



Marc Brooker
@marcbrooker.bsky.social
Serverless, databases, and serverless databases at AWS. Views my own.
Check out my blog: https://brooker.co.za/blog/
Check out my blog: https://brooker.co.za/blog/
Finally got to fixing the "related posts" feature in my blog. The Amazon Titan embedding model on Bedrock, plus cosine similarity, does a nice job:

July 12, 2025 at 12:55 AM
Finally got to fixing the "related posts" feature in my blog. The Amazon Titan embedding model on Bedrock, plus cosine similarity, does a nice job:
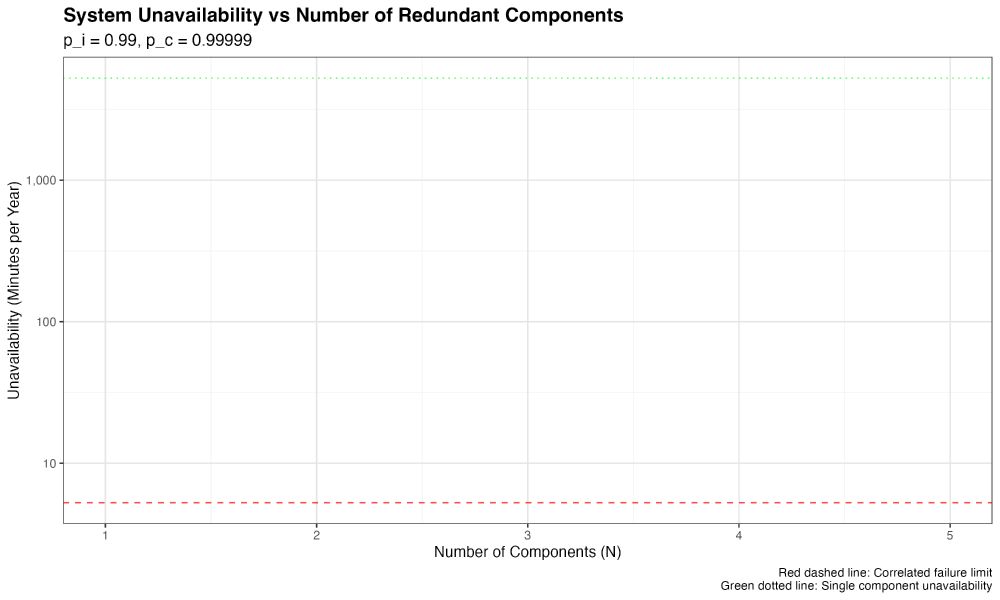
Here's the answer.
On the left, we see the great "exponential benefit at linear cost" impact of redundancy. But that quickly tapers off as the single point of failure dominates.
What can this teach us about building good HA architectures?
On the left, we see the great "exponential benefit at linear cost" impact of redundancy. But that quickly tapers off as the single point of failure dominates.
What can this teach us about building good HA architectures?

June 19, 2025 at 7:34 PM
Here's the answer.
On the left, we see the great "exponential benefit at linear cost" impact of redundancy. But that quickly tapers off as the single point of failure dominates.
What can this teach us about building good HA architectures?
On the left, we see the great "exponential benefit at linear cost" impact of redundancy. But that quickly tapers off as the single point of failure dominates.
What can this teach us about building good HA architectures?
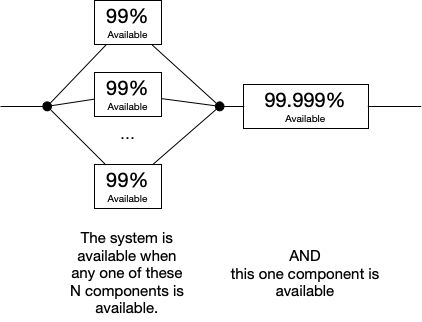
Availability intuition quiz!
I have an architecture with N redundant components, each available 99% of time time, and one non-redundant component available 99.999% of the time.
Sketch, on the provided axes, the end-to-end availability curve versus N.
I have an architecture with N redundant components, each available 99% of time time, and one non-redundant component available 99.999% of the time.
Sketch, on the provided axes, the end-to-end availability curve versus N.
June 17, 2025 at 5:25 PM
Availability intuition quiz!
I have an architecture with N redundant components, each available 99% of time time, and one non-redundant component available 99.999% of the time.
Sketch, on the provided axes, the end-to-end availability curve versus N.
I have an architecture with N redundant components, each available 99% of time time, and one non-redundant component available 99.999% of the time.
Sketch, on the provided axes, the end-to-end availability curve versus N.
Aurora DSQL is now Generally Available! I couldn't be more proud of the team that brought DSQL to life, and excited about how our customers are going to build on it. 🧵

