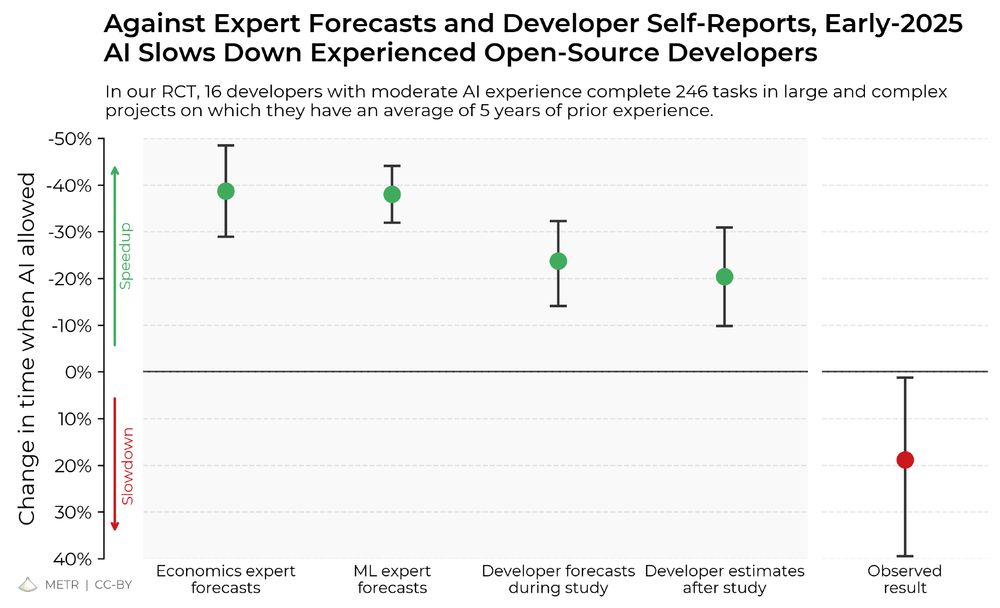
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
July 11, 2025 at 12:22 AM
METR a few months ago had two projects going in parallel: a project experimenting with AI researcher interviews to track degree of AI R&D acceleration/delegation, and this project.
When the results started coming back from this project, we put the survey-only project on ice.
When the results started coming back from this project, we put the survey-only project on ice.
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
July 10, 2025 at 7:47 PM
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
In measurements using our set of multi-step software and reasoning tasks, Claude 4 Opus and Sonnet reach 50%-time-horizon point estimates of about 80 and 65 minutes, respectively.

July 1, 2025 at 10:33 PM
In measurements using our set of multi-step software and reasoning tasks, Claude 4 Opus and Sonnet reach 50%-time-horizon point estimates of about 80 and 65 minutes, respectively.
At METR, we’ve seen increasingly sophisticated examples of “reward hacking” on our tasks: models trying to subvert or exploit the environment or scoring code to obtain a higher score. In a new post, we discuss this phenomenon and share some especially crafty instances we’ve seen.

June 13, 2025 at 12:05 AM
At METR, we’ve seen increasingly sophisticated examples of “reward hacking” on our tasks: models trying to subvert or exploit the environment or scoring code to obtain a higher score. In a new post, we discuss this phenomenon and share some especially crafty instances we’ve seen.
When will AI systems be able to carry out long projects independently?
In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
March 19, 2025 at 5:43 PM
When will AI systems be able to carry out long projects independently?
In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.
How close are current AI agents to automating AI research itself? Our new ML research engineering benchmark (RE-Bench) addresses this question by directly comparing frontier models such as Claude 3.5 Sonnet and o1-preview with 50+ human experts on 7 challenging research engineering tasks.

November 25, 2024 at 7:42 PM
How close are current AI agents to automating AI research itself? Our new ML research engineering benchmark (RE-Bench) addresses this question by directly comparing frontier models such as Claude 3.5 Sonnet and o1-preview with 50+ human experts on 7 challenging research engineering tasks.