


Lakshya A Agrawal
@lakshyaaagrawal.bsky.social
PhD @ucberkeleyofficial.bsky.social | Past: AI4Code Research Fellow @msftresearch.bsky.social | Summer @EPFL Scholar, CS and Applied Maths @IIITDelhi | Hobbyist Saxophonist
https://lakshyaaagrawal.github.io
Maintainer of https://aka.ms/multilspy
https://lakshyaaagrawal.github.io
Maintainer of https://aka.ms/multilspy
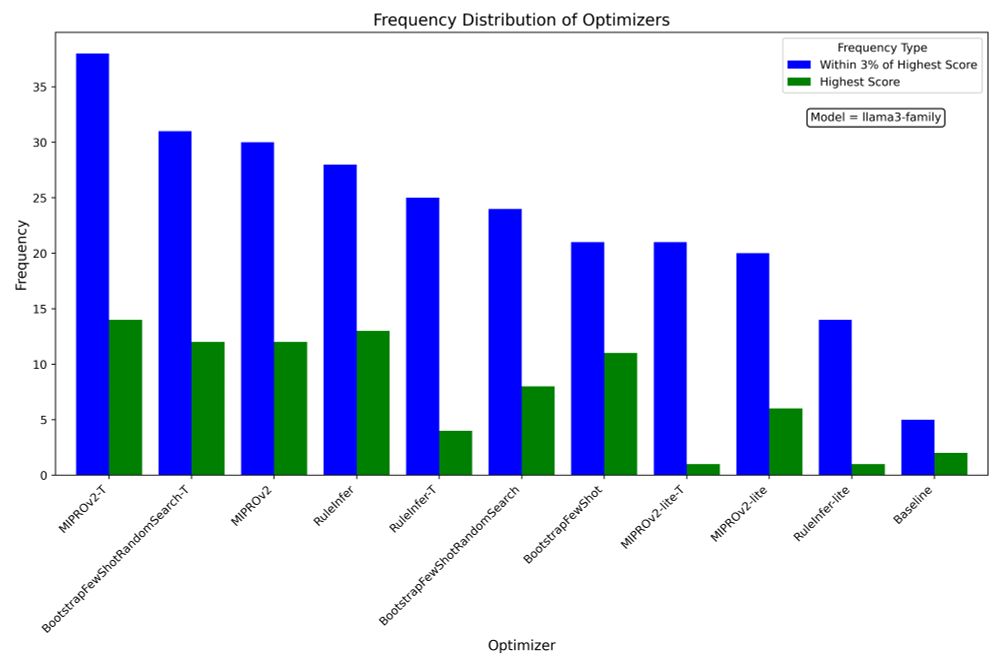
9/13: Among optimizers, MIPROv2, which constructs instructions and few-shot examples and explores their cross-module combinations through Bayesian search, performed best on avg.
But bootstrapping few-shot examples with random search and RuleInfer remains highly competitive!
But bootstrapping few-shot examples with random search and RuleInfer remains highly competitive!
March 3, 2025 at 6:59 PM
9/13: Among optimizers, MIPROv2, which constructs instructions and few-shot examples and explores their cross-module combinations through Bayesian search, performed best on avg.
But bootstrapping few-shot examples with random search and RuleInfer remains highly competitive!
But bootstrapping few-shot examples with random search and RuleInfer remains highly competitive!