May 27, 2025 at 7:40 PM
Aurora DSQL is now Generally Available! I couldn't be more proud of the team that brought DSQL to life, and excited about how our customers are going to build on it. 🧵
Last week I had the privilege to give a keynote at the International Conference on Performance Evaluation (ICPE'25). It wasn't recorded, so I captured the key points as a blog post: brooker.co.za/blog/2025/05...

May 21, 2025 at 4:29 PM
Last week I had the privilege to give a keynote at the International Conference on Performance Evaluation (ICPE'25). It wasn't recorded, so I captured the key points as a blog post: brooker.co.za/blog/2025/05...
Read-only transactions are much simpler, where the use of physical clocks and MVCC mean that no validation step is required. Read-only also requires no persistence step.

April 18, 2025 at 4:54 PM
Read-only transactions are much simpler, where the use of physical clocks and MVCC mean that no validation step is required. Read-only also requires no persistence step.
I enjoyed @alexmillerdb.bsky.social's "Decomposing Transaction Systems" blog so much I had to write up how I'd decompose Aurora DSQL in a new blog post: brooker.co.za/blog/2025/04...

April 18, 2025 at 4:54 PM
I enjoyed @alexmillerdb.bsky.social's "Decomposing Transaction Systems" blog so much I had to write up how I'd decompose Aurora DSQL in a new blog post: brooker.co.za/blog/2025/04...
I generally like Mitutoyo products, but this travel comb sucks.

April 9, 2025 at 11:12 PM
I generally like Mitutoyo products, but this travel comb sucks.
It's widely known that sharing a queue across multiple servers, rather than queue-per-server, often helps reduce latency and improve utilization. But when is one queue better? In my new blog post, I look at one case: different classes of work. Read it here: brooker.co.za/blog/2025/03...

March 26, 2025 at 4:34 PM
It's widely known that sharing a queue across multiple servers, rather than queue-per-server, often helps reduce latency and improve utilization. But when is one queue better? In my new blog post, I look at one case: different classes of work. Read it here: brooker.co.za/blog/2025/03...
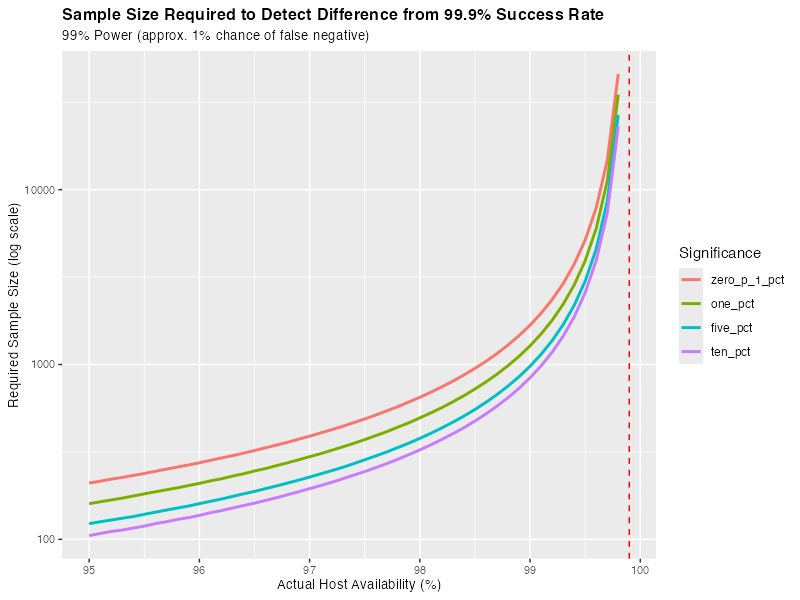
One challenge of handling partial/gray failures in distributed systems is telling 'healthy' from 'unhealthy'. Even in terms of error rate, it can take a surprisingly high number of samples to differentiate between normal and abnormal hosts.
Here's what it looks like:
Here's what it looks like:
February 13, 2025 at 7:52 PM
One challenge of handling partial/gray failures in distributed systems is telling 'healthy' from 'unhealthy'. Even in terms of error rate, it can take a surprisingly high number of samples to differentiate between normal and abnormal hosts.
Here's what it looks like:
Here's what it looks like:

This is a great way to catch bugs, and a great way to ensure that the specification is kept up-to-date. This makes the formal specification work even more valuable.

