




Lennart Purucker
@lennartpurucker.bsky.social
PhD student sup. by Frank Hutter; researching automated machine learning and foundation models for (small) tabular data!
Website: https://ml.informatik.uni-freiburg.de/profile/purucker/
Website: https://ml.informatik.uni-freiburg.de/profile/purucker/
TabArena is a living benchmark. With the community, we will continually update it!
Authors: @nickerickson.bsky.social Lennart Purucker @atschalz.bsky.social @dholzmueller.bsky.social Prateek Desai David Salinas Frank Hutter
LB: tabarena.ai
Paper: arxiv.org/abs/2506.16791
Code: tabarena.ai/code
12/
Authors: @nickerickson.bsky.social Lennart Purucker @atschalz.bsky.social @dholzmueller.bsky.social Prateek Desai David Salinas Frank Hutter
LB: tabarena.ai
Paper: arxiv.org/abs/2506.16791
Code: tabarena.ai/code
12/
June 23, 2025 at 10:15 AM
TabArena is a living benchmark. With the community, we will continually update it!
Authors: @nickerickson.bsky.social Lennart Purucker @atschalz.bsky.social @dholzmueller.bsky.social Prateek Desai David Salinas Frank Hutter
LB: tabarena.ai
Paper: arxiv.org/abs/2506.16791
Code: tabarena.ai/code
12/
Authors: @nickerickson.bsky.social Lennart Purucker @atschalz.bsky.social @dholzmueller.bsky.social Prateek Desai David Salinas Frank Hutter
LB: tabarena.ai
Paper: arxiv.org/abs/2506.16791
Code: tabarena.ai/code
12/
The TabArena team consists of experienced researchers and open-source developers. At the same time, we are also authors of some of the methods benchmarked in our work. We challenge you to find any mistakes or biases in our work to further improve TabArena!
11/
11/

June 23, 2025 at 10:15 AM
The TabArena team consists of experienced researchers and open-source developers. At the same time, we are also authors of some of the methods benchmarked in our work. We challenge you to find any mistakes or biases in our work to further improve TabArena!
11/
11/
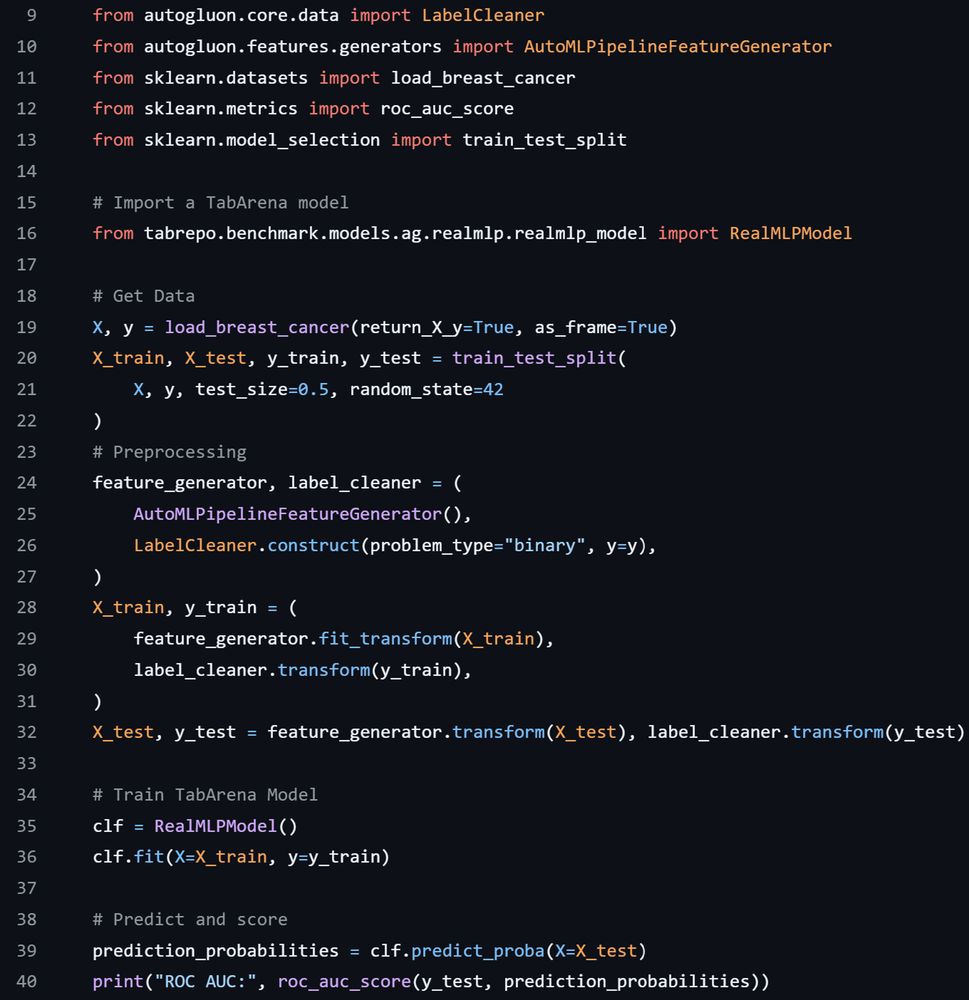
We are continuing to improve the TabArena and its usability. You can already use our implementations of all models we benchmarked with scikit-learn-like interfaces:
10/
10/
June 23, 2025 at 10:15 AM
We are continuing to improve the TabArena and its usability. You can already use our implementations of all models we benchmarked with scikit-learn-like interfaces:
10/
10/
Many benchmarks evaluate methods using holdout validation. We show that this incorrectly represents the relative comparison of methods and results in much worse peak performance! Non-ensemble methods like RealMLP and ModernNCA gain more from 8-fold CV.
9/
9/