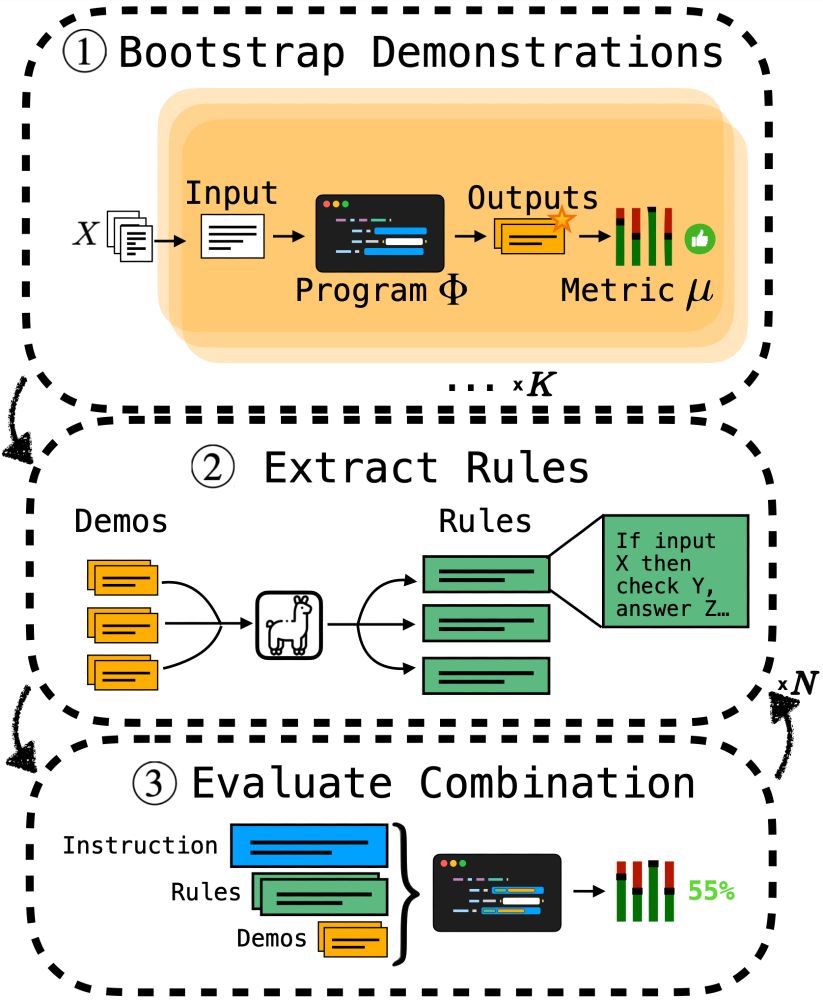
8/13: We also introduce RuleInfer, a new program-level prompt optimizer that induces rules from bootstrapped examples. RuleInfer offers particularly strong performance in tasks with clear, discrete constraints such as classification.
March 3, 2025 at 6:59 PM
8/13: We also introduce RuleInfer, a new program-level prompt optimizer that induces rules from bootstrapped examples. RuleInfer offers particularly strong performance in tasks with clear, discrete constraints such as classification.
7/13: LangProBe analyses reveals empirically that different program architectures shine in different contexts. Modular programs are essential for tasks requiring external information or tools. RAG and multi-hop retrieval excel at tasks needing long-tail world knowledge.
March 3, 2025 at 6:59 PM
7/13: LangProBe analyses reveals empirically that different program architectures shine in different contexts. Modular programs are essential for tasks requiring external information or tools. RAG and multi-hop retrieval excel at tasks needing long-tail world knowledge.
