



Matthew Leisten
@leistenecon.bsky.social
Economist at FTC. IO, antitrust, pricing. Theory to empirics and back. Foodie. All views my own.
Last: what if consumers don't like their data being *used* for ads? We show that this can lead to the poorest & wealthiest consumers being made better off, but the lower-middle class is harmed.


April 7, 2025 at 2:52 PM
Last: what if consumers don't like their data being *used* for ads? We show that this can lead to the poorest & wealthiest consumers being made better off, but the lower-middle class is harmed.
Second: what if consumers intrinsically value privacy? Doesn't change their choices, but privacy regulation shifts everybody's preferences upward. If the wealthy value their privacy more than the poor, then privacy policy becomes even more regressive (but obviously good for CS)

April 7, 2025 at 2:52 PM
Second: what if consumers intrinsically value privacy? Doesn't change their choices, but privacy regulation shifts everybody's preferences upward. If the wealthy value their privacy more than the poor, then privacy policy becomes even more regressive (but obviously good for CS)
We explore 3 extensions. First: what if wealthy eyeballs are more valuable than poor ones to advertisers? Turns out everything goes through *if* wealthy eyeball profitability is most impacted by privacy regulation.

April 7, 2025 at 2:52 PM
We explore 3 extensions. First: what if wealthy eyeballs are more valuable than poor ones to advertisers? Turns out everything goes through *if* wealthy eyeball profitability is most impacted by privacy regulation.
Who gains? Inframarginal premium consumers (wealthy) who pay lower p. Who loses? Inframarginal free consumers (poor) who face higher a. Distributionally bad! We show this using my (Leisten 2024) "inequality-adjusted consumer surplus"

April 7, 2025 at 2:52 PM
Who gains? Inframarginal premium consumers (wealthy) who pay lower p. Who loses? Inframarginal free consumers (poor) who face higher a. Distributionally bad! We show this using my (Leisten 2024) "inequality-adjusted consumer surplus"
Privacy regulation worsens targeting, lowers advertiser WTP, and induces the platform to *shift* users from ad-supported to premium by raising a & lowering p
(This is only true in a "full coverage separating equilibrium" which we define and provide conditions for in the paper)
(This is only true in a "full coverage separating equilibrium" which we define and provide conditions for in the paper)

April 7, 2025 at 2:52 PM
Privacy regulation worsens targeting, lowers advertiser WTP, and induces the platform to *shift* users from ad-supported to premium by raising a & lowering p
(This is only true in a "full coverage separating equilibrium" which we define and provide conditions for in the paper)
(This is only true in a "full coverage separating equilibrium" which we define and provide conditions for in the paper)
Freemium: a free ad-supported version and a paid ad-free version, is everywhere these days. Youtube, Spotify, Netflix, etc.
Why offer the ad-supported version? You can get price-sensitive (poorer) customers but still monetize their attention
Why offer the ad-supported version? You can get price-sensitive (poorer) customers but still monetize their attention

April 7, 2025 at 2:52 PM
Freemium: a free ad-supported version and a paid ad-free version, is everywhere these days. Youtube, Spotify, Netflix, etc.
Why offer the ad-supported version? You can get price-sensitive (poorer) customers but still monetize their attention
Why offer the ad-supported version? You can get price-sensitive (poorer) customers but still monetize their attention
#EconSky 🚨NEW PAPER with Ben Casner:
We present a theory of why privacy regulation can be distributionally bad when platforms offer freemium models
We present a theory of why privacy regulation can be distributionally bad when platforms offer freemium models

April 7, 2025 at 2:52 PM
#EconSky 🚨NEW PAPER with Ben Casner:
We present a theory of why privacy regulation can be distributionally bad when platforms offer freemium models
We present a theory of why privacy regulation can be distributionally bad when platforms offer freemium models
CHOOSE YOUR FIGHTER




April 4, 2025 at 6:16 PM
CHOOSE YOUR FIGHTER

What people think I'm doing when I say I'm "working on my egg paper" vs what I'm actually doing


February 14, 2025 at 4:42 PM
What people think I'm doing when I say I'm "working on my egg paper" vs what I'm actually doing



#EconSky I'll be at ASSAs next week! Feel free to hit me up if you want to drink coffee and chat research, and be sure to check out this exciting, inter-field session I organized:

December 27, 2024 at 3:11 PM
#EconSky I'll be at ASSAs next week! Feel free to hit me up if you want to drink coffee and chat research, and be sure to check out this exciting, inter-field session I organized:
If we are talking about this paper, then yes omg what a tour de force

December 1, 2024 at 9:12 PM
If we are talking about this paper, then yes omg what a tour de force
I'm mostly joking, but, ya know...