February 11, 2025 at 4:46 PM
This is a great way to catch bugs, and a great way to ensure that the specification is kept up-to-date. This makes the formal specification work even more valuable.
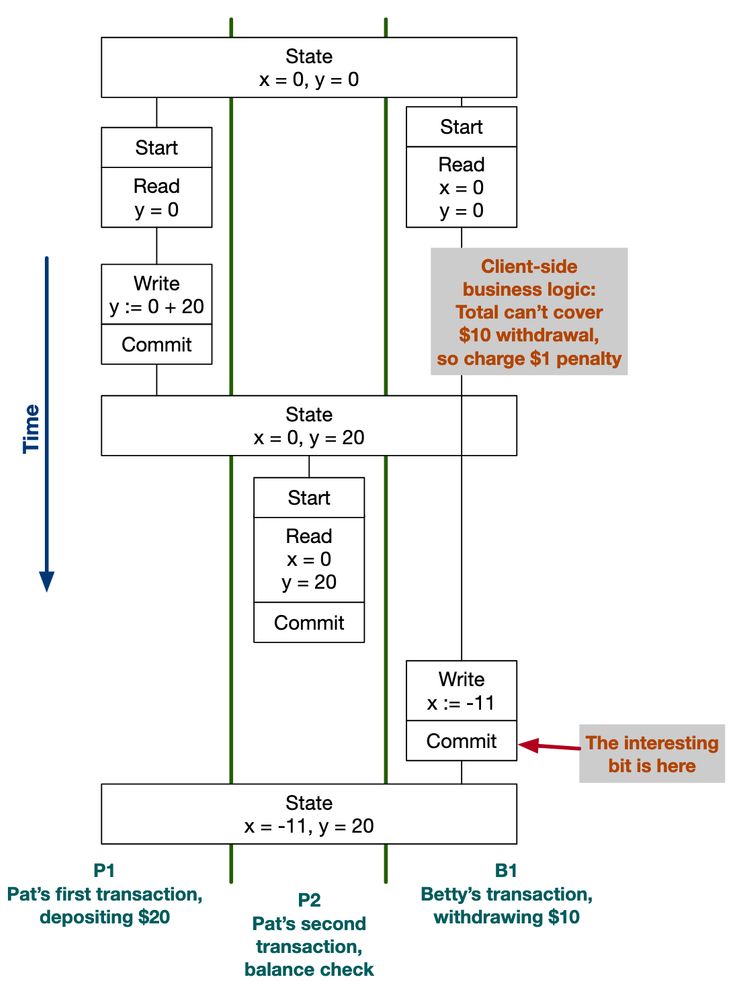
Continuing from yesterday's blog post, today I look at an interesting isolation edge-case from the literature: Fekete's Anomaly. How does it fit in to our theme of achieving performance, scalability, and reliability through reducing coordination? New blog post here: brooker.co.za/blog/2025/02...
February 6, 2025 at 9:34 PM
Continuing from yesterday's blog post, today I look at an interesting isolation edge-case from the literature: Fekete's Anomaly. How does it fit in to our theme of achieving performance, scalability, and reliability through reducing coordination? New blog post here: brooker.co.za/blog/2025/02...
To understand the value of backoff (e.g. exponential backoff), it's worth understanding the distinction between 'open' and 'closed' systems. From the classic paper "Open versus Closed: A Cautionary tale" (www.usenix.org/conference/n...)

December 17, 2024 at 6:23 PM
To understand the value of backoff (e.g. exponential backoff), it's worth understanding the distinction between 'open' and 'closed' systems. From the classic paper "Open versus Closed: A Cautionary tale" (www.usenix.org/conference/n...)
Key take-away: "best practice" approach to retries help when failures are transient, but can make things worse when failures are systemic.
Token bucket approaches can avoid many (but not all) retry-related problems: brooker.co.za/blog/2022/02...
Token bucket approaches can avoid many (but not all) retry-related problems: brooker.co.za/blog/2022/02...