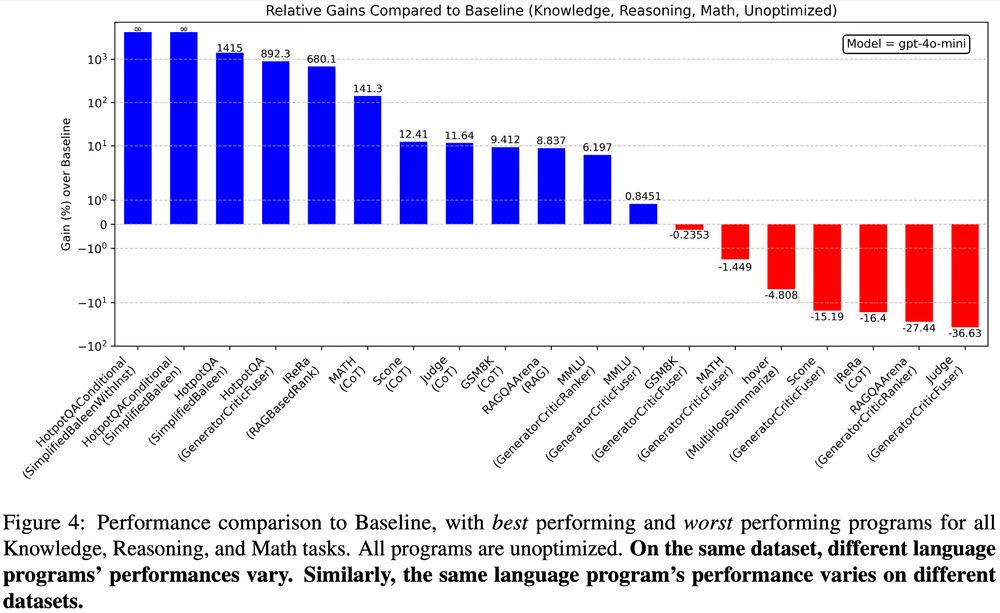
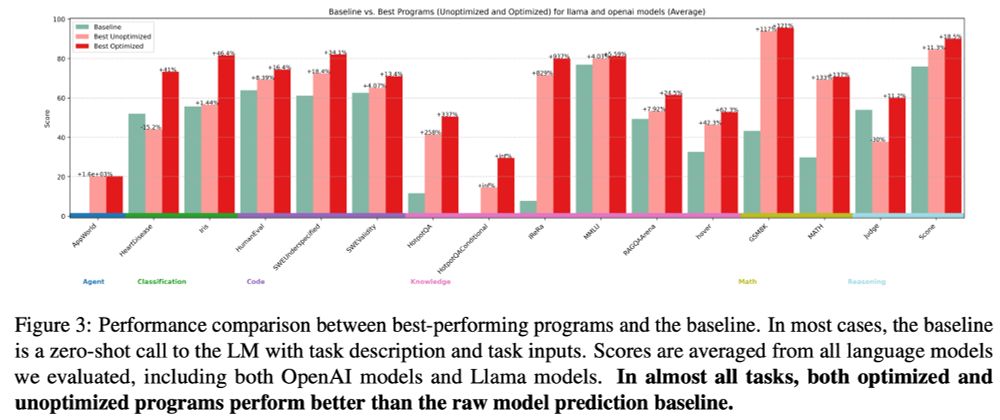
6/13: Further, in almost all tasks, both optimized and unoptimized Language Programs significantly outperform raw model predictions, even irrespective of costs:
March 3, 2025 at 6:59 PM
6/13: Further, in almost all tasks, both optimized and unoptimized Language Programs significantly outperform raw model predictions, even irrespective of costs:
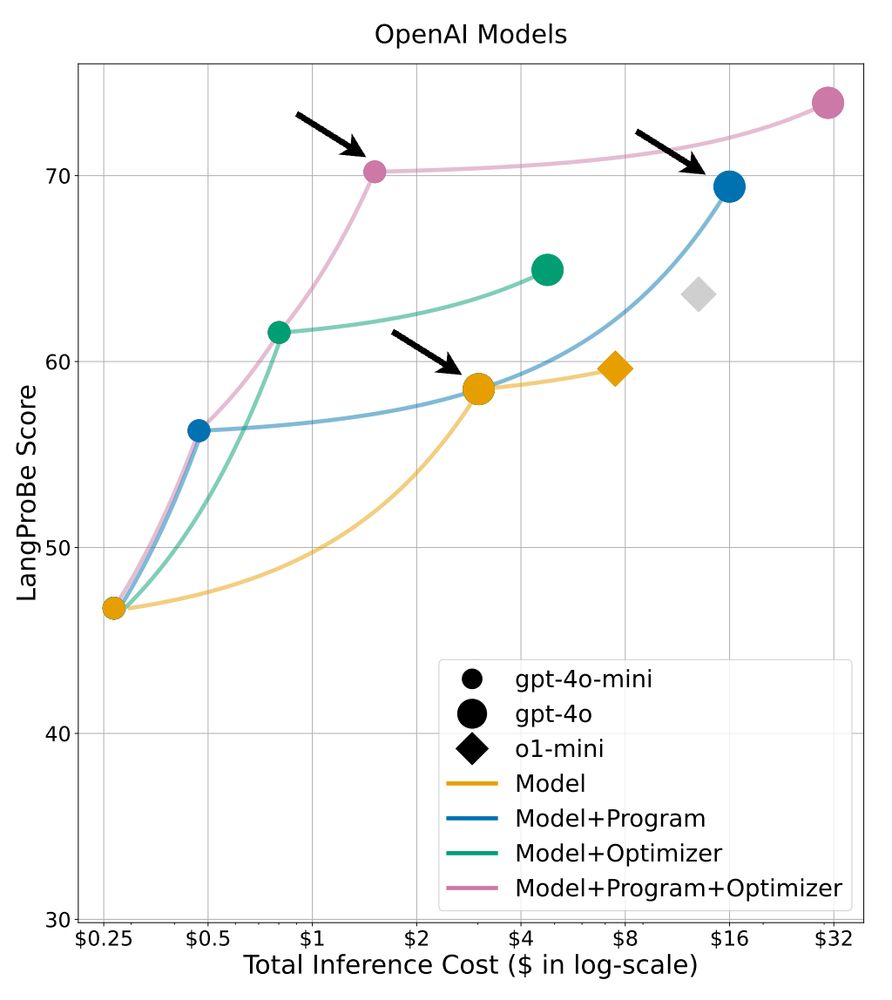
5/13: For example, gpt-4o-mini with optimized language programs achieved 11.68% higher scores than baseline gpt-4o at just 50% of the cost, and outperforms gpt-4o with programs at just 10% of the cost! This has huge implications for building cost-effective AI systems.
March 3, 2025 at 6:59 PM
5/13: For example, gpt-4o-mini with optimized language programs achieved 11.68% higher scores than baseline gpt-4o at just 50% of the cost, and outperforms gpt-4o with programs at just 10% of the cost! This has huge implications for building cost-effective AI systems.