December 1, 2024 at 8:56 PM
I'm mostly joking, but, ya know...
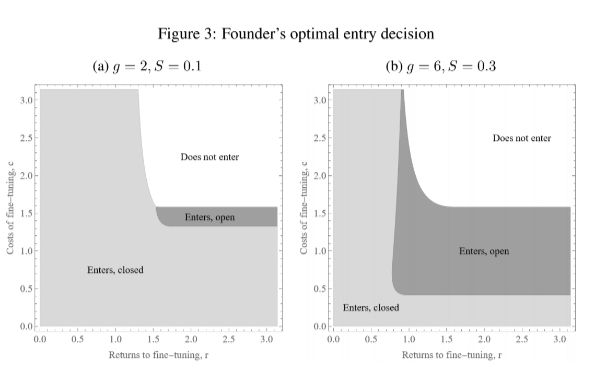
Lastly, I show that the founder may find that an open model is more profitable than a closed model in certain parameter regions, even though they can't actually sell access/inference to an open model! The idea: you get to outsource fine-tuning to an eager community of developers.
November 14, 2024 at 3:50 PM
Lastly, I show that the founder may find that an open model is more profitable than a closed model in certain parameter regions, even though they can't actually sell access/inference to an open model! The idea: you get to outsource fine-tuning to an eager community of developers.
Open AI has the “reverse Spence” distortion, where developers fine tune for their own purposes, and they like specialization more than their neighbors. There's also a countervailing "free-riding" distortion that can still lead to too little specialization!

November 14, 2024 at 3:50 PM
Open AI has the “reverse Spence” distortion, where developers fine tune for their own purposes, and they like specialization more than their neighbors. There's also a countervailing "free-riding" distortion that can still lead to too little specialization!
In the closed paradigm, the founder controls all design features of models and sells access.
I characterize equilibrium. Both open and closed yield too many models compared to social planner. But open models are often too niche while closed models are too general-purpose. Why?
I characterize equilibrium. Both open and closed yield too many models compared to social planner. But open models are often too niche while closed models are too general-purpose. Why?

November 14, 2024 at 3:50 PM
In the closed paradigm, the founder controls all design features of models and sells access.
I characterize equilibrium. Both open and closed yield too many models compared to social planner. But open models are often too niche while closed models are too general-purpose. Why?
I characterize equilibrium. Both open and closed yield too many models compared to social planner. But open models are often too niche while closed models are too general-purpose. Why?
In the open paradigm, a “founder” like Meta builds a model of endogenous quality. Then a community of developers fine tunes (by an endogenous amount and direction) & conducts inference on any model/application for free.

November 14, 2024 at 3:50 PM
In the open paradigm, a “founder” like Meta builds a model of endogenous quality. Then a community of developers fine tunes (by an endogenous amount and direction) & conducts inference on any model/application for free.
I capture the topology of models w/ the extended Salop circle from @profeski et al.: the foundation model is at the center of the circle (general purpose), while applications are on the edge (niche). Applications may be similar to or very distinct from each other.

November 14, 2024 at 3:50 PM
I capture the topology of models w/ the extended Salop circle from @profeski et al.: the foundation model is at the center of the circle (general purpose), while applications are on the edge (niche). Applications may be similar to or very distinct from each other.
Background on the production function for AI. Large companies with deep troves of data and compute build general-purpose “foundation models.” Then “applications” are built by “fine-tuning” the foundation model on additional data. Finally, models are deployed (inference).

November 14, 2024 at 3:50 PM
Background on the production function for AI. Large companies with deep troves of data and compute build general-purpose “foundation models.” Then “applications” are built by “fine-tuning” the foundation model on additional data. Finally, models are deployed (inference).
🚨 #EconSky New paper! There's been much advocacy for “open” or “open-weights” AI models. But what are the equilibrium predictions relative to closed AI or a social planner? The econ of AI is new and distinct from other software, so we need new models. That’s where I come in!

November 14, 2024 at 3:50 PM
🚨 #EconSky New paper! There's been much advocacy for “open” or “open-weights” AI models. But what are the equilibrium predictions relative to closed AI or a social planner? The econ of AI is new and distinct from other software, so we need new models. That’s where I come in!
Open AI has the “reverse Spence” distortion, where developers fine tune for their own purposes, and they like specialization more than their neighbors. There's also a countervailing "free-riding" distortion that can still lead to too little specialization!
November 14, 2024 at 3:36 PM
Open AI has the “reverse Spence” distortion, where developers fine tune for their own purposes, and they like specialization more than their neighbors. There's also a countervailing "free-riding" distortion that can still lead to too little specialization!
In the closed paradigm, the founder controls all design features of models and sells access.
I characterize equilibrium. Both open and closed yield too many models compared to social planner. But open models are often too niche while closed models are too general-purpose. Why?
I characterize equilibrium. Both open and closed yield too many models compared to social planner. But open models are often too niche while closed models are too general-purpose. Why?
November 14, 2024 at 3:36 PM
In the closed paradigm, the founder controls all design features of models and sells access.
I characterize equilibrium. Both open and closed yield too many models compared to social planner. But open models are often too niche while closed models are too general-purpose. Why?
I characterize equilibrium. Both open and closed yield too many models compared to social planner. But open models are often too niche while closed models are too general-purpose. Why?
In the open paradigm, a “founder” like Meta builds a model of endogenous quality. Then a community of developers fine tunes (by an endogenous amount and direction) & conducts inference on any model/application for free.
November 14, 2024 at 3:36 PM
In the open paradigm, a “founder” like Meta builds a model of endogenous quality. Then a community of developers fine tunes (by an endogenous amount and direction) & conducts inference on any model/application for free.
I capture the topology of models w/ the extended Salop circle from @profeski et al.: the foundation model is at the center of the circle (general purpose), while applications are on the edge (niche). Applications may be similar to or very distinct from each other.
November 14, 2024 at 3:36 PM
I capture the topology of models w/ the extended Salop circle from @profeski et al.: the foundation model is at the center of the circle (general purpose), while applications are on the edge (niche). Applications may be similar to or very distinct from each other.