




Leon Lang
@leon-lang.bsky.social
PhD Candidate at the University of Amsterdam. AI Alignment and safety research. Formerly multivariate information theory and equivariant deep learning. Masters degrees in both maths and AI. https://langleon.github.io/
Reposted by Leon Lang

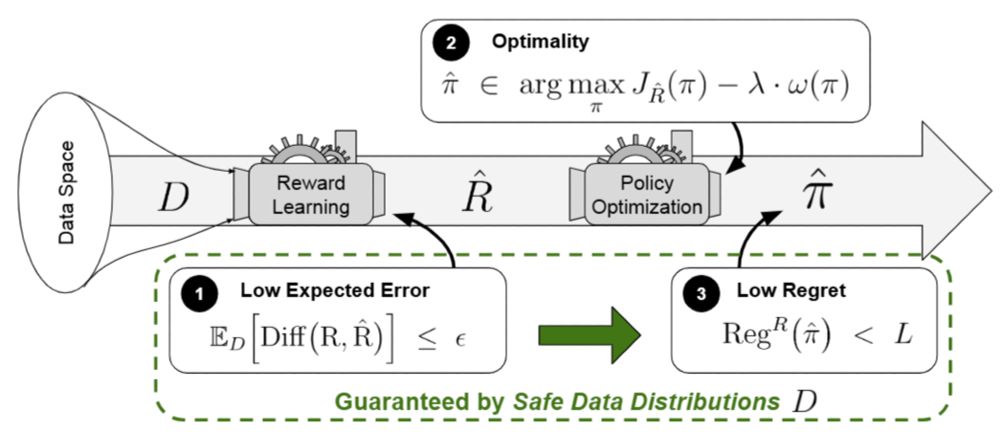
⚠️ The Perils of Optimizing Learned Reward Functions: Low Training Error Does Not Guarantee Low Regret
By Lukas Fluri*, @leon-lang.bsky.social *, Alessandro Abate, Patrick Forré, David Krueger, Joar Skalse
📜 arxiv.org/abs/2406.15753
🧵6 / 8
By Lukas Fluri*, @leon-lang.bsky.social *, Alessandro Abate, Patrick Forré, David Krueger, Joar Skalse
📜 arxiv.org/abs/2406.15753
🧵6 / 8
May 6, 2025 at 2:53 PM
⚠️ The Perils of Optimizing Learned Reward Functions: Low Training Error Does Not Guarantee Low Regret
By Lukas Fluri*, @leon-lang.bsky.social *, Alessandro Abate, Patrick Forré, David Krueger, Joar Skalse
📜 arxiv.org/abs/2406.15753
🧵6 / 8
By Lukas Fluri*, @leon-lang.bsky.social *, Alessandro Abate, Patrick Forré, David Krueger, Joar Skalse
📜 arxiv.org/abs/2406.15753
🧵6 / 8
Paper link: arxiv.org/abs/2502.21262
(4/4)
(4/4)

