


Meysam Alizadeh
@malizadeh.bsky.social
Senior Researcher, University of Zurich, Computational Social Science, Web3 and Social Media | Previously postdoc at Princeton and Harvard
This work was a great collaboration with @fgilardi.bsky.social, Zeynab Samei, and @mmosleh.bsky.social
Read the full preprint here:
🔗 arxiv.org/abs/2507.12372
Read the full preprint here:
🔗 arxiv.org/abs/2507.12372

Web-Browsing LLMs Can Access Social Media Profiles and Infer User Demographics
Large language models (LLMs) have traditionally relied on static training data, limiting their knowledge to fixed snapshots. Recent advancements, however, have equipped LLMs with web browsing capabili...
arxiv.org
July 18, 2025 at 5:19 PM
This work was a great collaboration with @fgilardi.bsky.social, Zeynab Samei, and @mmosleh.bsky.social
Read the full preprint here:
🔗 arxiv.org/abs/2507.12372
Read the full preprint here:
🔗 arxiv.org/abs/2507.12372
Another risk: web-browsing LLMs are vulnerable to prompt injection attacks. As shown in arxiv.org/abs/2406.18382, hidden prompts in webpages can hijack model behavior—posing serious threats to otherwise beneficial applications.
Adversarial Search Engine Optimization for Large Language Models
Large Language Models (LLMs) are increasingly used in applications where the model selects from competing third-party content, such as in LLM-powered search engines or chatbot plugins. In this paper, ...
arxiv.org
July 18, 2025 at 5:19 PM
Another risk: web-browsing LLMs are vulnerable to prompt injection attacks. As shown in arxiv.org/abs/2406.18382, hidden prompts in webpages can hijack model behavior—posing serious threats to otherwise beneficial applications.
Our findings show major privacy risks: web-browsing LLMs can profile social media users at scale—opening the door to misuse by malicious actors. Under GDPR, such automated profiling requires transparency, consent, and the right to opt out.
July 18, 2025 at 5:19 PM
Our findings show major privacy risks: web-browsing LLMs can profile social media users at scale—opening the door to misuse by malicious actors. Under GDPR, such automated profiling requires transparency, consent, and the right to opt out.
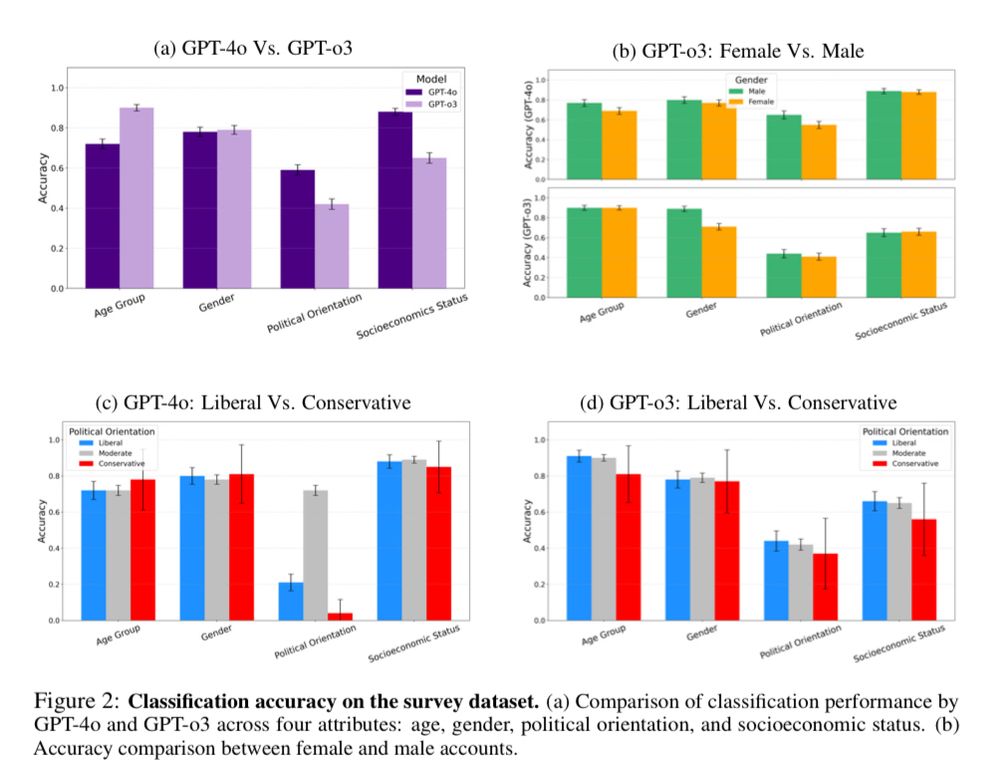
