



@majhas.bsky.social
PhD Student at Mila & University of Montreal | Generative modeling, sampling, molecules
majhas.github.io
majhas.github.io
The gifs didn't post properly 😅
Here is one showing the electron cloud in two stages: (1) the learning of electron density during training and (2) the predicted ground-state across conformations 😎
Here is one showing the electron cloud in two stages: (1) the learning of electron density during training and (2) the predicted ground-state across conformations 😎
June 10, 2025 at 10:06 PM
The gifs didn't post properly 😅
Here is one showing the electron cloud in two stages: (1) the learning of electron density during training and (2) the predicted ground-state across conformations 😎
Here is one showing the electron cloud in two stages: (1) the learning of electron density during training and (2) the predicted ground-state across conformations 😎
(9/9)⚡ Runtime efficiency
Self-refining training reduces total runtime up to 4 times compared to the baseline
and up to 2 times compared to the fully-supervised approach!!!
Less need for large pre-generated datasets — training and sampling happen in parallel.
Self-refining training reduces total runtime up to 4 times compared to the baseline
and up to 2 times compared to the fully-supervised approach!!!
Less need for large pre-generated datasets — training and sampling happen in parallel.

June 10, 2025 at 7:49 PM
(9/9)⚡ Runtime efficiency
Self-refining training reduces total runtime up to 4 times compared to the baseline
and up to 2 times compared to the fully-supervised approach!!!
Less need for large pre-generated datasets — training and sampling happen in parallel.
Self-refining training reduces total runtime up to 4 times compared to the baseline
and up to 2 times compared to the fully-supervised approach!!!
Less need for large pre-generated datasets — training and sampling happen in parallel.
(8/n) 🧪 Robust generalization
We simulate molecular dynamics using each model’s energy predictions and evaluate accuracy along the trajectory.
Models trained with self-refinement stay accurate even far from the training distribution — while baselines quickly degrade.
We simulate molecular dynamics using each model’s energy predictions and evaluate accuracy along the trajectory.
Models trained with self-refinement stay accurate even far from the training distribution — while baselines quickly degrade.

June 10, 2025 at 7:49 PM
(8/n) 🧪 Robust generalization
We simulate molecular dynamics using each model’s energy predictions and evaluate accuracy along the trajectory.
Models trained with self-refinement stay accurate even far from the training distribution — while baselines quickly degrade.
We simulate molecular dynamics using each model’s energy predictions and evaluate accuracy along the trajectory.
Models trained with self-refinement stay accurate even far from the training distribution — while baselines quickly degrade.
(7/n) 📊 Performance under data scarcity
Our method achieves low energy error with as few as 25 conformations.
With 10× less data, it matches or outperforms fully supervised baselines.
This is especially important in settings where labeled data is expensive or unavailable.
Our method achieves low energy error with as few as 25 conformations.
With 10× less data, it matches or outperforms fully supervised baselines.
This is especially important in settings where labeled data is expensive or unavailable.

June 10, 2025 at 7:49 PM
(7/n) 📊 Performance under data scarcity
Our method achieves low energy error with as few as 25 conformations.
With 10× less data, it matches or outperforms fully supervised baselines.
This is especially important in settings where labeled data is expensive or unavailable.
Our method achieves low energy error with as few as 25 conformations.
With 10× less data, it matches or outperforms fully supervised baselines.
This is especially important in settings where labeled data is expensive or unavailable.
(6/n) This minimization leads to Self-Refining Training:
🔁 Use the current model to sample conformations via MCMC
📉 Use those conformations to minimize energy and update the model
Everything runs asynchronously, without need for labeled data and minimal number of conformations from a dataset!
🔁 Use the current model to sample conformations via MCMC
📉 Use those conformations to minimize energy and update the model
Everything runs asynchronously, without need for labeled data and minimal number of conformations from a dataset!

June 10, 2025 at 7:49 PM
(6/n) This minimization leads to Self-Refining Training:
🔁 Use the current model to sample conformations via MCMC
📉 Use those conformations to minimize energy and update the model
Everything runs asynchronously, without need for labeled data and minimal number of conformations from a dataset!
🔁 Use the current model to sample conformations via MCMC
📉 Use those conformations to minimize energy and update the model
Everything runs asynchronously, without need for labeled data and minimal number of conformations from a dataset!
(5/n) To get around this, we introduce a variational upper bound on the KL between any sampling distribution q(R) and the target Boltzmann distribution.
Jointly minimizing this bound wrt θ and q yields
✅ A model that predicts the ground-state solutions
✅ Samples that match the ground true density
Jointly minimizing this bound wrt θ and q yields
✅ A model that predicts the ground-state solutions
✅ Samples that match the ground true density

June 10, 2025 at 7:49 PM
(5/n) To get around this, we introduce a variational upper bound on the KL between any sampling distribution q(R) and the target Boltzmann distribution.
Jointly minimizing this bound wrt θ and q yields
✅ A model that predicts the ground-state solutions
✅ Samples that match the ground true density
Jointly minimizing this bound wrt θ and q yields
✅ A model that predicts the ground-state solutions
✅ Samples that match the ground true density
(4/n) With an amortized DFT model f_θ(R), we define the density of molecular conformations as the
Boltzmann distribution
This isn't a typical ML setup because
❌ No samples from the density - can’t train a generative model
❌ No density - can’t sample via Monte Carlo!
Boltzmann distribution
This isn't a typical ML setup because
❌ No samples from the density - can’t train a generative model
❌ No density - can’t sample via Monte Carlo!