June 23, 2025 at 10:15 AM
Many benchmarks evaluate methods using holdout validation. We show that this incorrectly represents the relative comparison of methods and results in much worse peak performance! Non-ensemble methods like RealMLP and ModernNCA gain more from 8-fold CV.
9/
9/
The worth of models lies not only in their individual performance but also in their contribution to a multi-model ensemble. We build an ensemble of strong and diverse model configurations and show that it significantly outperforms the current SOTA on tabular data, AutoGluon.
8/
8/

June 23, 2025 at 10:15 AM
The worth of models lies not only in their individual performance but also in their contribution to a multi-model ensemble. We build an ensemble of strong and diverse model configurations and show that it significantly outperforms the current SOTA on tabular data, AutoGluon.
8/
8/
In terms of training and inference time, tree-based methods still shine compared to modern neural networks.
7/
7/

June 23, 2025 at 10:15 AM
In terms of training and inference time, tree-based methods still shine compared to modern neural networks.
7/
7/
We evaluate three foundation models. TabDPT runs on every dataset and is mid-field with good regression results. TabPFNv2 and TabICL achieve very good results on subsets of the benchmark within their corresponding dataset constraints (left: TabPFNv2, right: TabICL).
6/
6/

June 23, 2025 at 10:15 AM
We evaluate three foundation models. TabDPT runs on every dataset and is mid-field with good regression results. TabPFNv2 and TabICL achieve very good results on subsets of the benchmark within their corresponding dataset constraints (left: TabPFNv2, right: TabICL).
6/
6/
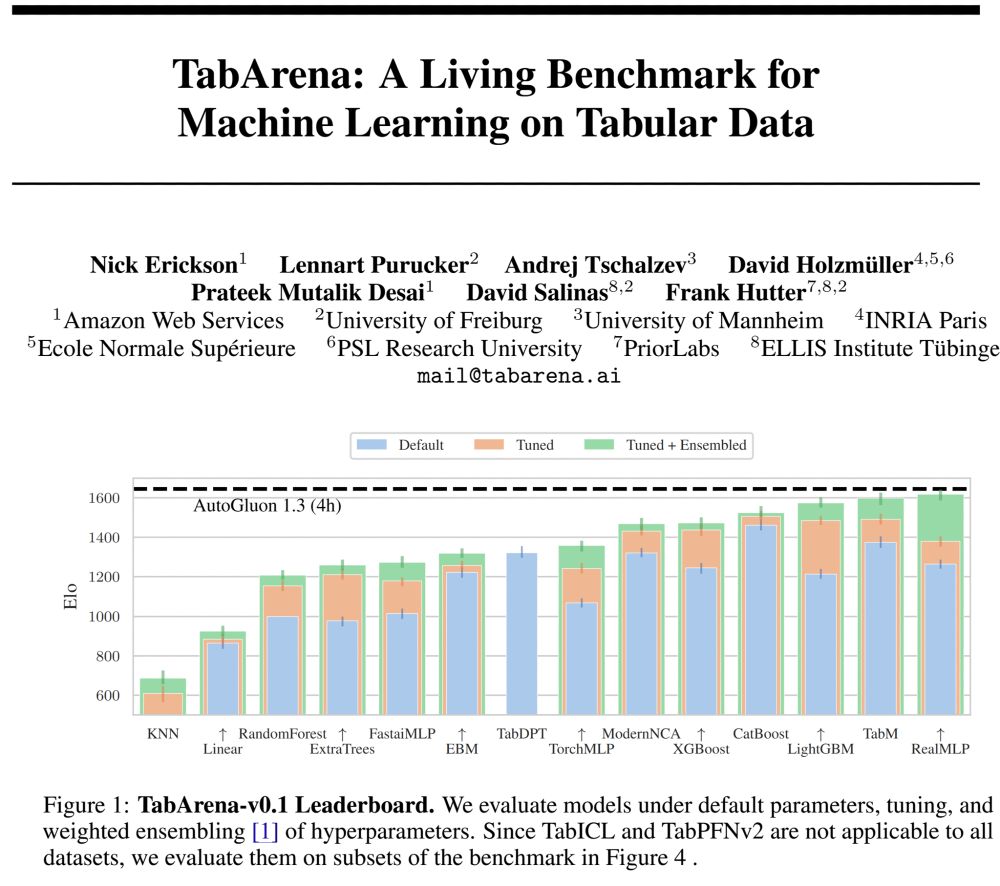
On the full benchmark, the recent deep learning models RealMLP and TabM take the top spots with weighted ensembling, slightly outperforming boosted trees on average, although boosted trees are faster. Without ensembling, CatBoost wins.
5/
5/