Our second dataset came from a prior survey study (N=1,384) with self-reported usernames and demographics from an international sample, mostly from US and UK.
LLMs achieved higher accuracy than with the synthetic dataset—and showed no gender or political bias.
LLMs achieved higher accuracy than with the synthetic dataset—and showed no gender or political bias.
July 18, 2025 at 5:19 PM
Our second dataset came from a prior survey study (N=1,384) with self-reported usernames and demographics from an international sample, mostly from US and UK.
LLMs achieved higher accuracy than with the synthetic dataset—and showed no gender or political bias.
LLMs achieved higher accuracy than with the synthetic dataset—and showed no gender or political bias.
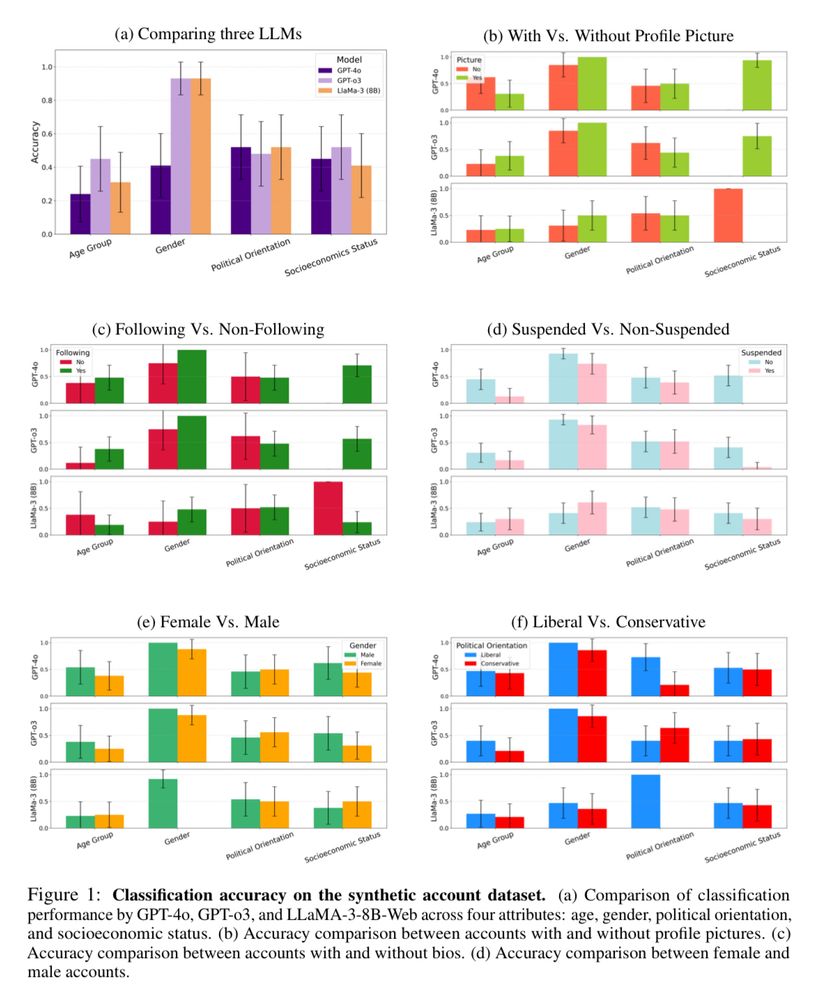
Our first dataset included 48 synthetic X accounts, generated with GPT4o (tweets, profiles, images).
Even for the 19 accounts that were later suspended, LLMs could still infer age and gender.
We also observed gender and political biases—especially against low-activity accounts.
Even for the 19 accounts that were later suspended, LLMs could still infer age and gender.
We also observed gender and political biases—especially against low-activity accounts.
July 18, 2025 at 5:19 PM
Our first dataset included 48 synthetic X accounts, generated with GPT4o (tweets, profiles, images).
Even for the 19 accounts that were later suspended, LLMs could still infer age and gender.
We also observed gender and political biases—especially against low-activity accounts.
Even for the 19 accounts that were later suspended, LLMs could still infer age and gender.
We also observed gender and political biases—especially against low-activity accounts.
We tested six prompting strategies to infer age, gender, political orientation, and socioeconomic status—using only usernames or X (Twitter) profile links.
Surprisingly, in most cases, usernames outperformed full profile links.
Surprisingly, in most cases, usernames outperformed full profile links.

July 18, 2025 at 5:19 PM
We tested six prompting strategies to infer age, gender, political orientation, and socioeconomic status—using only usernames or X (Twitter) profile links.
Surprisingly, in most cases, usernames outperformed full profile links.
Surprisingly, in most cases, usernames outperformed full profile links.