



Lukas Gienapp
@lgnp.bsky.social
ML/IR research @ hessianAI / Kassel University & ScaDS.AI. RAG & neural retrieval models.
Reposted by Lukas Gienapp

We just released "German Commons", the largest openly-licensed German text dataset for LLM training: 154B tokens with clear usage rights for research and commercial use.
huggingface.co/datasets/coral-nlp/german-commons
huggingface.co/datasets/coral-nlp/german-commons

coral-nlp/german-commons · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
October 27, 2025 at 12:45 PM
We just released "German Commons", the largest openly-licensed German text dataset for LLM training: 154B tokens with clear usage rights for research and commercial use.
huggingface.co/datasets/coral-nlp/german-commons
huggingface.co/datasets/coral-nlp/german-commons
Reposted by Lukas Gienapp
Happy to share that our paper "The Viability of Crowdsourcing for RAG Evaluation" received the Best Paper Honourable Mention at #SIGIR2025! Very grateful to the community for recognizing our work on improving RAG evaluation.
📄 webis.de/publications...
📄 webis.de/publications...

July 16, 2025 at 9:04 PM
Happy to share that our paper "The Viability of Crowdsourcing for RAG Evaluation" received the Best Paper Honourable Mention at #SIGIR2025! Very grateful to the community for recognizing our work on improving RAG evaluation.
📄 webis.de/publications...
📄 webis.de/publications...
Reposted by Lukas Gienapp

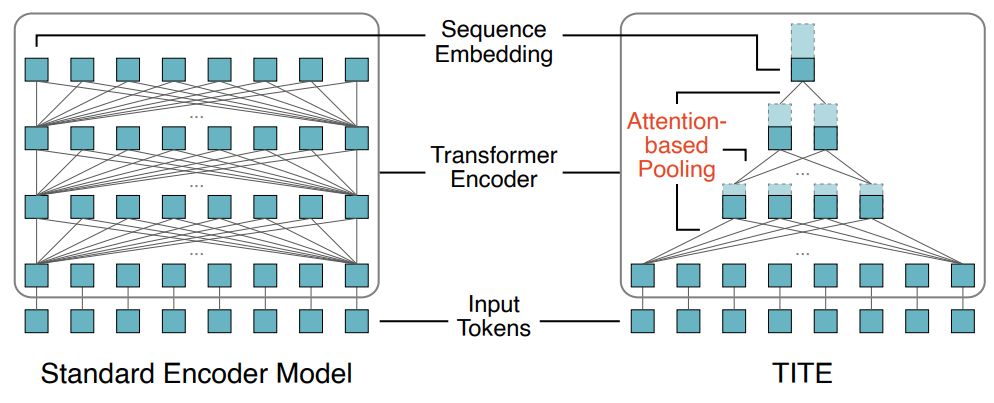
Want to know how to make bi-encoders more than 3x faster with a new backbone encoder model? Check out our talk on the Token-Independent Text Encoder (TITE) #SIGIR2025 in the efficiency track. It pools vectors within the model to improve efficiency dl.acm.org/doi/10.1145/...
July 16, 2025 at 7:28 AM
Want to know how to make bi-encoders more than 3x faster with a new backbone encoder model? Check out our talk on the Token-Independent Text Encoder (TITE) #SIGIR2025 in the efficiency track. It pools vectors within the model to improve efficiency dl.acm.org/doi/10.1145/...
Reposted by Lukas Gienapp

Lukas Gienapp presents "The Viability of Crowdsourcing for RAG Evaluation" at #SIGIR2025
The paper is available at: webis.de/publications...
The paper is available at: webis.de/publications...


July 15, 2025 at 1:53 PM
Lukas Gienapp presents "The Viability of Crowdsourcing for RAG Evaluation" at #SIGIR2025
The paper is available at: webis.de/publications...
The paper is available at: webis.de/publications...
Reposted by Lukas Gienapp
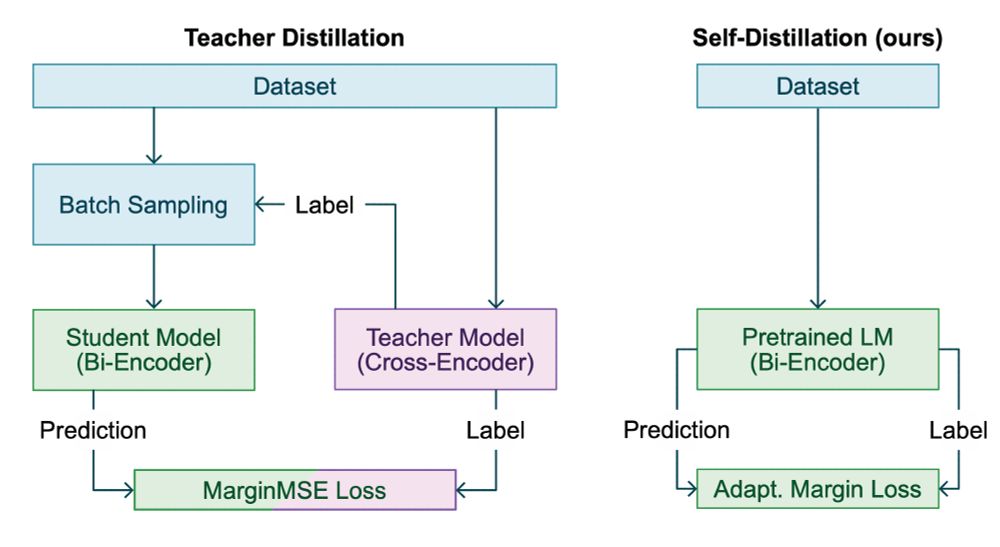
Our paper on self-distillation for training bi-encoders got accepted at #ICTIR2025! By exploiting pretrained encoder capabilities, our approach eliminates expensive teacher models and batch sampling while maintaining the same effectiveness.
June 22, 2025 at 12:33 PM
Our paper on self-distillation for training bi-encoders got accepted at #ICTIR2025! By exploiting pretrained encoder capabilities, our approach eliminates expensive teacher models and batch sampling while maintaining the same effectiveness.
Reposted by Lukas Gienapp
📢 Our paper "The Viability of Crowdsourcing for RAG Evaluation" has been accepted to #SIGIR2025 !
We compared how good humans and LLMs are at writing and judging RAG responses, assembling 1800+ responses across 3 styles, and 47K+ pairwise judgments in 7 quality dimensions. 🧵➡️
We compared how good humans and LLMs are at writing and judging RAG responses, assembling 1800+ responses across 3 styles, and 47K+ pairwise judgments in 7 quality dimensions. 🧵➡️

April 7, 2025 at 3:34 PM
📢 Our paper "The Viability of Crowdsourcing for RAG Evaluation" has been accepted to #SIGIR2025 !
We compared how good humans and LLMs are at writing and judging RAG responses, assembling 1800+ responses across 3 styles, and 47K+ pairwise judgments in 7 quality dimensions. 🧵➡️
We compared how good humans and LLMs are at writing and judging RAG responses, assembling 1800+ responses across 3 styles, and 47K+ pairwise judgments in 7 quality dimensions. 🧵➡️