



Marcin Junczys-Dowmunt (Marian NMT)
@marian-nmt.bsky.social
NLP. NMT. Main author of Marian NMT. Research Scientist at Microsoft Translator.
https://marian-nmt.github.io
https://marian-nmt.github.io
Pinned
This place needs bookmarks.
Still no bookmarks?
February 5, 2025 at 7:03 AM
Still no bookmarks?
Hi, the Microsoft Translator research team is looking for an intern for the summer. If you a PhD student in Machine Translation, Natural Language Processing, or related, check it out: aka.ms/mtintern
Search Jobs | Microsoft Careers
aka.ms
January 28, 2025 at 5:55 PM
Hi, the Microsoft Translator research team is looking for an intern for the summer. If you a PhD student in Machine Translation, Natural Language Processing, or related, check it out: aka.ms/mtintern
Reposted by Marcin Junczys-Dowmunt (Marian NMT)

Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!

December 16, 2024 at 9:42 PM
Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the technique behind its success: scaling test-time compute
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
By giving models more "time to think," Llama 1B outperforms Llama 8B in math—beating a model 8x its size. The full recipe is open-source!
Rant: Apparently every vector-based sentence alignment tool insists on having an unusable file-based API.
December 16, 2024 at 9:48 PM
Rant: Apparently every vector-based sentence alignment tool insists on having an unusable file-based API.
Reposted by Marcin Junczys-Dowmunt (Marian NMT)

Wrote up some notes on Microsoft's new Phi-4 LLM. They trained it on a LOT of synthetic data, and the details of how and why they did that are really interesting.
https://simonwillison.net/2024/Dec/15/phi-4-technical-report/
https://simonwillison.net/2024/Dec/15/phi-4-technical-report/
Phi-4 Technical Report
Phi-4 is the latest LLM from Microsoft Research. It has 14B parameters and claims to be a big leap forward in the overall Phi series. From [Introducing Phi-4: Microsoft’s Newest …
simonwillison.net
December 16, 2024 at 12:21 AM
Wrote up some notes on Microsoft's new Phi-4 LLM. They trained it on a LOT of synthetic data, and the details of how and why they did that are really interesting.
https://simonwillison.net/2024/Dec/15/phi-4-technical-report/
https://simonwillison.net/2024/Dec/15/phi-4-technical-report/
Reposted by Marcin Junczys-Dowmunt (Marian NMT)

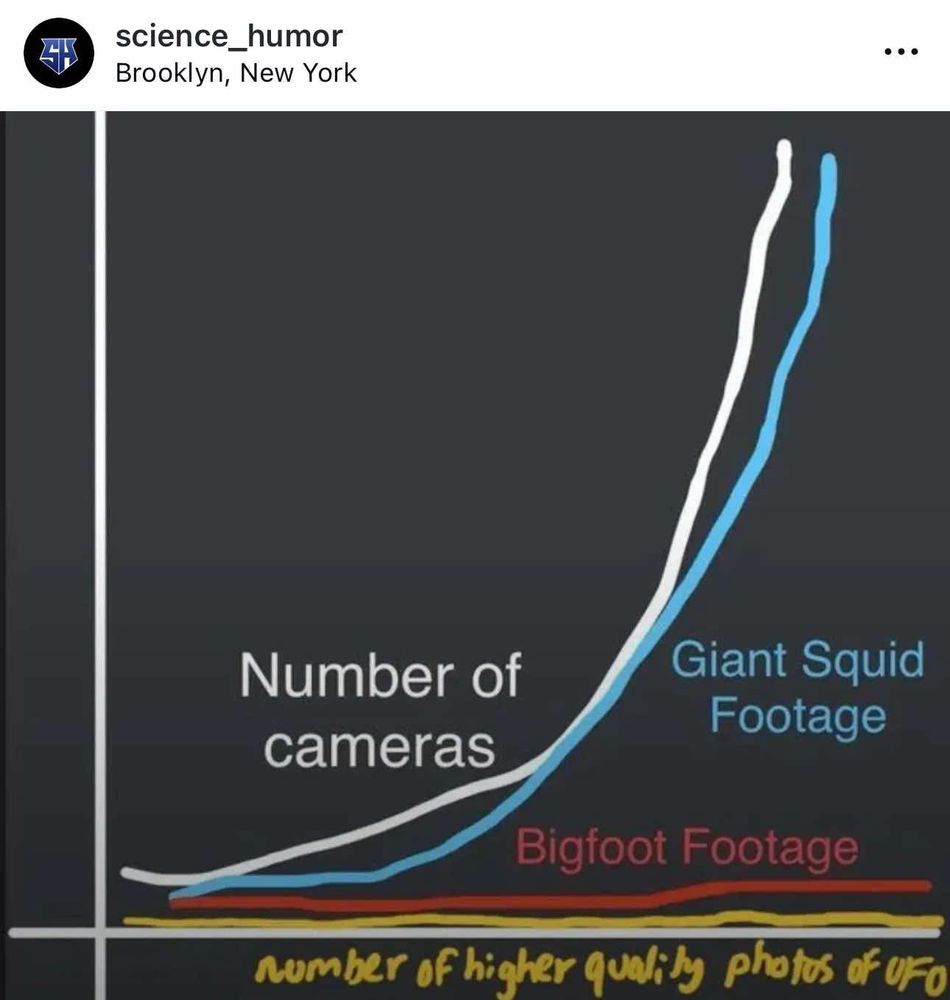
It's messier, but I think this one slaps the point home a bit stronger by adding the giant squid footage. I think unique weather, like lighting sprites, would make the point just as well.
December 14, 2024 at 8:25 PM
It's messier, but I think this one slaps the point home a bit stronger by adding the giant squid footage. I think unique weather, like lighting sprites, would make the point just as well.
Reposted by Marcin Junczys-Dowmunt (Marian NMT)

the anthropomorphizing in this LLM scheming paper is through the roof and the interpretations are wild, but still a cute set of experiments and a fun skim, showing some interesting behaviors.
arxiv.org/abs/2412.04984
arxiv.org/abs/2412.04984

Frontier Models are Capable of In-context Scheming
Frontier models are increasingly trained and deployed as autonomous agent. One safety concern is that AI agents might covertly pursue misaligned goals, hiding their true capabilities and objectives - ...
arxiv.org
December 13, 2024 at 9:36 AM
the anthropomorphizing in this LLM scheming paper is through the roof and the interpretations are wild, but still a cute set of experiments and a fun skim, showing some interesting behaviors.
arxiv.org/abs/2412.04984
arxiv.org/abs/2412.04984
Reposted by Marcin Junczys-Dowmunt (Marian NMT)

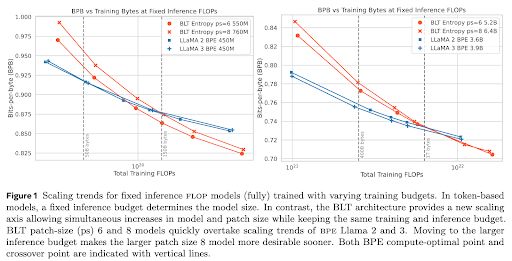
🚀 Introducing the Byte Latent Transformer (BLT) – A LLM architecture that scales better than Llama 3 using patches instead of tokens 🤯
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
December 13, 2024 at 4:53 PM
🚀 Introducing the Byte Latent Transformer (BLT) – A LLM architecture that scales better than Llama 3 using patches instead of tokens 🤯
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
So... no edit button, huh?
December 13, 2024 at 11:33 PM
So... no edit button, huh?
This place needs bookmarks.
December 13, 2024 at 6:28 PM
This place needs bookmarks.