June 23, 2025 at 10:15 AM
On the full benchmark, the recent deep learning models RealMLP and TabM take the top spots with weighted ensembling, slightly outperforming boosted trees on average, although boosted trees are faster. Without ensembling, CatBoost wins.
5/
5/
Where possible, we coordinate with authors to obtain good hyperparameter search spaces. For tree-based baselines, we took implementations from AutoGluon and made them better by carefully optimizing their search spaces, so these might be the best baselines out there.
4/
4/

June 23, 2025 at 10:15 AM
Where possible, we coordinate with authors to obtain good hyperparameter search spaces. For tree-based baselines, we took implementations from AutoGluon and made them better by carefully optimizing their search spaces, so these might be the best baselines out there.
4/
4/
We curated datasets by 𝗺𝗮𝗻𝘂𝗮𝗹𝗹𝘆 checking 1053 datasets from prior benchmarks. Only 51 were realistic tabular IID predictive tasks with 500-250K samples, which we share via OpenML. Together with the community, we aim to extend TabArena's datasets in the future!
3/
3/

June 23, 2025 at 10:15 AM
We curated datasets by 𝗺𝗮𝗻𝘂𝗮𝗹𝗹𝘆 checking 1053 datasets from prior benchmarks. Only 51 were realistic tabular IID predictive tasks with 500-250K samples, which we share via OpenML. Together with the community, we aim to extend TabArena's datasets in the future!
3/
3/
TabArena implements best practices for SOTA performance: 8-fold inner cross-validation with bagging, outer cross-validation for evaluation, early stopping where possible, extensive tuning, and weighted ensembles of hyperparameter configurations to obtain peak performance.
2/
2/

June 23, 2025 at 10:15 AM
TabArena implements best practices for SOTA performance: 8-fold inner cross-validation with bagging, outer cross-validation for evaluation, early stopping where possible, extensive tuning, and weighted ensembles of hyperparameter configurations to obtain peak performance.
2/
2/
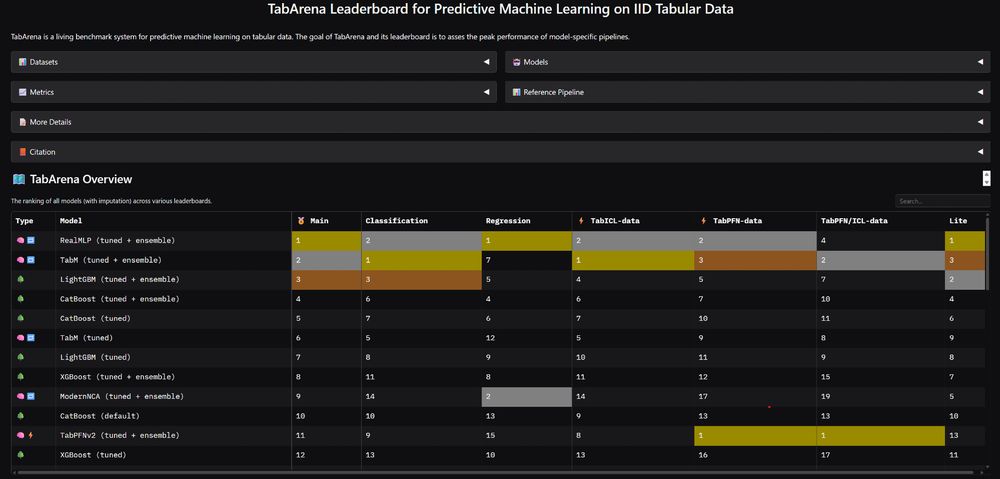
🚨What is SOTA on tabular data, really? We are excited to announce 𝗧𝗮𝗯𝗔𝗿𝗲𝗻𝗮, a living benchmark for machine learning on IID tabular data with:
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
June 23, 2025 at 10:15 AM
🚨What is SOTA on tabular data, really? We are excited to announce 𝗧𝗮𝗯𝗔𝗿𝗲𝗻𝗮, a living benchmark for machine learning on IID tabular data with:
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
The tabular foundation model TabPFN v2 is finally public 🎉🥳
This is excellent news for (small) tabular ML! Checkout our Nature article (nature.com/articles/s41...) and code (github.com/PriorLabs/Ta...)
This is excellent news for (small) tabular ML! Checkout our Nature article (nature.com/articles/s41...) and code (github.com/PriorLabs/Ta...)

January 9, 2025 at 8:33 AM
The tabular foundation model TabPFN v2 is finally public 🎉🥳
This is excellent news for (small) tabular ML! Checkout our Nature article (nature.com/articles/s41...) and code (github.com/PriorLabs/Ta...)
This is excellent news for (small) tabular ML! Checkout our Nature article (nature.com/articles/s41...) and code (github.com/PriorLabs/Ta...)