



Mark Dredze
@mdredze.bsky.social
John C Malone Professor at Johns Hopkins Computer Science, Center for Language and Speech Processing, Malone Center for Engineering in Healthcare.
Parttime: Bloomberg LP #nlproc
Parttime: Bloomberg LP #nlproc
Examining the generated QA pairs, you can really see the difference. Our generations (bottom) look harder and more interesting.
Try our strategy for your synthetic generation task? Check out our paper, being presented at #ML4H2024 .
arxiv.org/abs/2412.04573
Try our strategy for your synthetic generation task? Check out our paper, being presented at #ML4H2024 .
arxiv.org/abs/2412.04573

December 22, 2024 at 4:01 PM
Examining the generated QA pairs, you can really see the difference. Our generations (bottom) look harder and more interesting.
Try our strategy for your synthetic generation task? Check out our paper, being presented at #ML4H2024 .
arxiv.org/abs/2412.04573
Try our strategy for your synthetic generation task? Check out our paper, being presented at #ML4H2024 .
arxiv.org/abs/2412.04573
Training a Clinical QA system on our data gives big improvements, whether we generate data from Llama or GPT-4o. These improvements are both in F1 and any overlap between the extracted and true answers.

December 22, 2024 at 4:01 PM
Training a Clinical QA system on our data gives big improvements, whether we generate data from Llama or GPT-4o. These improvements are both in F1 and any overlap between the extracted and true answers.
The generated pair has a lot of advantages: it doesn't use the same language as the report, it includes harder questions, and the answers are sometimes not in the report (unanswerable questions.) The result? Harder, more diverse and more realistic QA pairs.
December 22, 2024 at 4:01 PM
The generated pair has a lot of advantages: it doesn't use the same language as the report, it includes harder questions, and the answers are sometimes not in the report (unanswerable questions.) The result? Harder, more diverse and more realistic QA pairs.
Second, we use a summarize-then-generate strategy. The LLM first summarizes a given clinical record in a structured format. The summary keeps the key points but loses the details, such as specific terminology and content. We then use the summary to generate a new QA pair.
December 22, 2024 at 4:01 PM
Second, we use a summarize-then-generate strategy. The LLM first summarizes a given clinical record in a structured format. The summary keeps the key points but loses the details, such as specific terminology and content. We then use the summary to generate a new QA pair.
We explore two strategies. First, we craft instructions to encourage QA diversity. We formulate these as constraints on the answers to the questions. It helps, but we need more.
December 22, 2024 at 4:01 PM
We explore two strategies. First, we craft instructions to encourage QA diversity. We formulate these as constraints on the answers to the questions. It helps, but we need more.
We can ask an LLM to write QA pairs, but they turn out to be too easy and repetitive. They don't come close to what you can get with real data. We need more diverse data! Typical methods (e.g. annealing) don't work. What can we do?
December 22, 2024 at 4:01 PM
We can ask an LLM to write QA pairs, but they turn out to be too easy and repetitive. They don't come close to what you can get with real data. We need more diverse data! Typical methods (e.g. annealing) don't work. What can we do?
Takeaways: If you can fine-tune a model on a specific clinical domain, that's great. If you can't, you should probably use models that are better overall, even if they aren't trained on clinical data.
Many more details in the paper!
arxiv.org/abs/2412.05845
Many more details in the paper!
arxiv.org/abs/2412.05845

Are Clinical T5 Models Better for Clinical Text?
Large language models with a transformer-based encoder/decoder architecture, such as T5, have become standard platforms for supervised tasks. To bring these technologies to the clinical domain, recent...
arxiv.org
December 22, 2024 at 3:59 PM
Takeaways: If you can fine-tune a model on a specific clinical domain, that's great. If you can't, you should probably use models that are better overall, even if they aren't trained on clinical data.
Many more details in the paper!
arxiv.org/abs/2412.05845
Many more details in the paper!
arxiv.org/abs/2412.05845
It turns out that when you have just a little supervised data, the models trained on more data and tasks, even when out of domain, do BETTER on the new clinical domain.
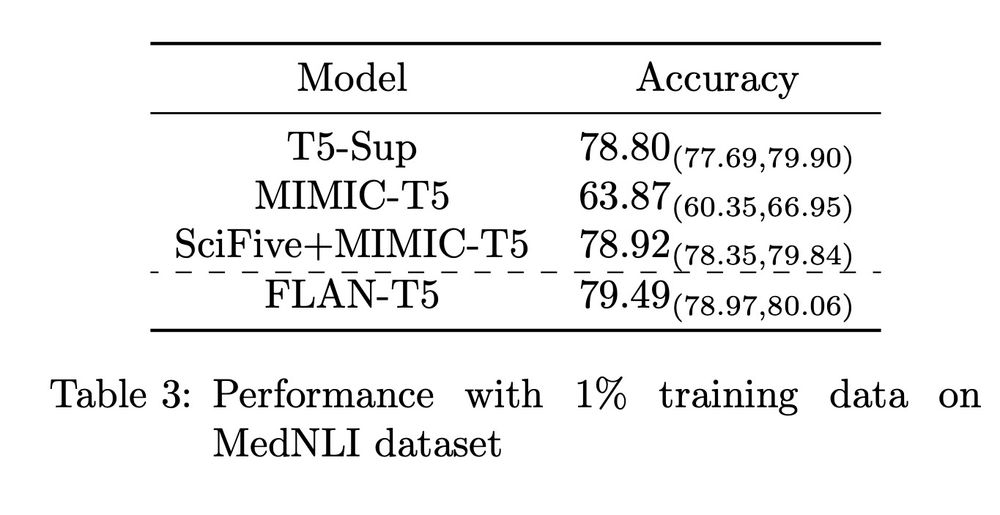
December 22, 2024 at 3:59 PM
It turns out that when you have just a little supervised data, the models trained on more data and tasks, even when out of domain, do BETTER on the new clinical domain.