Modeling Human Beliefs about AI Behavior for Scalable Oversight
Contemporary work in AI alignment often relies on human feedback to teach AI systems human preferences and values. Yet as AI systems grow more capable, human feedback becomes increasingly unreliable. ...
arxiv.org
March 3, 2025 at 3:44 PM
Paper link: arxiv.org/abs/2502.21262
(4/4)
(4/4)
I theoretically describe what modeling the human's beliefs would mean, and explain a practical proposal for how one could try to do this, based on foundation models whose internal representations *translate to* the human's beliefs using an implicit ontology translation. (3/4)
March 3, 2025 at 3:44 PM
I theoretically describe what modeling the human's beliefs would mean, and explain a practical proposal for how one could try to do this, based on foundation models whose internal representations *translate to* the human's beliefs using an implicit ontology translation. (3/4)
The idea: In the robot-hand example, when the hand is in front of the ball, the human believes the ball was grasped and gives "thumbs up", leading to bad behavior. If we knew the human's beliefs, then we could assign the feedback properly: Reward the ball being grasped! (2/4)
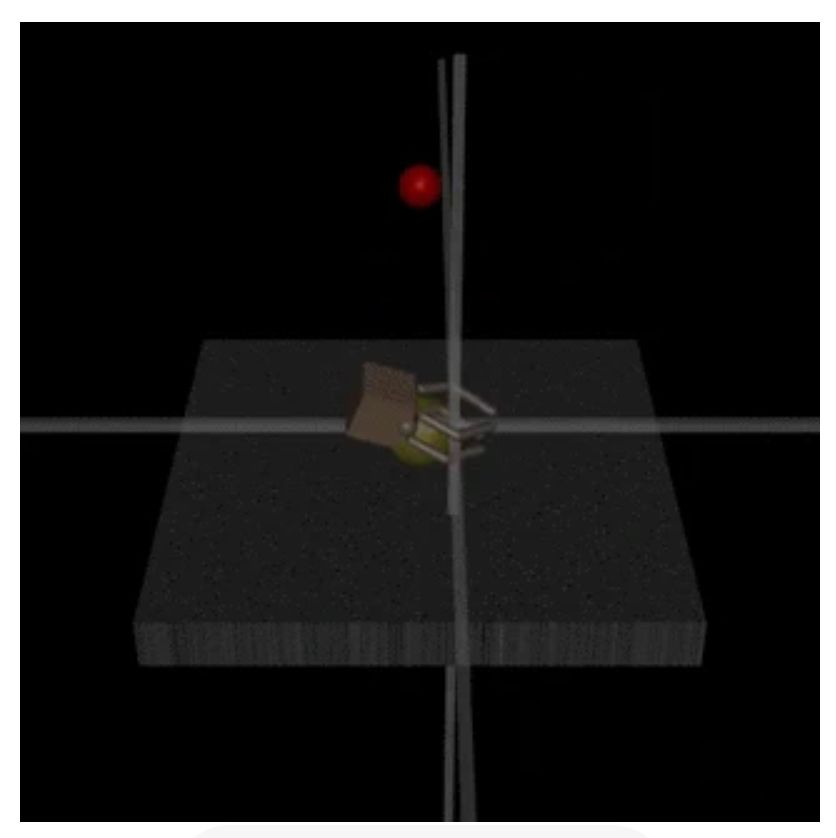
March 3, 2025 at 3:44 PM
The idea: In the robot-hand example, when the hand is in front of the ball, the human believes the ball was grasped and gives "thumbs up", leading to bad behavior. If we knew the human's beliefs, then we could assign the feedback properly: Reward the ball being grasped! (2/4)
www.arxiv.org/abs/2502.21262
I have now this follow-up paper that goes into greater detail for how to achieve the human belief modeling, both conceptually and potentially in practice.
I have now this follow-up paper that goes into greater detail for how to achieve the human belief modeling, both conceptually and potentially in practice.
Modeling Human Beliefs about AI Behavior for Scalable Oversight
Contemporary work in AI alignment often relies on human feedback to teach AI systems human preferences and values. Yet as AI systems grow more capable, human feedback becomes increasingly unreliable. ...
www.arxiv.org
March 3, 2025 at 3:41 PM
www.arxiv.org/abs/2502.21262
I have now this follow-up paper that goes into greater detail for how to achieve the human belief modeling, both conceptually and potentially in practice.
I have now this follow-up paper that goes into greater detail for how to achieve the human belief modeling, both conceptually and potentially in practice.
Interesting, I didn’t know such things are common practice!
November 24, 2024 at 7:53 AM
Interesting, I didn’t know such things are common practice!
I think such questionnaires should maybe generally contain a control group of people who did some brief (let’s say 15 minutes) calibration training just do understand what percentages even mean.
November 23, 2024 at 10:48 PM
I think such questionnaires should maybe generally contain a control group of people who did some brief (let’s say 15 minutes) calibration training just do understand what percentages even mean.
Are people maybe very bad at math?
I remember once that I asked my own mom to draw what one million dollars looks like in proportion to 1 billion, and she drew like what corresponds to ~ 150 million, off by a factor of 150.
I remember once that I asked my own mom to draw what one million dollars looks like in proportion to 1 billion, and she drew like what corresponds to ~ 150 million, off by a factor of 150.
November 23, 2024 at 10:47 PM
Are people maybe very bad at math?
I remember once that I asked my own mom to draw what one million dollars looks like in proportion to 1 billion, and she drew like what corresponds to ~ 150 million, off by a factor of 150.
I remember once that I asked my own mom to draw what one million dollars looks like in proportion to 1 billion, and she drew like what corresponds to ~ 150 million, off by a factor of 150.
Yeah risks are then probably more external: who creates the LLM, and do they poison the data in such a way that it will associate human utterances to bad goals.
November 23, 2024 at 10:41 PM
Yeah risks are then probably more external: who creates the LLM, and do they poison the data in such a way that it will associate human utterances to bad goals.
I actually think I (essentially?) understood this! Ie my worry was whether the LLM could end up giving high likelihood to human utterances for goals that are very bad.
November 23, 2024 at 10:40 PM
I actually think I (essentially?) understood this! Ie my worry was whether the LLM could end up giving high likelihood to human utterances for goals that are very bad.
I see, interesting.
Is the hope basically that the LLM utters "the same things" as what the human would utter under the same goal? Is there a (somewhat futuristic...) risk that a misaligned language model might "try" to utter the human's phrase under its own misaligned goals?
Is the hope basically that the LLM utters "the same things" as what the human would utter under the same goal? Is there a (somewhat futuristic...) risk that a misaligned language model might "try" to utter the human's phrase under its own misaligned goals?
November 23, 2024 at 7:44 PM
I see, interesting.
Is the hope basically that the LLM utters "the same things" as what the human would utter under the same goal? Is there a (somewhat futuristic...) risk that a misaligned language model might "try" to utter the human's phrase under its own misaligned goals?
Is the hope basically that the LLM utters "the same things" as what the human would utter under the same goal? Is there a (somewhat futuristic...) risk that a misaligned language model might "try" to utter the human's phrase under its own misaligned goals?
You could add myself possibly
November 21, 2024 at 8:27 AM
You could add myself possibly
I strongly disagree. I’d even go as far as saying that for most relevant purposes, it’s fine to say mushrooms are plants. www.google.com/url?q=https:...

The Categories Were Made For Man, Not Man For The Categories
I. “Silliest internet atheist argument” is a hotly contested title, but I have a special place in my heart for the people who occasionally try to prove Biblical fallibility by pointing …
www.google.com
November 21, 2024 at 6:49 AM
I strongly disagree. I’d even go as far as saying that for most relevant purposes, it’s fine to say mushrooms are plants. www.google.com/url?q=https:...