December 17, 2024 at 6:23 PM
Key take-away: "best practice" approach to retries help when failures are transient, but can make things worse when failures are systemic.
Token bucket approaches can avoid many (but not all) retry-related problems: brooker.co.za/blog/2022/02...
Token bucket approaches can avoid many (but not all) retry-related problems: brooker.co.za/blog/2022/02...
And how we can make sure we celebrate Max and Snuffles' birthdays atomically and durably.

December 16, 2024 at 6:27 PM
And how we can make sure we celebrate Max and Snuffles' birthdays atomically and durably.
I also talk a bit about how I think Snapshot Isolation, combined with strong consistency, is a sweet spot in the trade-off space. Stronger levels make reasoning about performance a lot harder, and weaker levels make reasoning about concurrency a lot harder (without much perf win)

December 16, 2024 at 6:27 PM
I also talk a bit about how I think Snapshot Isolation, combined with strong consistency, is a sweet spot in the trade-off space. Stronger levels make reasoning about performance a lot harder, and weaker levels make reasoning about concurrency a lot harder (without much perf win)
The fourth and last in my series of blog posts on our new Aurora DSQL database is up! This time, we're looking at what happens during network partitions, and how we preserve consistency, availability, and durability. Check it out: brooker.co.za/blog/2024/12...

December 6, 2024 at 5:16 PM
The fourth and last in my series of blog posts on our new Aurora DSQL database is up! This time, we're looking at what happens during network partitions, and how we preserve consistency, availability, and durability. Check it out: brooker.co.za/blog/2024/12...
Super excited to have Amazon Aurora DSQL out in the world. Its our new serverless, Postgres-compatible, multi-region active-active, horizontally-scalable SQL database. Read more about it here: aws.amazon.com/rds/aurora/d...

December 3, 2024 at 5:34 PM
Super excited to have Amazon Aurora DSQL out in the world. Its our new serverless, Postgres-compatible, multi-region active-active, horizontally-scalable SQL database. Read more about it here: aws.amazon.com/rds/aurora/d...
Here's the entire text of the program that generates those graphs, including the calculation and simulation, and plots the results.

November 22, 2024 at 4:23 PM
Here's the entire text of the program that generates those graphs, including the calculation and simulation, and plots the results.
Kingman's formula (en.wikipedia.org/wiki/Kingman...) is a remarkably good estimate of the latency experienced by clients of a server under high utilization.
But there's something even more remarkable: how easy GenAI makes it to explore results like this.
But there's something even more remarkable: how easy GenAI makes it to explore results like this.

November 22, 2024 at 4:23 PM
Kingman's formula (en.wikipedia.org/wiki/Kingman...) is a remarkably good estimate of the latency experienced by clients of a server under high utilization.
But there's something even more remarkable: how easy GenAI makes it to explore results like this.
But there's something even more remarkable: how easy GenAI makes it to explore results like this.
In the post I half-heartedly propose SIEVE-k, a variant with better scan-resistance properties on some workloads (and worse properties on some too).

December 15, 2023 at 5:05 PM
In the post I half-heartedly propose SIEVE-k, a variant with better scan-resistance properties on some workloads (and worse properties on some too).
If you want to see an even simpler version of this kind of failure, check out my model here: github.com/mbrooker/sim...

November 14, 2023 at 9:40 PM
If you want to see an even simpler version of this kind of failure, check out my model here: github.com/mbrooker/sim...
Very cool work from Anand et al at SOSP'23: "Blueprint: A Toolchain for Highly-Reconfigurable Microservices" (dl.acm.org/doi/pdf/10.1...). I have a lot to say about this paper, but my favorite part is the treatment of metastable failures.

November 14, 2023 at 9:38 PM
Very cool work from Anand et al at SOSP'23: "Blueprint: A Toolchain for Highly-Reconfigurable Microservices" (dl.acm.org/doi/pdf/10.1...). I have a lot to say about this paper, but my favorite part is the treatment of metastable failures.
One day I hope to write a paper conclusion this clear. (From Gray and Lamport, "Consensus on Transaction Commit"):

October 23, 2023 at 11:05 PM
One day I hope to write a paper conclusion this clear. (From Gray and Lamport, "Consensus on Transaction Commit"):