



Matthijs Pals
@matthijspals.bsky.social
Using deep learning to study neural dynamics
@mackelab.bsky.social
@mackelab.bsky.social
But not all of the 2^N regions do! Each neuron partitions the R-dim subspace of dynamics with a hyperplane (here a line). N hyperplanes can partition R-dim space into at most O(N^R) regions. We can thus reduce our search space by only solving for fixed points in these!
6/7
6/7
December 11, 2024 at 1:32 AM
But not all of the 2^N regions do! Each neuron partitions the R-dim subspace of dynamics with a hyperplane (here a line). N hyperplanes can partition R-dim space into at most O(N^R) regions. We can thus reduce our search space by only solving for fixed points in these!
6/7
6/7
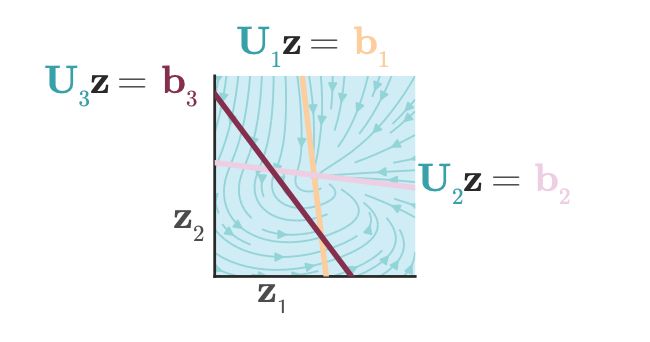
Some of the the 2^N regions with linear dynamics intersect the subspace in which the dynamics unfold (span U), as the one here: 5/7
December 11, 2024 at 1:32 AM
Some of the the 2^N regions with linear dynamics intersect the subspace in which the dynamics unfold (span U), as the one here: 5/7
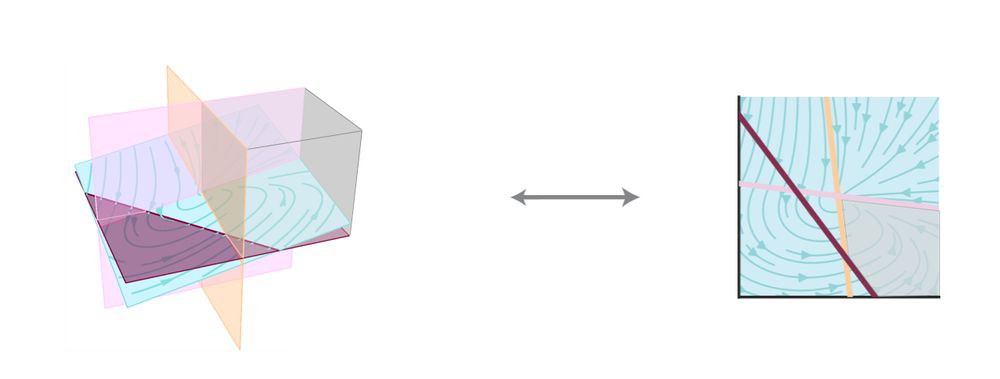
In low-rank RNNs dynamics are constrained to the linear subspace spanned by the left singular vectors U of the recurrent weight matrix (e.g., work from Ostojic' lab) 4/7

December 11, 2024 at 1:32 AM
In low-rank RNNs dynamics are constrained to the linear subspace spanned by the left singular vectors U of the recurrent weight matrix (e.g., work from Ostojic' lab) 4/7
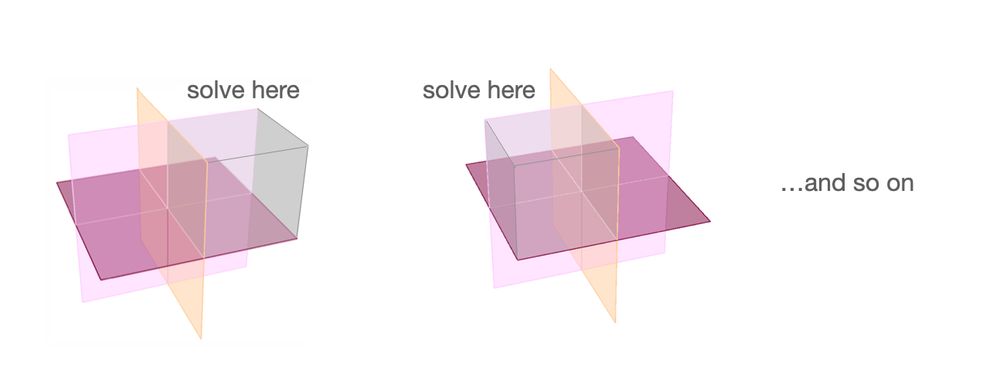
We can go through all those regions, one by one, and solve the corresponding linear system equations (see e.g., work from Curto and Durstwitz' labs) 2/7
December 11, 2024 at 1:32 AM
We can go through all those regions, one by one, and solve the corresponding linear system equations (see e.g., work from Curto and Durstwitz' labs) 2/7
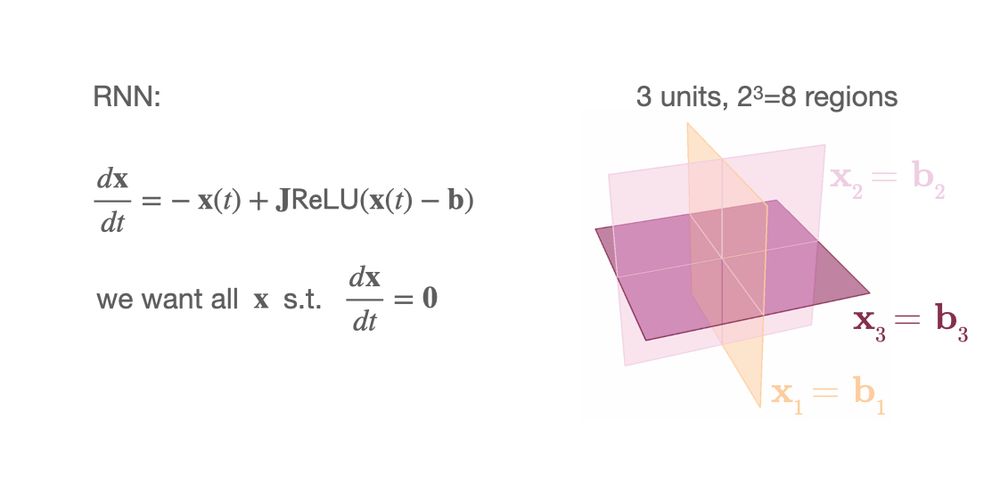
How to find all fixed points in piece-wise linear recurrent neural networks (RNNs)?
A short thread 🧵
In RNNs with N units with ReLU(x-b) activations the phase space is partioned in 2^N regions by hyperplanes at x=b 1/7
A short thread 🧵
In RNNs with N units with ReLU(x-b) activations the phase space is partioned in 2^N regions by hyperplanes at x=b 1/7
December 11, 2024 at 1:32 AM
How to find all fixed points in piece-wise linear recurrent neural networks (RNNs)?
A short thread 🧵
In RNNs with N units with ReLU(x-b) activations the phase space is partioned in 2^N regions by hyperplanes at x=b 1/7
A short thread 🧵
In RNNs with N units with ReLU(x-b) activations the phase space is partioned in 2^N regions by hyperplanes at x=b 1/7