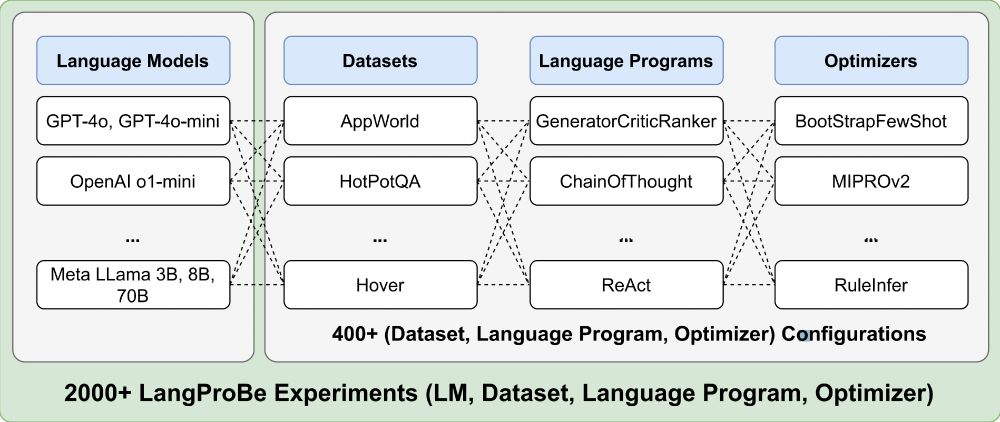
3/13: LangProBe evaluates 15+ datasets across diverse categories: coding tasks, math reasoning, classification, QA, and agent benchmarks. It implements 10+ program architectures from simple LM calls to complex modular systems with multiple reasoning and retrieval steps.
March 3, 2025 at 6:59 PM
3/13: LangProBe evaluates 15+ datasets across diverse categories: coding tasks, math reasoning, classification, QA, and agent benchmarks. It implements 10+ program architectures from simple LM calls to complex modular systems with multiple reasoning and retrieval steps.
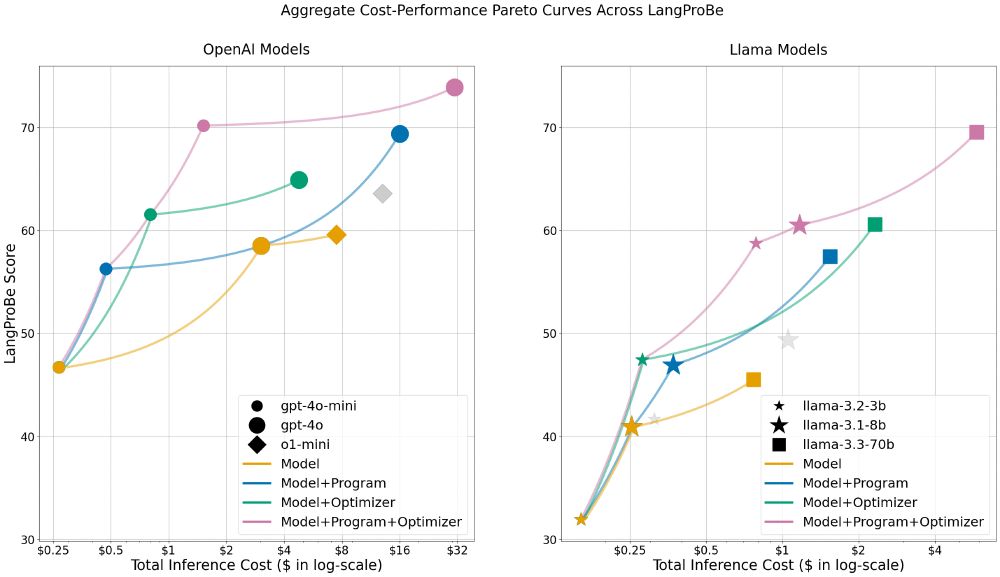
🧵Introducing LangProBe: the first benchmark testing where and how composing LLMs into language programs affects cost-quality tradeoffs!
We find that, on avg across diverse tasks, smaller models within optimized programs beat calls to larger models at a fraction of the cost.
We find that, on avg across diverse tasks, smaller models within optimized programs beat calls to larger models at a fraction of the cost.
March 3, 2025 at 6:59 PM
🧵Introducing LangProBe: the first benchmark testing where and how composing LLMs into language programs affects cost-quality tradeoffs!
We find that, on avg across diverse tasks, smaller models within optimized programs beat calls to larger models at a fraction of the cost.
We find that, on avg across diverse tasks, smaller models within optimized programs beat calls to larger models at a fraction of the cost.