June 10, 2025 at 7:49 PM
(4/n) With an amortized DFT model f_θ(R), we define the density of molecular conformations as the
Boltzmann distribution
This isn't a typical ML setup because
❌ No samples from the density - can’t train a generative model
❌ No density - can’t sample via Monte Carlo!
Boltzmann distribution
This isn't a typical ML setup because
❌ No samples from the density - can’t train a generative model
❌ No density - can’t sample via Monte Carlo!
(3/n) DFT offers a scalable solution to the Schrödinger equation but must be solved independently for each geometry by minimizing energy wrt coefficients C for a fixed basis.
This presents a bottleneck for MD/sampling.
We want to amortize this - train a model that generalizes across geometries R.
This presents a bottleneck for MD/sampling.
We want to amortize this - train a model that generalizes across geometries R.

June 10, 2025 at 7:49 PM
(3/n) DFT offers a scalable solution to the Schrödinger equation but must be solved independently for each geometry by minimizing energy wrt coefficients C for a fixed basis.
This presents a bottleneck for MD/sampling.
We want to amortize this - train a model that generalizes across geometries R.
This presents a bottleneck for MD/sampling.
We want to amortize this - train a model that generalizes across geometries R.
(1/n)🚨Train a model solving DFT for any geometry with almost no training data
Introducing Self-Refining Training for Amortized DFT: a variational method that predicts ground-state solutions across geometries and generates its own training data!
📜 arxiv.org/abs/2506.01225
💻 github.com/majhas/self-...
Introducing Self-Refining Training for Amortized DFT: a variational method that predicts ground-state solutions across geometries and generates its own training data!
📜 arxiv.org/abs/2506.01225
💻 github.com/majhas/self-...
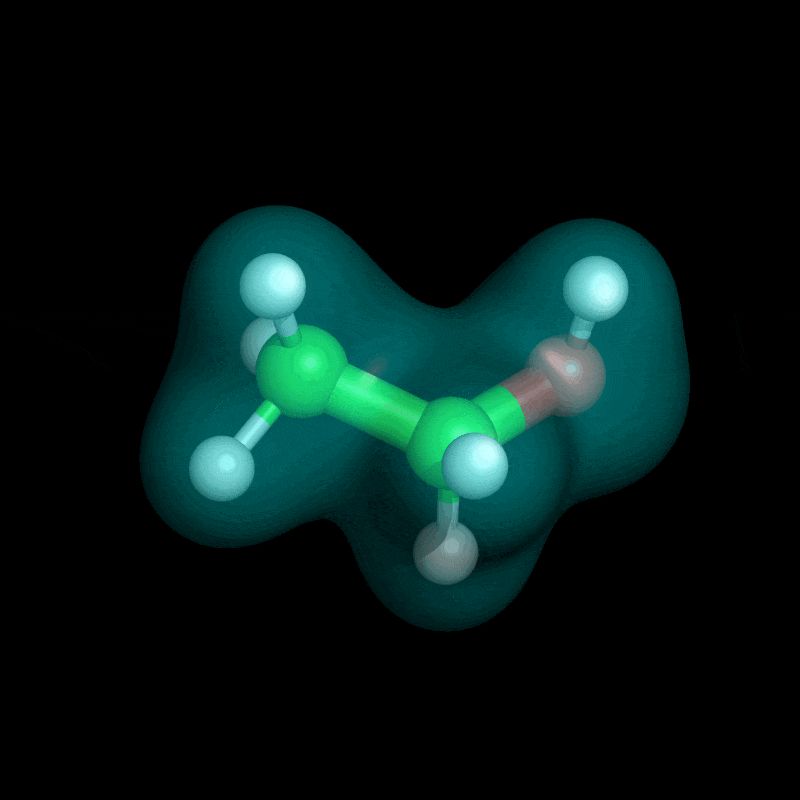
June 10, 2025 at 7:49 PM
(1/n)🚨Train a model solving DFT for any geometry with almost no training data
Introducing Self-Refining Training for Amortized DFT: a variational method that predicts ground-state solutions across geometries and generates its own training data!
📜 arxiv.org/abs/2506.01225
💻 github.com/majhas/self-...
Introducing Self-Refining Training for Amortized DFT: a variational method that predicts ground-state solutions across geometries and generates its own training data!
📜 arxiv.org/abs/2506.01225
💻 github.com/majhas/self-...