




Shang Qu
@lindsayttsq.bsky.social
AI4Biomed & LLMs @ Tsinghua University
We also found that reasoning process errors & perceptual errors (in MM) take up a large percentage of model errors. Error cases provide further insights into the challenges models still face regarding clinical reasoning:

February 4, 2025 at 1:33 PM
We also found that reasoning process errors & perceptual errors (in MM) take up a large percentage of model errors. Error cases provide further insights into the challenges models still face regarding clinical reasoning:
💡Clinical reasoning facilitates model reasoning evaluation beyond math & code. We annotate MedXpertQA questions as Reasoning/Understanding based on required reasoning complexity.
Comparing 3 inference-time scaled models against their backbones, we find distinct improvements in the Reasoning subset:
Comparing 3 inference-time scaled models against their backbones, we find distinct improvements in the Reasoning subset:

February 4, 2025 at 1:32 PM
💡Clinical reasoning facilitates model reasoning evaluation beyond math & code. We annotate MedXpertQA questions as Reasoning/Understanding based on required reasoning complexity.
Comparing 3 inference-time scaled models against their backbones, we find distinct improvements in the Reasoning subset:
Comparing 3 inference-time scaled models against their backbones, we find distinct improvements in the Reasoning subset:
We improve clinical relevance through
⭐️Medical specialty coverage: MedXpertQA includes questions from 20+ exams of medical licensing level or higher
⭐️Realistic context: MM is the first multimodal medical benchmark to introduce rich clinical information with diverse image types
⭐️Medical specialty coverage: MedXpertQA includes questions from 20+ exams of medical licensing level or higher
⭐️Realistic context: MM is the first multimodal medical benchmark to introduce rich clinical information with diverse image types

February 4, 2025 at 1:31 PM
We improve clinical relevance through
⭐️Medical specialty coverage: MedXpertQA includes questions from 20+ exams of medical licensing level or higher
⭐️Realistic context: MM is the first multimodal medical benchmark to introduce rich clinical information with diverse image types
⭐️Medical specialty coverage: MedXpertQA includes questions from 20+ exams of medical licensing level or higher
⭐️Realistic context: MM is the first multimodal medical benchmark to introduce rich clinical information with diverse image types
Compared with rapidly saturating benchmarks like MedQA, we raise the bar with harder questions and a sharper focus on medical reasoning.
Full results evaluating 17 LLMs, LMMs, and inference-time scaled models:
Full results evaluating 17 LLMs, LMMs, and inference-time scaled models:


February 4, 2025 at 1:30 PM
Compared with rapidly saturating benchmarks like MedQA, we raise the bar with harder questions and a sharper focus on medical reasoning.
Full results evaluating 17 LLMs, LMMs, and inference-time scaled models:
Full results evaluating 17 LLMs, LMMs, and inference-time scaled models:
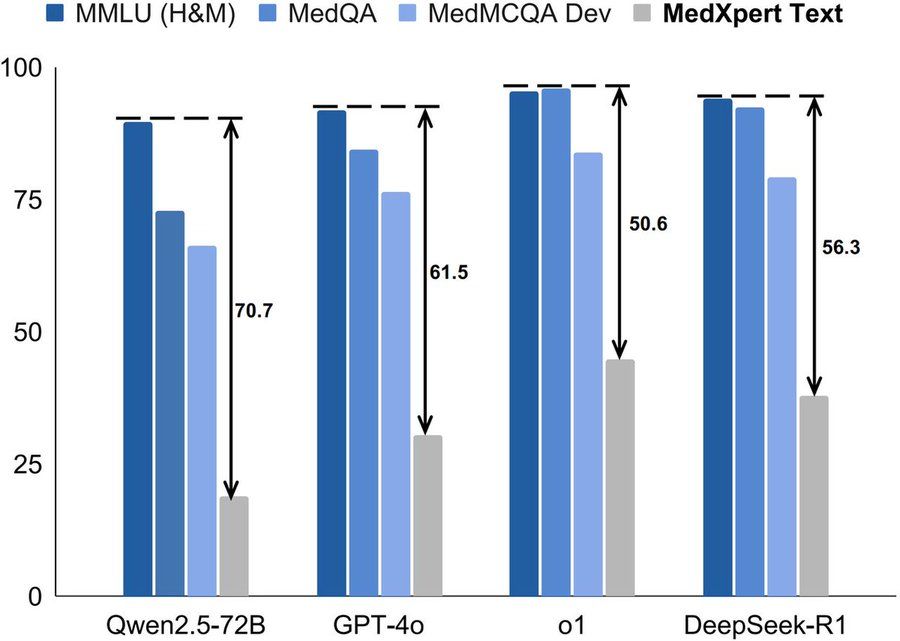
📈How far are leading models from mastering realistic medical tasks? MedXpertQA, our new text & multimodal medical benchmark, reveals gaps in model abilities
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
February 4, 2025 at 1:29 PM
📈How far are leading models from mastering realistic medical tasks? MedXpertQA, our new text & multimodal medical benchmark, reveals gaps in model abilities
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!
📌Percentage scores on our Text subset:
o3-mini: 37.30
R1: 37.76 - frontrunner among open-source models
o1: 44.67 - still room for improvement!