



Marcus Klasson
@marcusklasson.bsky.social
Paper, videos, and code (nerfstudio) is available!
📄 arxiv.org/abs/2411.19756
🎈 aaltoml.github.io/desplat/
Big ups to Yihao Wang, @maturk.bsky.social, Shuzhe Wang, Juho Kannala, and @arnosolin.bsky.social for making this possible during my time at @aalto.fi 💙🤍
#AaltoUniversity #CVPR2025
[8/8]
📄 arxiv.org/abs/2411.19756
🎈 aaltoml.github.io/desplat/
Big ups to Yihao Wang, @maturk.bsky.social, Shuzhe Wang, Juho Kannala, and @arnosolin.bsky.social for making this possible during my time at @aalto.fi 💙🤍
#AaltoUniversity #CVPR2025
[8/8]

DeSplat: Decomposed Gaussian Splatting for Distractor-Free Rendering
Gaussian splatting enables fast novel view synthesis in static 3D environments. However, reconstructing real-world environments remains challenging as distractors or occluders break the multi-view con...
arxiv.org
June 13, 2025 at 8:04 AM
Paper, videos, and code (nerfstudio) is available!
📄 arxiv.org/abs/2411.19756
🎈 aaltoml.github.io/desplat/
Big ups to Yihao Wang, @maturk.bsky.social, Shuzhe Wang, Juho Kannala, and @arnosolin.bsky.social for making this possible during my time at @aalto.fi 💙🤍
#AaltoUniversity #CVPR2025
[8/8]
📄 arxiv.org/abs/2411.19756
🎈 aaltoml.github.io/desplat/
Big ups to Yihao Wang, @maturk.bsky.social, Shuzhe Wang, Juho Kannala, and @arnosolin.bsky.social for making this possible during my time at @aalto.fi 💙🤍
#AaltoUniversity #CVPR2025
[8/8]
DeSplat has the same FPS and training time as vanilla 3DGS with some additional overhead for storing distractor Gaussians. Extend with MLPs or other models can also be done. Altering DeSplat to video remains to be explored, as distractors barely moving across images can be mistaken as static. [7/8]
June 13, 2025 at 8:01 AM
DeSplat has the same FPS and training time as vanilla 3DGS with some additional overhead for storing distractor Gaussians. Extend with MLPs or other models can also be done. Altering DeSplat to video remains to be explored, as distractors barely moving across images can be mistaken as static. [7/8]
This decomposed splatting (DeSplat) approach explicitly separates distractors from static parts. Earlier methods (e.g. SpotlessSplats, WildGaussians) use loss masking of detected distractors to avoid overfitting, while DeSplat instead jointly reconstructs distractor elements.
[6/8]
[6/8]

June 13, 2025 at 7:59 AM
This decomposed splatting (DeSplat) approach explicitly separates distractors from static parts. Earlier methods (e.g. SpotlessSplats, WildGaussians) use loss masking of detected distractors to avoid overfitting, while DeSplat instead jointly reconstructs distractor elements.
[6/8]
[6/8]
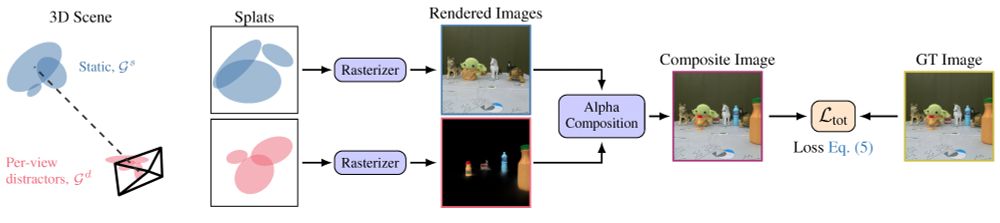
Knowing how 3DGS treats distractors, we initialize a set of Gaussians close to every camera view for reconstructing view-specific distractors. The Gaussians initialized from the point cloud should reconstruct static stuff. These separately rendered images are alpha-blended during training.
[5/8]
[5/8]
June 13, 2025 at 7:58 AM
Knowing how 3DGS treats distractors, we initialize a set of Gaussians close to every camera view for reconstructing view-specific distractors. The Gaussians initialized from the point cloud should reconstruct static stuff. These separately rendered images are alpha-blended during training.
[5/8]
[5/8]
In a viewer, you can see that these spurious artefacts are thin and are located close to the camera view. For the scene-overfitting approach in 3DGS, this makes sense since an object only appearing in one view must be located as close to the camera such that no other camera view can see it.
[4/8]
[4/8]
June 13, 2025 at 7:56 AM
In a viewer, you can see that these spurious artefacts are thin and are located close to the camera view. For the scene-overfitting approach in 3DGS, this makes sense since an object only appearing in one view must be located as close to the camera such that no other camera view can see it.
[4/8]
[4/8]
This BabyYoda scene from RobustNeRF is similar to a crowdsourced scenario, where a set of static toys appear together with inconsistently-placed toys between the frames.
Vanilla 3DGS is quite robust here, but some views end up being rendered with spurious artefacts (right image).
[3/8]
Vanilla 3DGS is quite robust here, but some views end up being rendered with spurious artefacts (right image).
[3/8]

June 13, 2025 at 7:55 AM
This BabyYoda scene from RobustNeRF is similar to a crowdsourced scenario, where a set of static toys appear together with inconsistently-placed toys between the frames.
Vanilla 3DGS is quite robust here, but some views end up being rendered with spurious artefacts (right image).
[3/8]
Vanilla 3DGS is quite robust here, but some views end up being rendered with spurious artefacts (right image).
[3/8]
Our goal is to learn a scene representation from images that include non-static objects we refer to as distractors. An example is crowdsourced images where different people appear at different locations in the scene, which creates multi-view inconsistencies between the frames.
[2/8]
[2/8]
June 13, 2025 at 7:53 AM
Our goal is to learn a scene representation from images that include non-static objects we refer to as distractors. An example is crowdsourced images where different people appear at different locations in the scene, which creates multi-view inconsistencies between the frames.
[2/8]
[2/8]